Computer Vision
2026-01-11
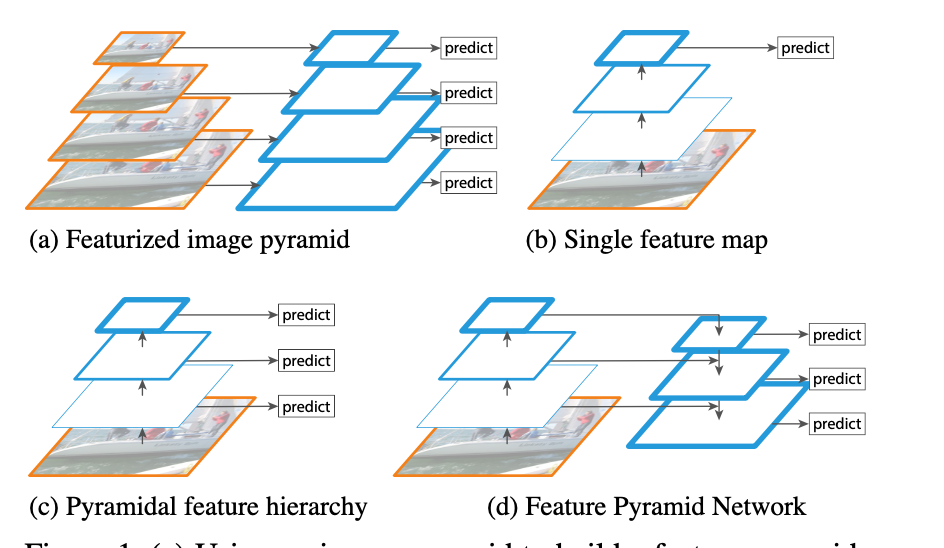
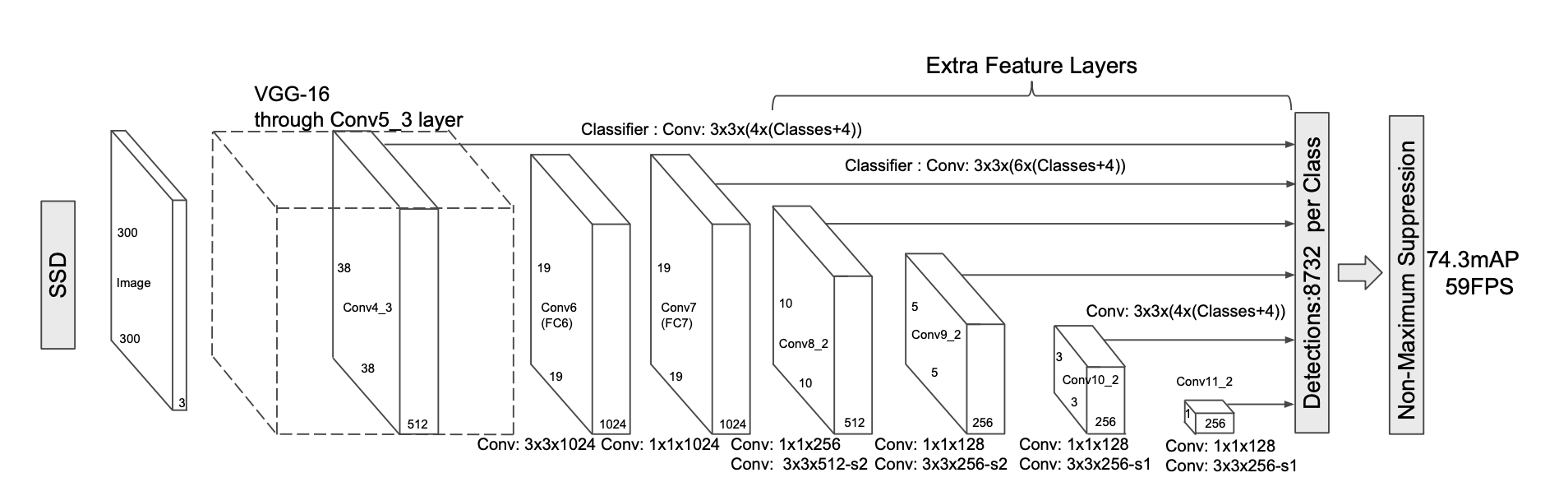
FPN 1.结构区别 (a)图片金字塔生成特征金字塔:缩放图片比例 (b)通常的CNN网络结构 (c)多尺度特征融合的方式:像SSD(Single Shot Detector)就是采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的。 (d)FPN:这是本文要讲的网络,FPN主要解决的是物体检测中的多尺度问题,通过简单的网络连接改变,在基本不增加原有模型计算量的情况下,大幅度提升了小物体检测的性能。通过高层特征进行上采样和低层特征进行自顶向下的连接,而且每一层都会进行预测。 2....