
160. 相交链表 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交 : 题目数据 保证 整个链式结构中不存在环。 注意 ,函数返回结果后,链表必须 保持其原始结构 。 自定义评测: 评测系统 的输入如下(你设计的程序 不适用 此输入): intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0 listA - 第一个链表 listB - 第二个链表 skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数 skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数 评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。 示例 1: 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2,...
Large Model
2026-01-23

总览 由于是“图文多模态”,还是要从“图”和“文”的表征方法讲起,然后讲清楚图文表征的融合方法。这里只讲两件事情: 视觉表征 :分为两个部分问题,一是如何合理建模视觉输入特征,二是如何通过预训练手段进行充分学习表征,这两点是基于视觉完成具体算法任务的基础; 视觉与自然语言的对齐(Visul Language Alignment)或融合 :目的是将视觉和自然语言建模到同一表征空间并进行融合,实现自然语言和视觉语义的互通,这点同样离不开预训练这一过程。模态对齐是处理多模态问题的基础,也是现在流行的多模态大模型技术前提。 对于视觉表征,从发展上可以分为卷积神经网络(CNN)和Vision Transformer(VIT)两大脉络,二者分别都有各自的表征、预训练以及多模态对齐的发展过程。而对于VIT线,另有多模态大模型如火如荼的发展,可谓日新月异。 CNN:视觉理解的一代先驱 点击展开 卷积视觉表征模型和预训练...
Computer Vision
2026-01-21
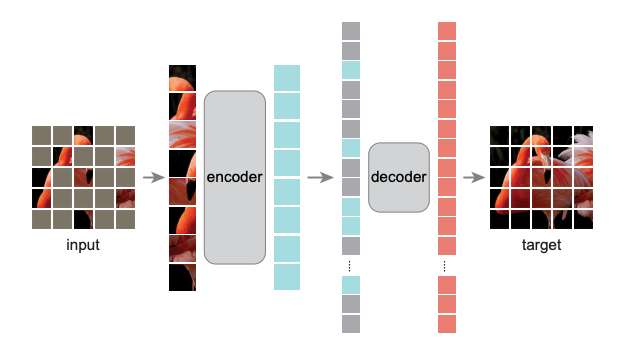
导言 自监督学习(Self-Supervised Learning)能利用大量无标注的数据进行表征学习,然后在特定下游任务上对参数进行微调。通过这样的方式,能够在较少有标注数据上取得优于有监督学习方法的精度。近年来,自监督学习受到了越来越多的关注,如Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。在CV领域涌现了如SwAV、MOCO、DINO、MoBY等一系列工作。MAE是kaiming继MOCO之后在自监督学习领域的又一力作。首先,本文会对MAE进行解读,然后基于EasyCV库的精度复现过程及其中遇到的一些问题作出解答。 概述 MAE的做法很简单:随机mask掉图片中的一些patch,然后通过模型去重建这些丢失的区域。包括两个核心的设计:1.非对称编码-解码结构 2.用较高的掩码率(75%)。通过这两个设计MAE在预训练过程中可以取得3倍以上的训练速度和更高的精度,如ViT-Huge能够通过ImageNet-1K数据上取得87.8%的准确率。 模型拆解...
