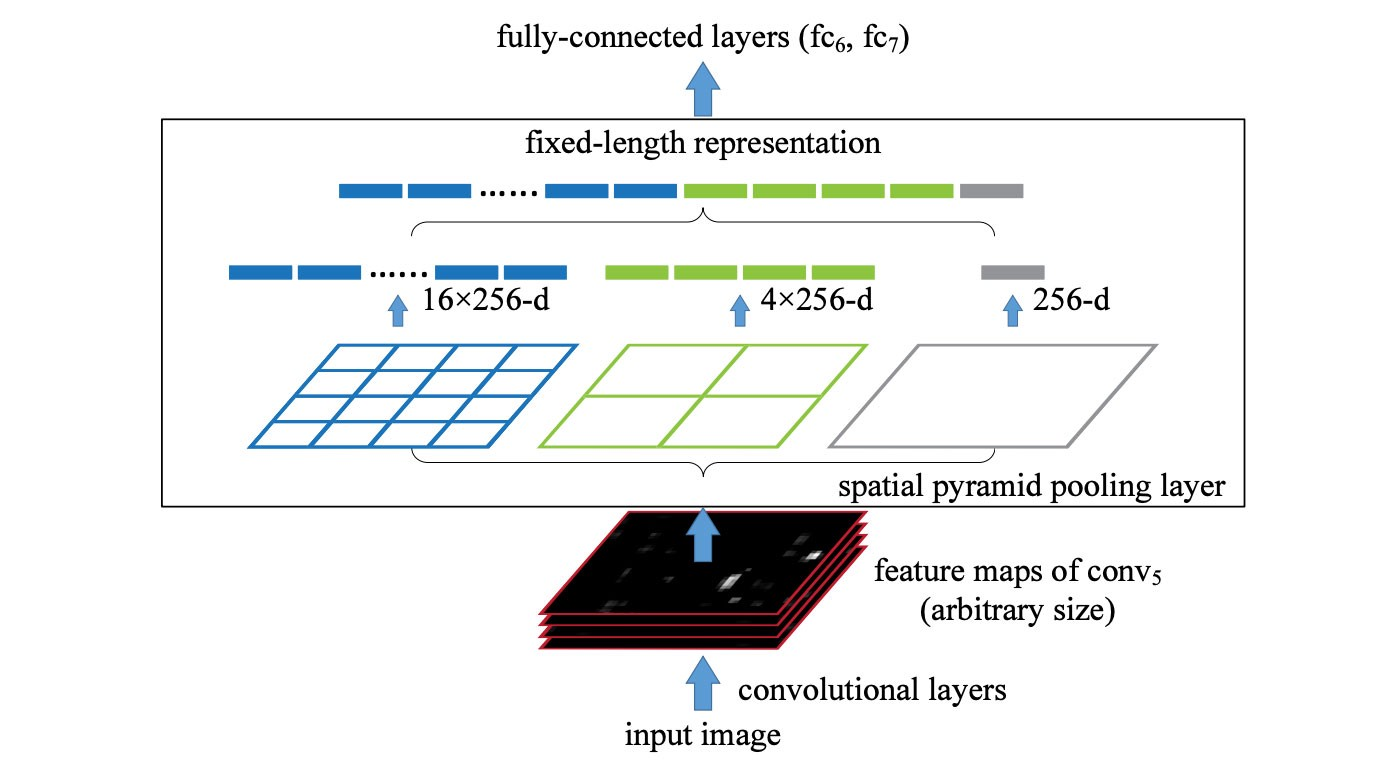
Large Model
2026-01-11
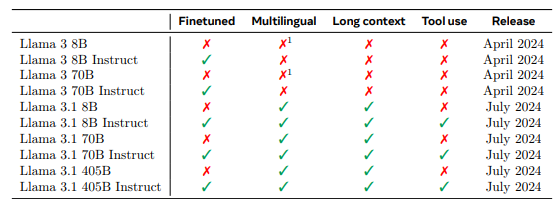
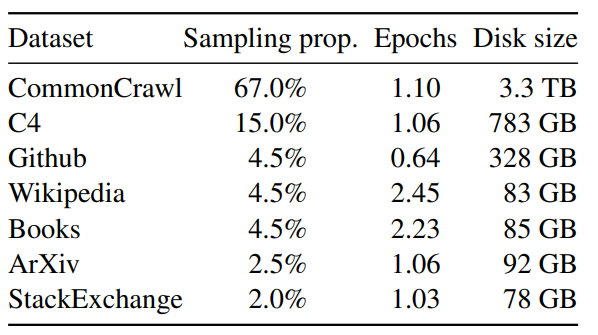
LLaMA 一直致力于LLM模型研究的国外TOP 3大厂除了OpenAI、Google,便是Meta(原来的Facebook) Meta曾第一个发布了基于LLM的聊天机器人——BlenderBot 3,但输出不够安全,很快下线;再后来,Meta发布一个专门为科学研究设计的模型Galactica,但用户期望过高,发布三天后又下线 23年2.24日,Meta通过论文《LLaMA: Open and Efficient Foundation Language Models》发布了自家的大型语言模型LLaMA,有多个参数规模的版本(7B 13B 33B 65B),并于次月3.8日被迫开源 LLaMA只使用公开的数据(总计1.4T即1,400GB的token,其中CommonCrawl的数据占比67%...