Reinforce Learning 概述 Reinforcement Learning 2026-01-11 强化学习基础 改进算法 LLM中的RL #Reinforcement Learning READ
Deformable DETR Computer Vision 2026-01-11 Deformable Convolution 在正式介绍这个工作之前很有必要先了解什么是 Deformable Convolution 。 Deformable Convolution 是MSRA的代季峰老师以及实习生在2017年提出的一种全新的卷积结构。这种方法将固定形状的卷积过程改造成了能适应物体形状的可变的卷积过程,从而使结构适应物体形变的能力更强。 传统的CNN只能靠一些简单的方法(比如max pooling)来适应物体的形变,如果形变的太厉害就无能为力了。因为CNN的卷积核的geometric structure是fixed的,也就是固定住的。卷积核总是在固定位置对输入特征特征进行采样。 为了改变这种情况专家们想了很多方法,最常见的有两种: 1. 使用大量的数据进行训练。比如用Im... #CV #Object Detection #transformer READ
transformers中generate方法 Large Model 2026-01-11 比起两年前,NLG任务已经得到了非常有效的发展,transformers模块的使用广泛程度也达到前所未有的程度。在模型推理预测时,一个核心的语句就是model.generate(),本文就来详细介绍一下generate方法是如何运作的。在生成的过程中,包含了诸多生成策略,本文将以最常用的beam search为例,尽可能详细地展开介绍。 随着各种LLM的出现,transformers中与generate相关的代码发生了一些变化,主要区别在于: generate的源码位置发生了改变; generate方法中,采用一个generation_config参数来管理生成相关的各种配置,并优化了逻辑,使得逻辑更加清晰。 1. generate的代码位置 在之前版本的transformers中(tran... #LLM #transformer READ
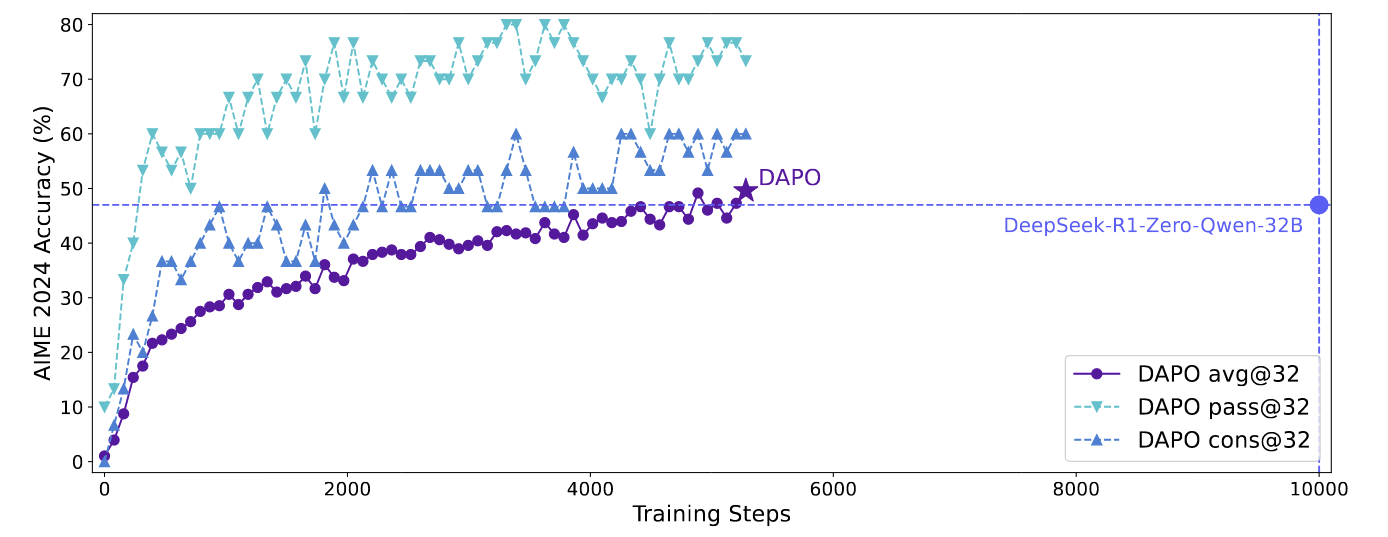
从GRPO到GSPO、DAPO Reinforcement Learning 2026-01-11 回顾 PPO [公式] 其中 (q, a) 是 数据集 [Math] 中采样的 questionanswer pair, [Math] 是重要性采样比的clip范围, [Math] 是时间步 t 的优势估计量. 给定 value function V 和 reward function R , [Math] 使用广义优势估计 (GAE) 来计算: [公式] 其中, [公式] GRPO 相比于 PPO, GRPO 去掉了value function 并以分组的方式估计优势。对于特定的问答对 (q, a), behavior policy [Math] 生成了一组 G 个 response \{o... #Reinforcement Learning #Large Model READ