Computer Vision
2026-01-21
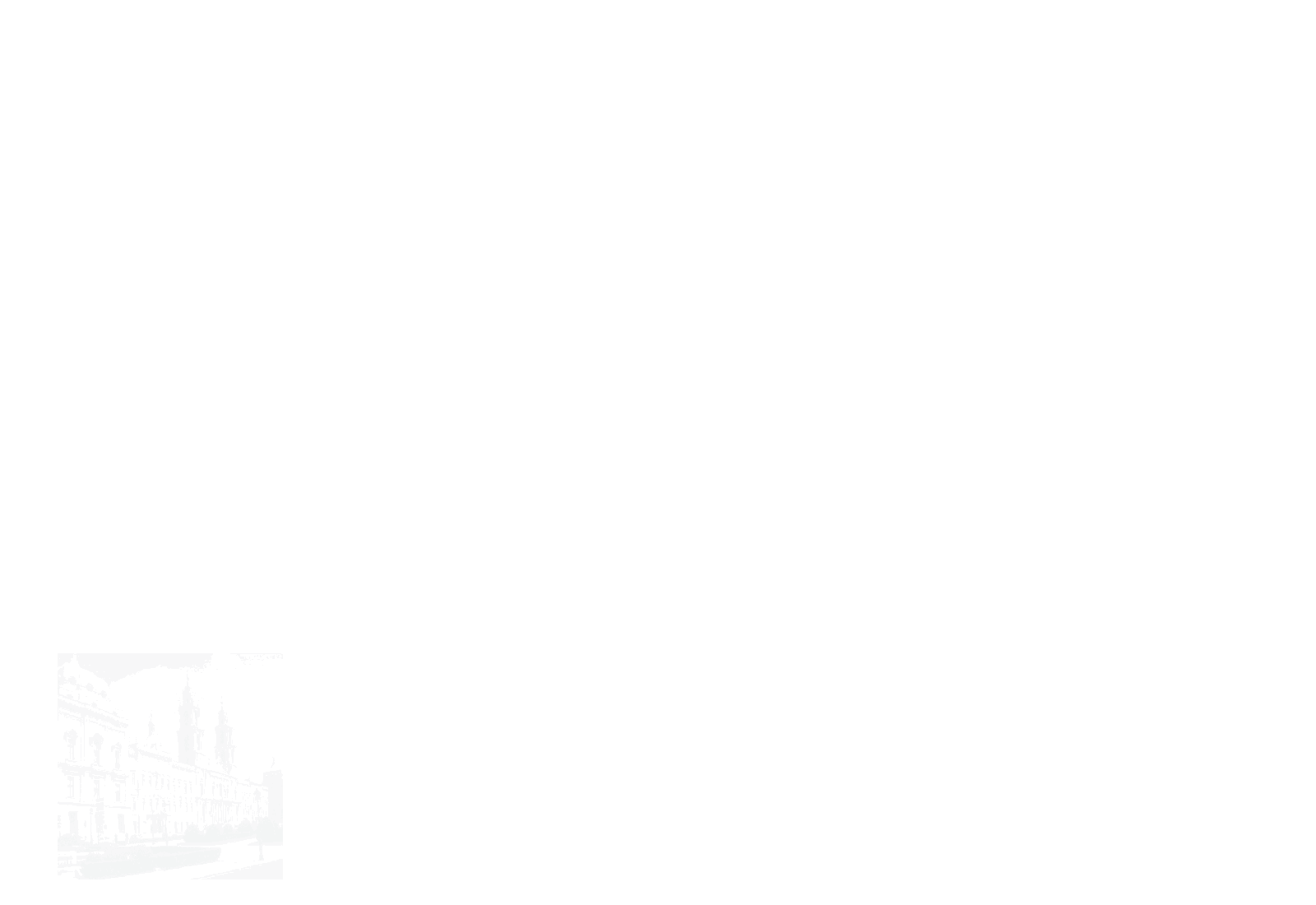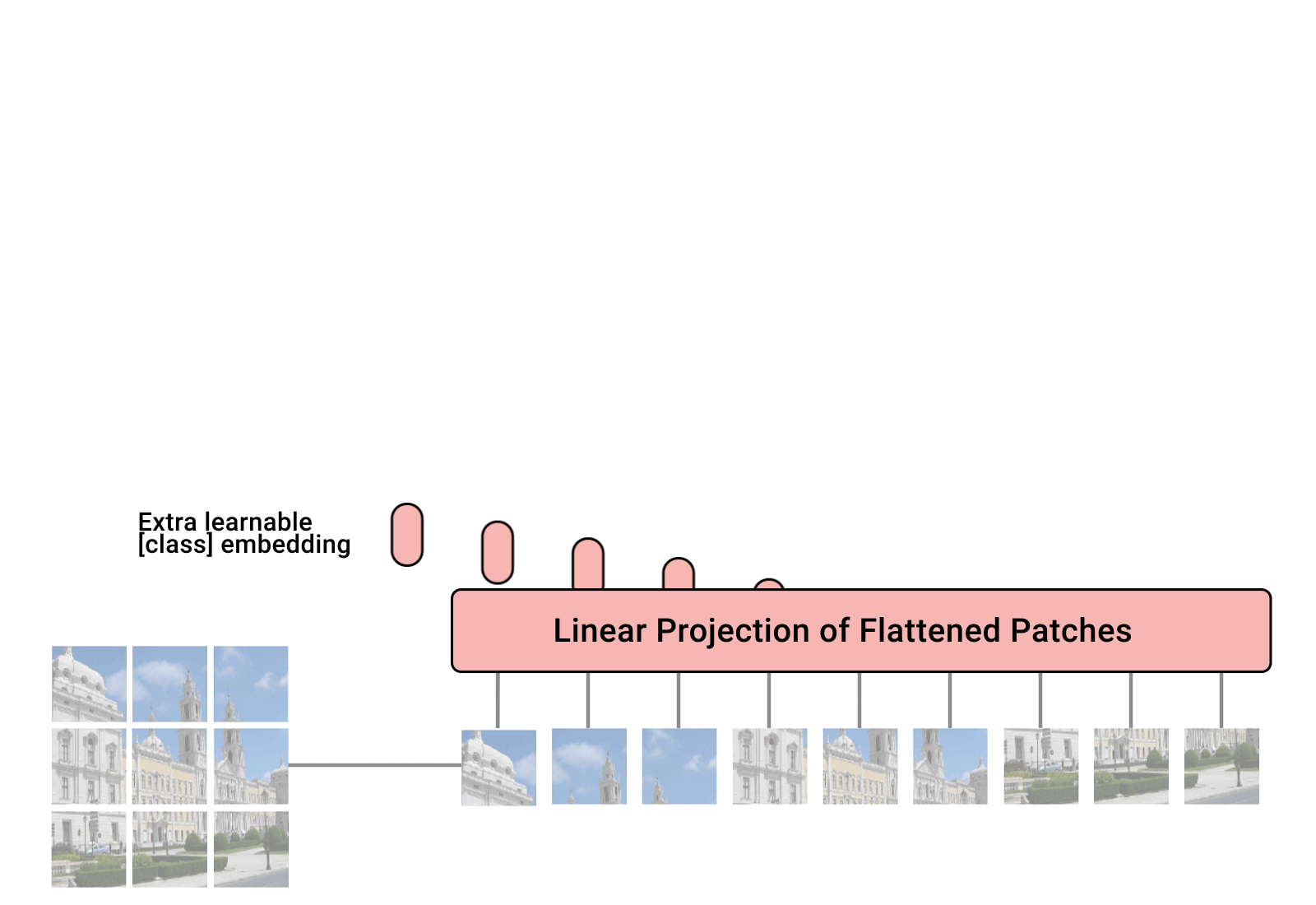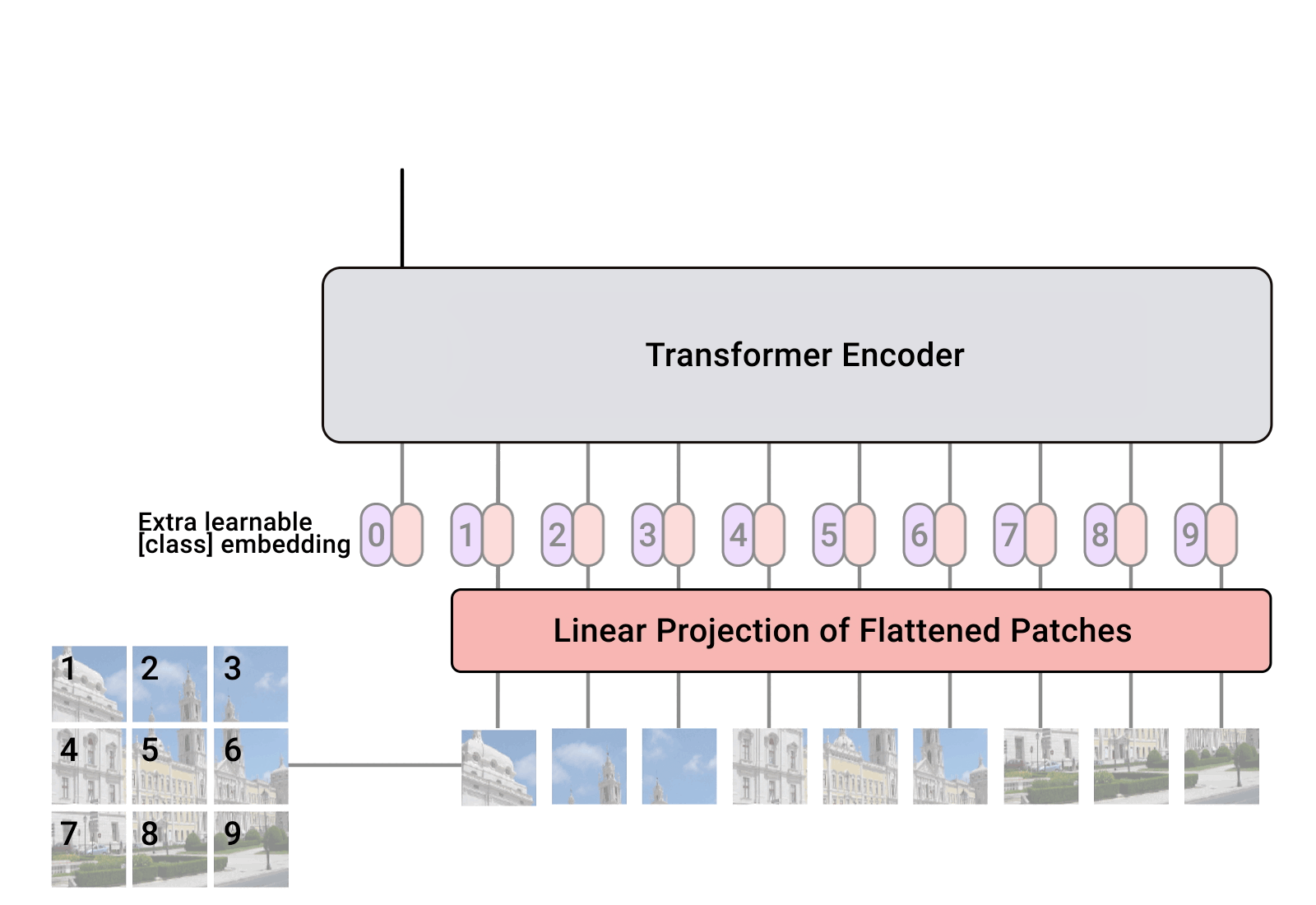