💡 不断排除不存在解的区间,直至最后剩下一个 这里归纳最重要的部分: 分析题意,挖掘题目中隐含的 单调性; while (left < right) 退出循环的时候有 left == right 成立,因此无需考虑返回left还是right; 始终思考下一轮搜索区间是什么,如果是 [mid, right] 就对应 left = mid ,如果是 [left, mid 1] 就对应 right = mid 1,是保留 mid 还是 +1、−1 就在这样的思考中完成; 从一个元素什么时候不是解开始考虑下一轮搜索区间是什么 ,把区间分为 2个部分(一个部分肯定不存在目标元素,另一个部分有可能存在目标元素),问题会变得简单很多,这是一条 非常有用 的经验; 每一轮区间被划分成 2 部分,理解 区间划...

💡 GRPO相比PPO主要优势: 背景 GRPO是 DeepSeekMath model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO回顾 PPO的目标函数为: [公式] 其中: [Math] 和 [Math] 分别是当前和旧策略模型 A_t 是优势函数 [Math] 是裁剪相关的超参数 模型训练 如图1上所示,PPO需要同时训练一个Value Model [Math] 和策略模型, 同时需要reference model(通常从SFT model初始化)来限制策略模型训练保持和reference model的行为接近,而 Reward model用来计算...
Large Model
2026-01-11

概述 投机解码(Speculative Decoding)也叫预测解码/投机采样,它会利用小模型来预测大型模型的行为,从而提升模型在解码(decoding)阶段的解码效率问题,加速大型模型的执行。其核心思路如下图所示,首先以低成本的方式(以小模型为主,也有多头,检索,Early Exit 等方式)快速生成多个候选 Token(串行序列、树、多头树等),然后通过一次并行验证阶段快速验证多个 Token的正确性,只要平均每个 Step 验证的 Token 数 1,就可以一次性生成多个token,进而减少总的 Decoding 步数,实现加速的目的。 下图左侧是自回归解码模型,右侧是投机解码机制。 从本质上来说,投机解码希望在推理阶段在不大幅度改变模型的情况下,通过更好利用冗余算力来并行"投机"地...
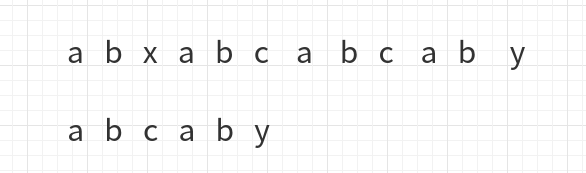
kmp算法用于字符串的模式匹配,也就是找到模式字符串在目标字符串的第一次出现的位置比如abababc那么bab在其位置1处,bc在其位置5处,我们首先想到的最简单的办法就是蛮力的一个字符一个字符的匹配,但那样的时间复杂度会是O(mn)。kmp算法保证了时间复杂度为O(m+n)。 基本原理 举个例子: 发现x与c不同后,进行移动 a与x不同,再次移动 此时比较到了c与y, 于是下一步移动成了下面这样 这一次的移动与前两次的移动不同,之前每次比较到上面长字符串的字符位置后,直接把模式字符串的首字符与它对齐,这次并没有,原因是这次移动之前,y与c对齐,但是y前边的ab是与自己的前缀ab一样,于是ab并不用再比较,直接从第三个位置开始比较,如图: 所以说kmp算法对于这种情况就直接使用当前比较字符之...
Reinforcement Learning
2026-01-11
引言 大语言模型(LLMs)在近年来取得了显著进展,展现出上下文学习、指令跟随和逐步推理等突出特性。然而,由于这些模型是在包含高质量和低质量数据的预训练语料库上训练的,它们可能会表现出编造事实、生成有偏见或有毒文本等意外行为。因此,将LLMs与人类价值观对齐变得至关重要,特别是在帮助性、诚实性和无害性(3H)方面。 基于人类反馈的强化学习(RLHF)已被验证为有效的对齐方法,但训练过程复杂且不稳定。本文深入分析了RLHF框架,特别是PPO算法的内部工作原理,并提出了PPOmax算法,以提高策略模型训练的稳定性和效果。 RLHF的基本框架 RLHF训练过程包括三个主要阶段: 1. 监督微调(SFT):模型通过模仿人类标注的对话示例来学习一般的人类对话方式, 优化模型的指令跟随能力 1. 奖励模...
Algorithm
2026-01-11
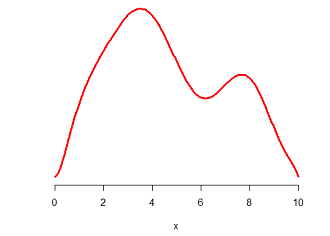
题意 给定平面上一个圆的圆心位置和半径,从圆中以均匀的概率随机选取点。 分析 拒绝取样 其实我的第一反应是用拒绝取样(Rejection Sampling)的思路来做:首先从这个圆的与坐标轴平行的外切正方形中均匀随机选取点,然后判断点是否位于圆中;如果不在,重新生成一个新的点,再次进行判断;否则直接返回。 直觉上来说,拒绝取样显然是正确的;不过我们可以用一种稍微更加形式化的方法来描述。(以下内容参考了拒绝采样(reject sampling)的简单认识,非常直观形象。) 下图是一个随机变量的密度函数曲线,试问如何获得这个随机变量的样本呢? 如果你像我一样,已经把概率论与数理统计统统还给数学老师了,那么提示一下,概率密度函数(PDF)是累积分布函数(CDF)的导数,反映的是概率的“密集程度”。...
