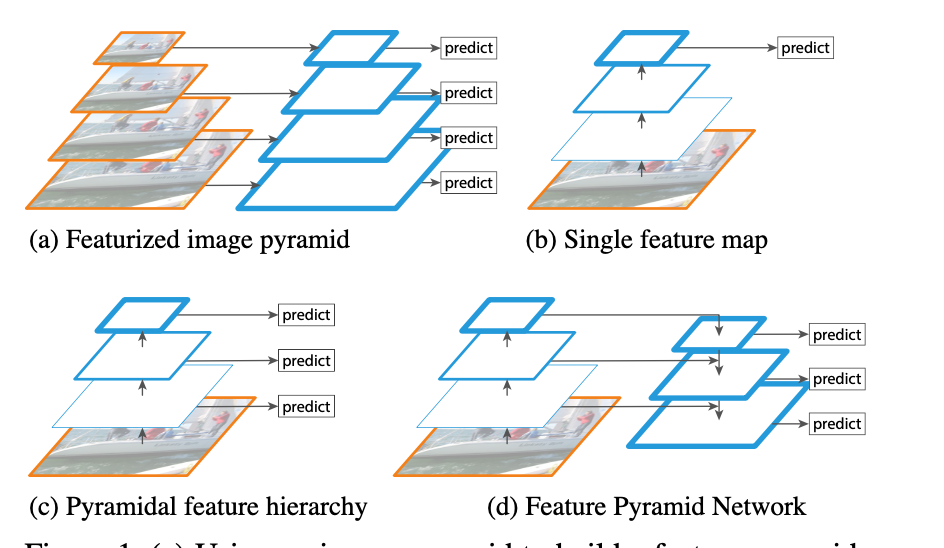
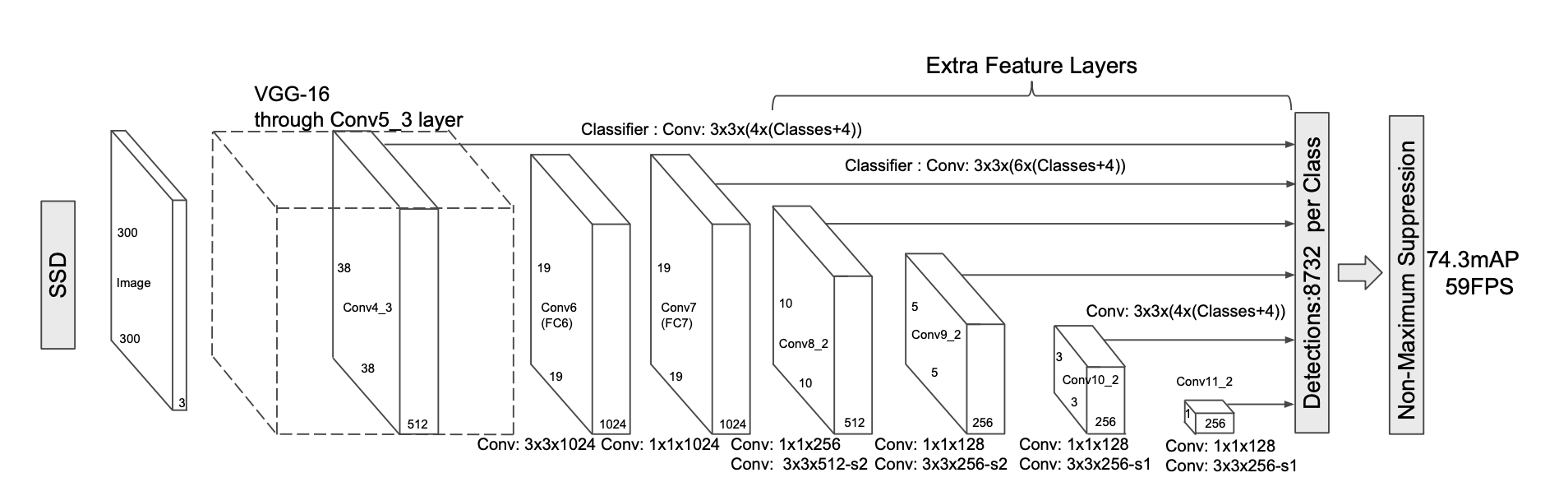
Computer Vision
2026-01-11
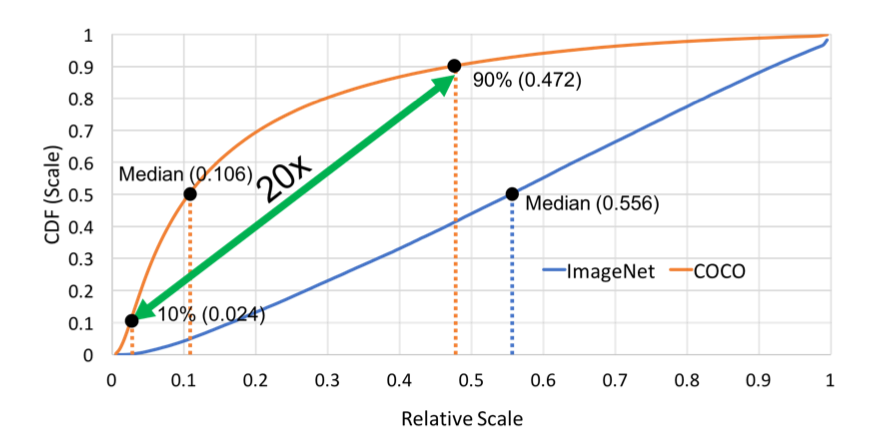
1. 检测任务的困难 图像分类算法,比如ResNeXt101 32 × 48d网络结构,在Imagenet数据集上的Top5准确率已经98%左右,Top1为85%。对于图像检测算法,最好的模型在coco数据集上的效果 AP_{50} 为62%,显然,总体上来看,准确率差了20个点左右,那么问题来了,为什么检测算法比识别算法的效果低这么多呢? 1.1 尺度差异 作者认为原因在于,检测任务中的目标存在较大的尺度变化(large scale variation)。作者统计了Imagenet和COCO数据集的特点,如下图, 其中,横坐标表示目标相对于原图的比例,纵坐标表示累计分布(cumulation distribution function)。显然,由图中可以看出,COCO数据集中50%的目标相...