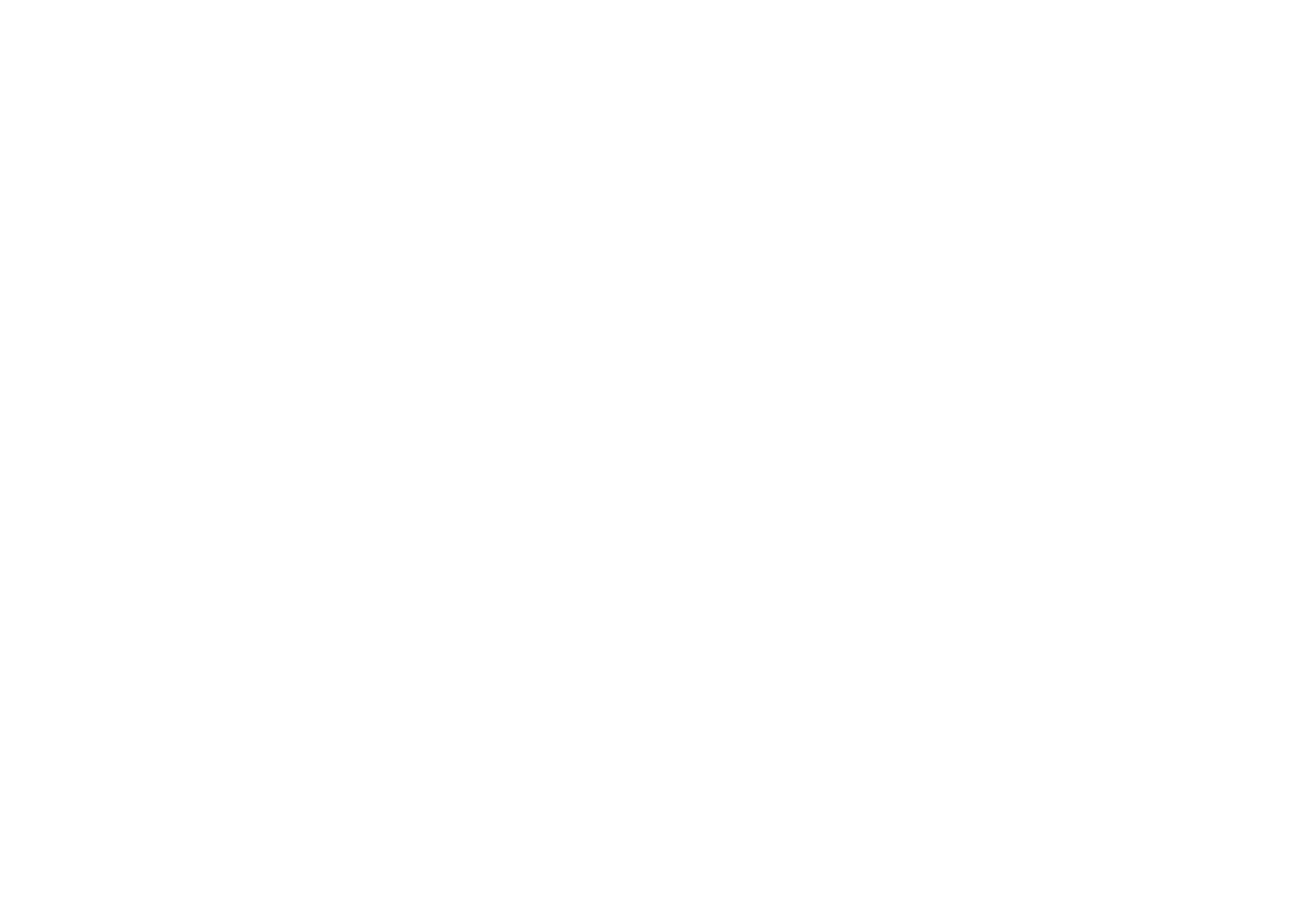
概述 在计算机视觉领域(CV),对视觉特征的理解CNN是长期处于主导地位的。而在NLP领域,Transformer框架的巨大成功,也激发了不少研究者探索将Transformer用于计算机视觉任务。ViT(Vision Transformer)的出现标志着在CV领域Transformer架构迈出了重要的一步。尤其在当前结合LLM的多模态探索上(MM-LLM),都是以LLM大语言模型为骨干架构的模型,多种模态的信息需要先做token化处理,再输入到LLM模型。ViT天然具有序列化特征的建模能力,自然在MM-LLM探索中大放异彩~ ViT在多模态模型中的角色类似于自然语言建模中的Tokenizer组件,对图像进行视觉特征编码,产出图像的序列特征。只不过ViT的编码过程本身也是采用了Transformer的模型结构。 本文主要结合几篇paper和源码讲讲ViT和针对ViT的一些优化方法~ ViT(Vision Transformer)...
