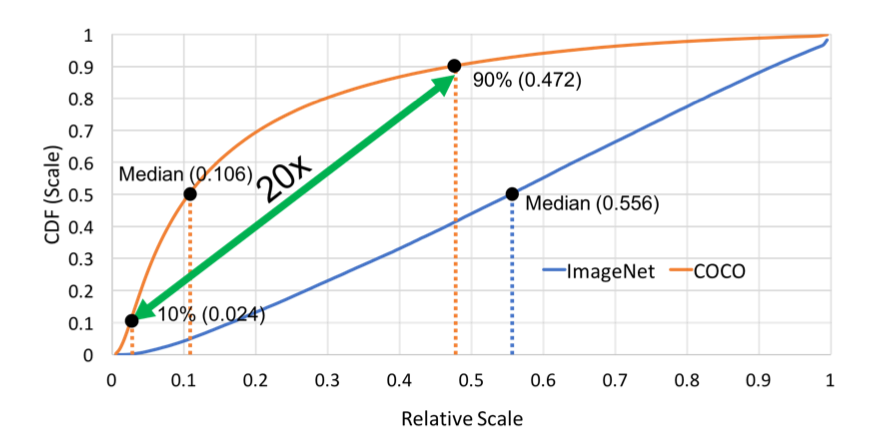
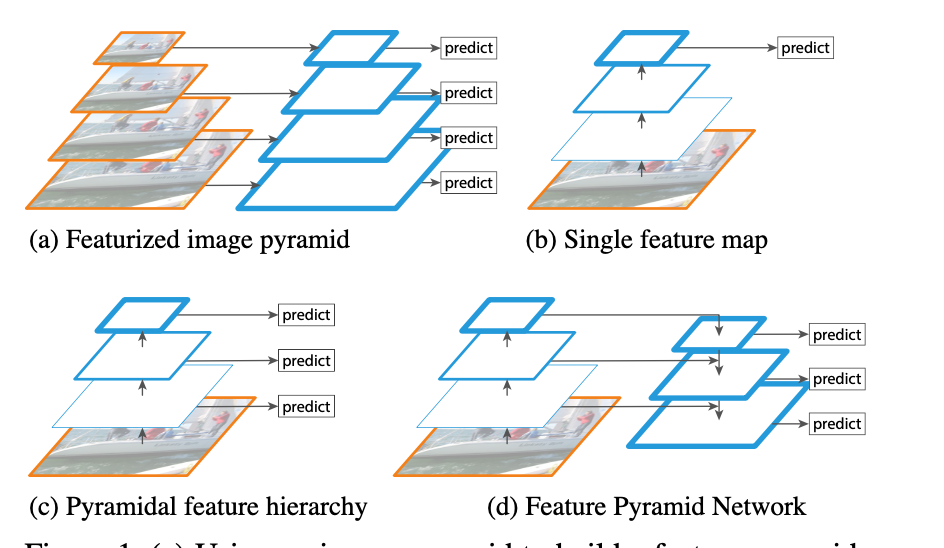
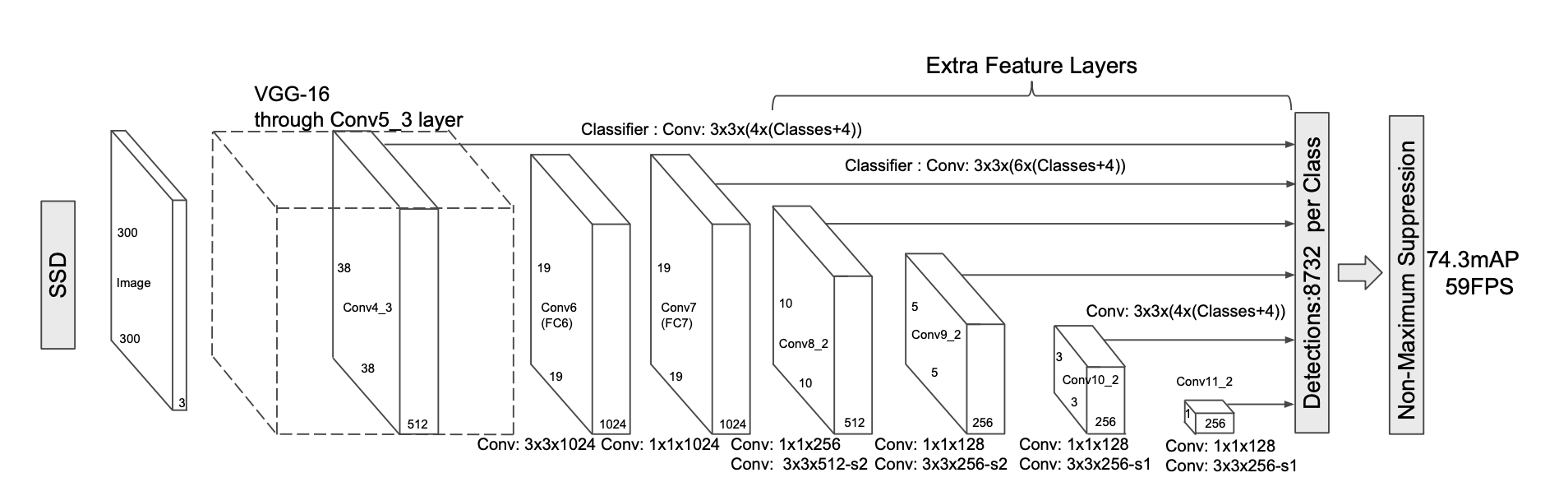
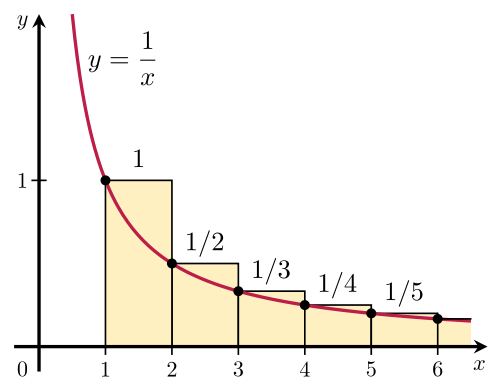
Algorithm
2026-01-11
题目 给定一个无序的数组,找出数组在排序之后,相邻元素之间最大的差值。 如果数组元素个数小于 2,则返回 0。 Example 1: [代码] 解题思路:如果进行排序,这里会超时。采用桶排序 排序算法 的思想,可以在线性时间解决。 1. 首先建立桶,每个桶中只需要存放这个桶中元素的最大值和最小值。 1. 我们期望将数组中的各个数等距离分配,也就是每个桶的长度相同,也就是对于所有桶来说,桶内最大值减去桶内最小值都是一样的。可以当成公式来记。 1. 确定桶的数量,最后的加一保证了数组的最大值也能分到一个桶。为什么需要这样规定桶的尺寸呢?因为这样可以让最大的间距的两个元素在两个不同的桶中。可以证明一下,因为我们用元素范围之差除以元素个数,所以桶的尺寸就是平均的元素间距,显然最大间距的两个元素不可能...