Reinforcement Learning
2026-01-11

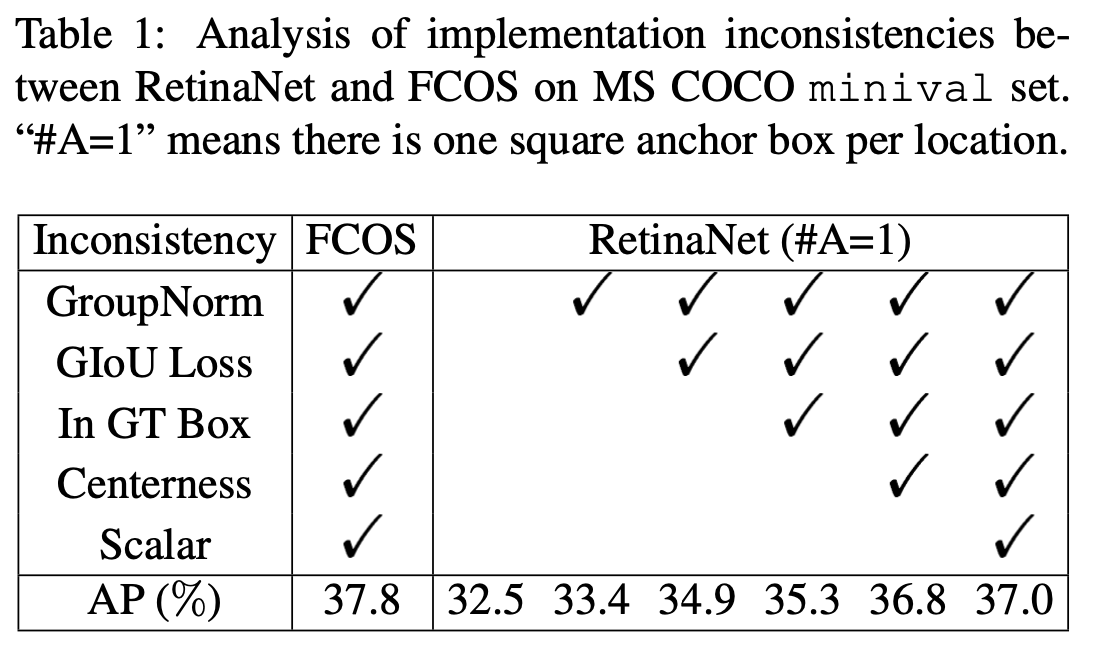
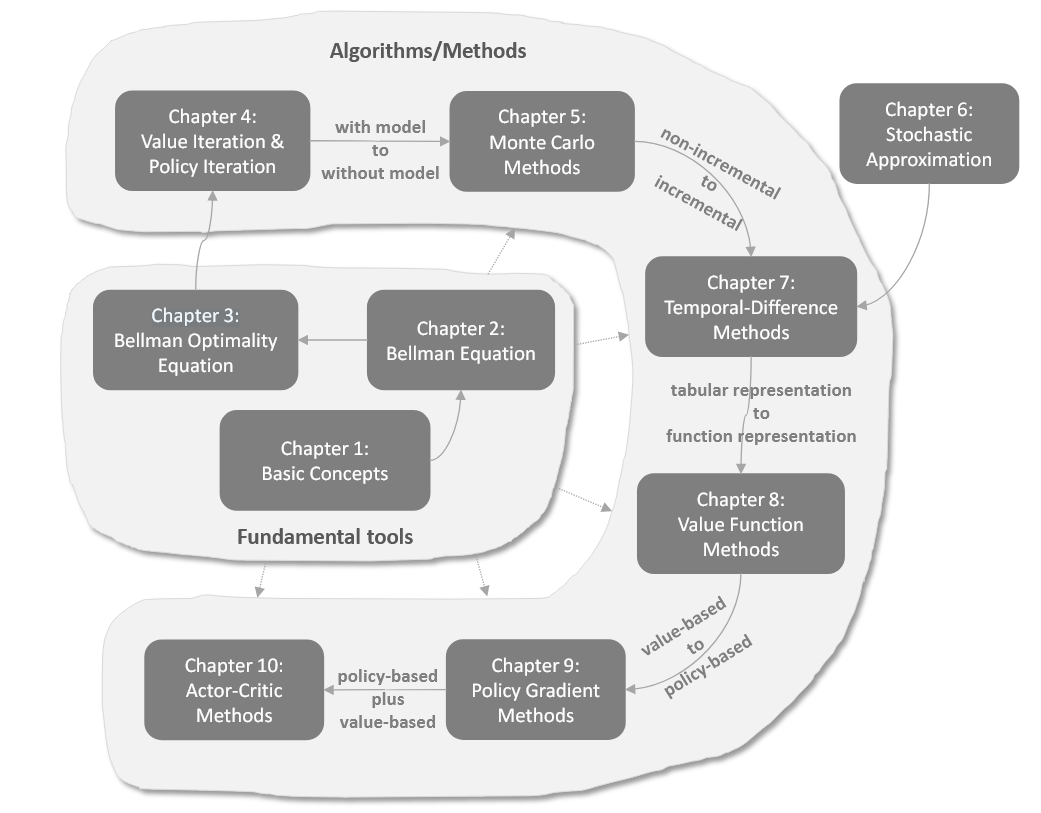
引言 强化学习中,找到最优策略是核心目标。本文详细介绍三种能够找到最优策略的基础算法:价值迭代、策略迭代和截断策略迭代。这些算法属于动态规划范畴,需要系统模型,是后续无模型强化学习算法的重要基础。 在强化学习的发展路线中,这些算法处于"基础工具"到"算法/方法"的过渡阶段,是从"有模型"到"无模型"学习的重要桥梁。 价值迭代(Value iteration) 价值迭代算法基于收缩映射定理求解贝尔曼最优方程。其核心迭代公式为: [公式] 根据收缩映射定理,当 [Math] 时, v_k 和 [Math] 分别收敛到最优状态值和最优策略。 每次迭代包含两个步骤: 1. 策略更新步骤 (policy update step):找到能解决以下优化问题的策略 1. 价值更新步骤(value updat...