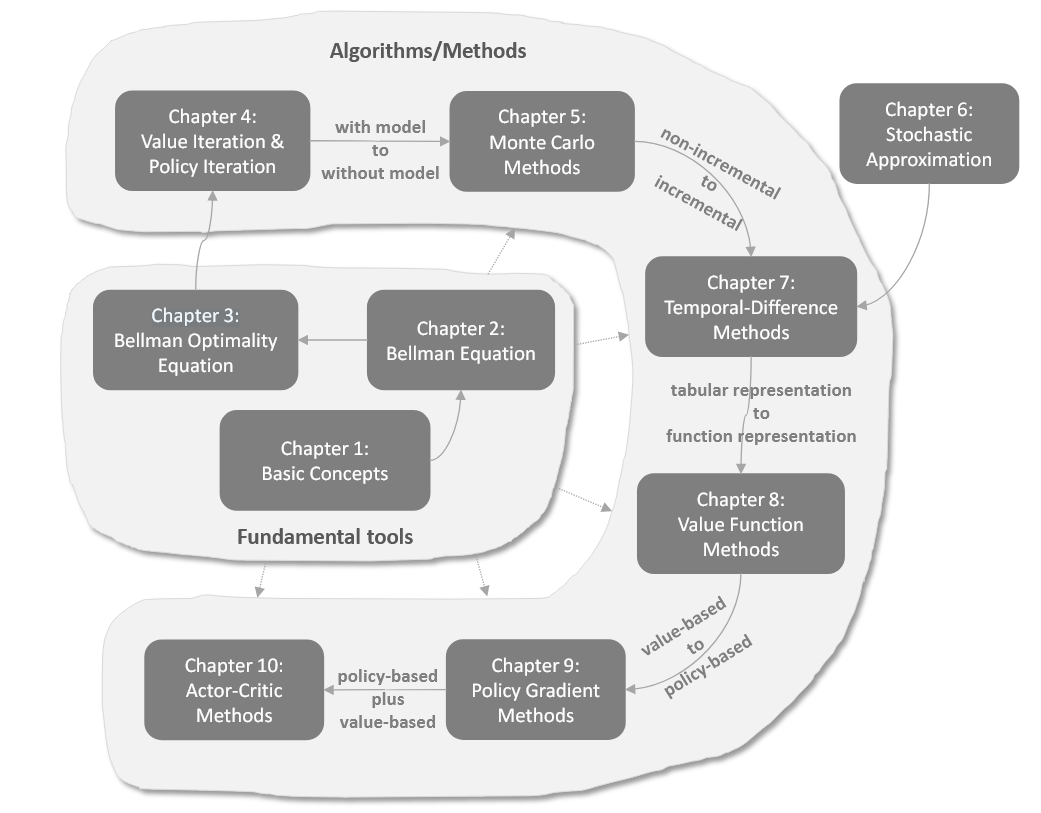
Reinforce Learning 概述 Reinforcement Learning 2026-01-11 强化学习基础 改进算法 LLM中的RL #Reinforcement Learning READ
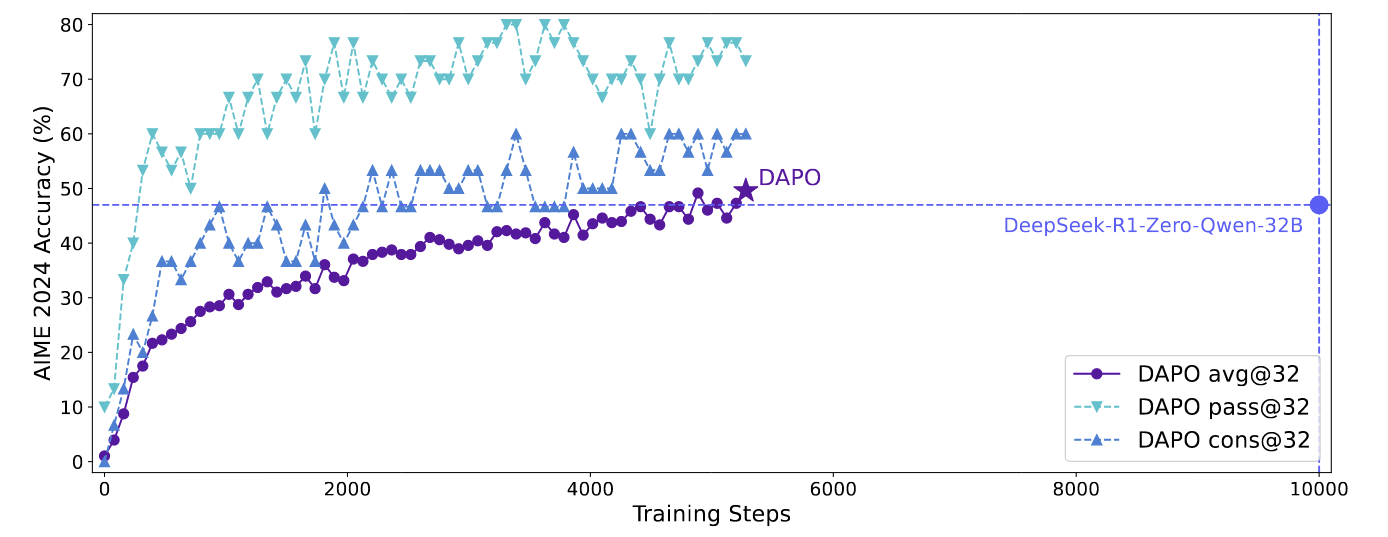
从GRPO到GSPO、DAPO Reinforcement Learning 2026-01-11 回顾 PPO [公式] 其中 (q, a) 是 数据集 [Math] 中采样的 questionanswer pair, [Math] 是重要性采样比的clip范围, [Math] 是时间步 t 的优势估计量. 给定 value function V 和 reward function R , [Math] 使用广义优势估计 (GAE) 来计算: [公式] 其中, [公式] GRPO 相比于 PPO, GRPO 去掉了value function 并以分组的方式估计优势。对于特定的问答对 (q, a), behavior policy [Math] 生成了一组 G 个 response \{o... #Reinforcement Learning #Large Model READ
CV-正则化方法 Deep Learning 2026-01-11 DropBlock 论文题目:DropBlock: A regularization method for convolutional networks 论文地址:https://arxiv.org/abs/1810.12890 由于dropBlock其实是dropout在卷积层上的推广,故很有必须先说明下dropout操作。 dropout,训练阶段在每个minibatch中,依概率P随机屏蔽掉一部分神经元,只训练保留下来的神经元对应的参数,屏蔽掉的神经元梯度为0,参数不参数与更新。而测试阶段则又让所有神经元都参与计算。 dropout操作流程:参数是丢弃率p 1)在训练阶段,每个minibatch中,按照伯努利概率分布(采样得到0或者1的向量,0表示丢弃)随机的丢弃一部分神经元(即神经元... #CV #DL基础 READ