Computer Vision
2026-01-11
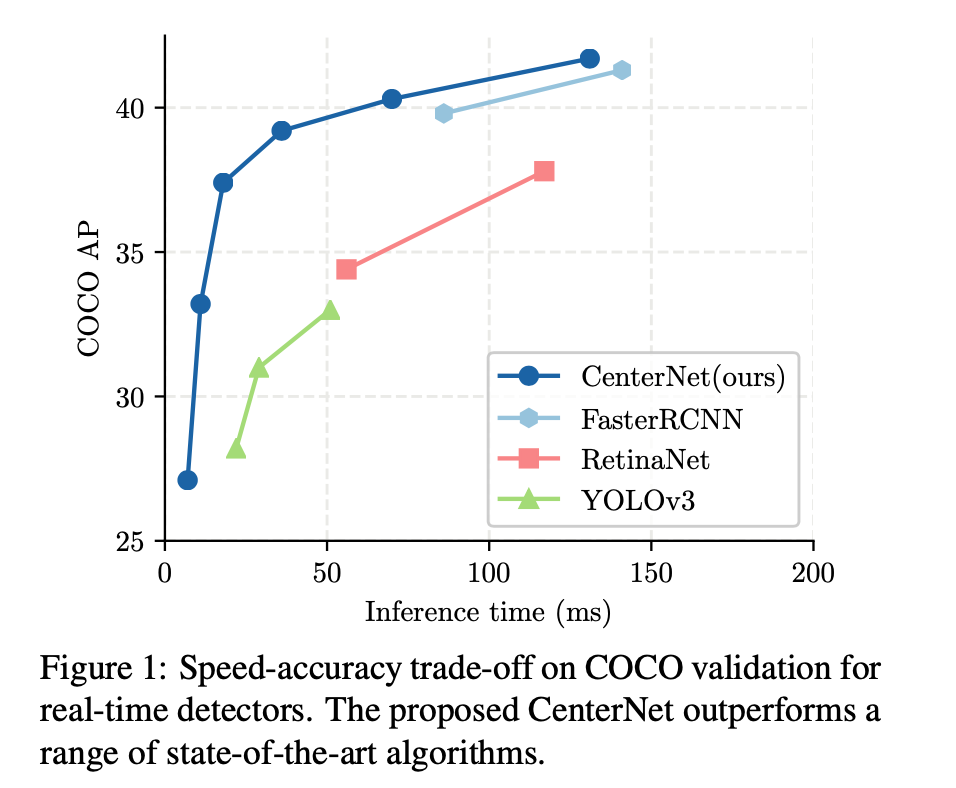
前言 anchorfree目标检测属于anchorfree系列的目标检测,相比于CornerNet做出了改进,使得检测速度和精度相比于onestage和twostage的框架都有不小的提高,尤其是与YOLOv3作比较,在相同速度的条件下,CenterNet的精度比YOLOv3提高了4个左右的点。 CenterNet不仅可以用于目标检测,还可以用于其他的一些任务,如肢体识别或者3D目标检测等等。 那CenterNet相比于之前的onestage和twostage的目标检测有什么特点? CenterNet的“anchor”仅仅会出现在当前目标的位置处而不是整张图上撒,所以也没有所谓的box overlap大于多少多少的算positive anchor这一说,也不需要区分这个anchor是物体还是...