Computer Vision
2026-01-11

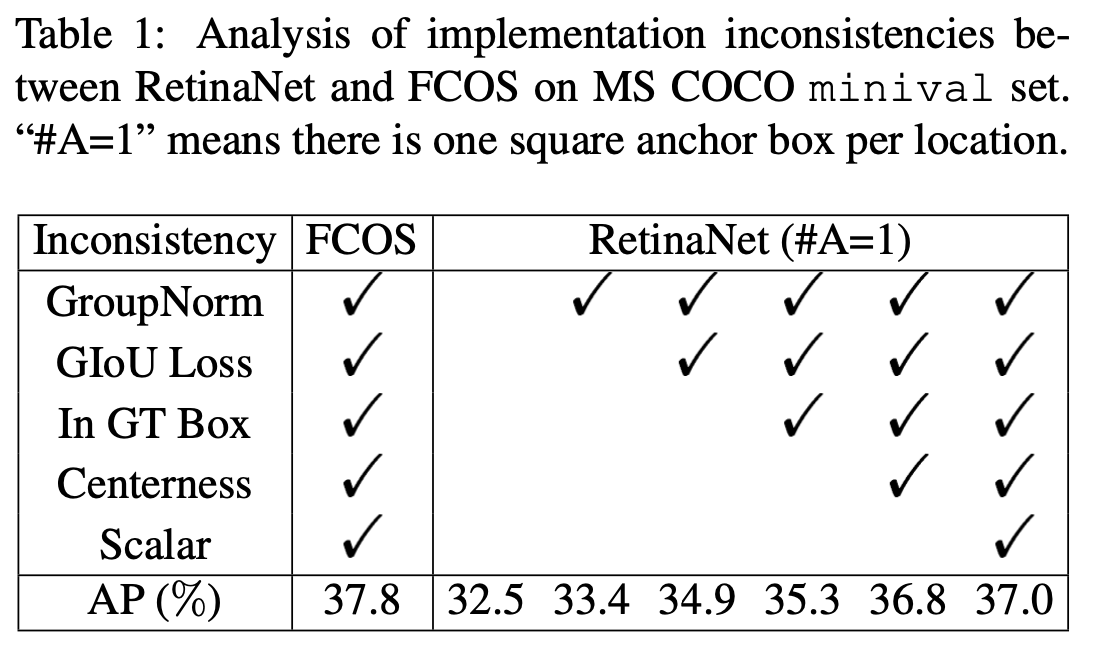
SNIPER的关键是减少了SNIP的计算量。SNIP借鉴了multiscale training的思想进行训练,multiscale training是用图像金字塔作为模型的输入,这种做法虽然能够提高模型效果,但是计算量的增加也非常明显,因为模型需要处理每个scale图像的每个像素,而SNIPER(Scale Normalization for Image Pyramids with Efficient Resampling)算法以适当的比例处理ground truth(称为chips)周围的上下文区域,在训练期间每个图像生成的chips的数量会根据场景复杂度而自适应地变化,由于SNIPER在采样后的低分辨率的chips上运行,故其可以在训练期间收益于Batch Normalization,...