Algorithm
2026-01-11
根据一棵树的先序遍历和中序遍历,或者后序遍历和中序遍历序列,都可以唯一地确定一棵树。 树中的节点,分为度为0,1,2的结点。如果树中只有一个节点,那么可以唯一确定一棵树,即只有一个节点的树。 当树中结点个数大于等于2的情况,树中的叶子结点和它的父亲结点中,至少有一种存在如下的情况。(为方便起见,我们先从叶子节点入手) case 1: case2: case 3: A D F / \ / \ B C E G 即,叶子结点的父亲有两个孩子,只有左孩子,只有右孩子的情况。我们只需要证明,如果树存在这三种结构中的哪一种,可以唯一确定一棵树,什么情况下又不能唯一确定一棵树呢? 1. case 1: A / \ B C 前序遍历: ABC, 后序遍历: BCA 现在,我们根据遍历序列,看看能否得到另一种...
Reinforcement Learning
2026-01-11
强化学习基础 改进算法 LLM中的RL
Large Model
2026-01-11
比起两年前,NLG任务已经得到了非常有效的发展,transformers模块的使用广泛程度也达到前所未有的程度。在模型推理预测时,一个核心的语句就是model.generate(),本文就来详细介绍一下generate方法是如何运作的。在生成的过程中,包含了诸多生成策略,本文将以最常用的beam search为例,尽可能详细地展开介绍。 随着各种LLM的出现,transformers中与generate相关的代码发生了一些变化,主要区别在于: generate的源码位置发生了改变; generate方法中,采用一个generation_config参数来管理生成相关的各种配置,并优化了逻辑,使得逻辑更加清晰。 1. generate的代码位置 在之前版本的transformers中(tran...
Reinforcement Learning
2026-01-11
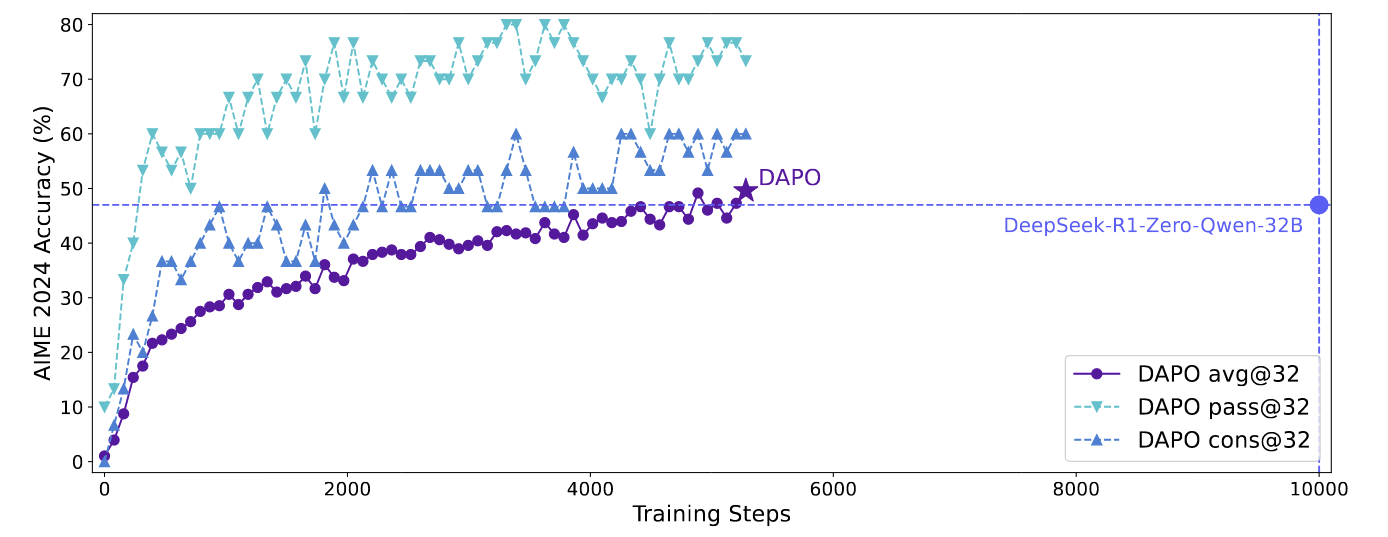
回顾 PPO [公式] 其中 (q, a) 是 数据集 [Math] 中采样的 questionanswer pair, [Math] 是重要性采样比的clip范围, [Math] 是时间步 t 的优势估计量. 给定 value function V 和 reward function R , [Math] 使用广义优势估计 (GAE) 来计算: [公式] 其中, [公式] GRPO 相比于 PPO, GRPO 去掉了value function 并以分组的方式估计优势。对于特定的问答对 (q, a), behavior policy [Math] 生成了一组 G 个 response \{o...