Computer Vision
2026-01-21
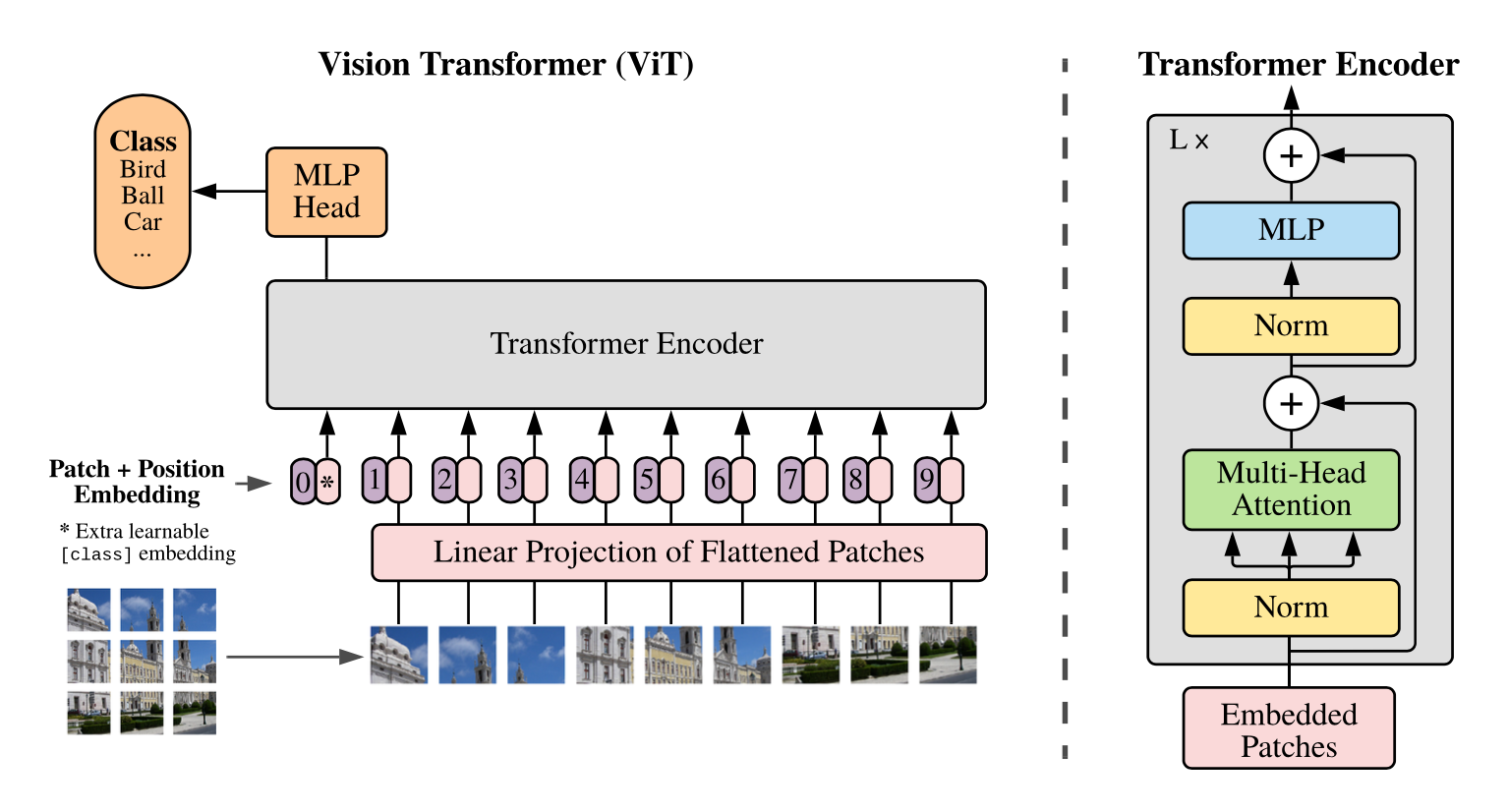
ViT(vision transformer)是Google在2020年提出的直接将transformer应用在图像分类的模型,后面很多的工作都是基于ViT进行改进的。ViT的思路很简单:直接把图像分成固定大小的patchs,然后通过线性变换得到patch embedding,这就类比NLP的words和word embedding,由于transformer的输入就是a sequence of token embeddings,所以将图像的patch embeddings送入transformer后就能够进行特征提取从而分类了。ViT模型原理如下图所示,其实ViT模型只是用了transformer的Encoder来提取特征(原始的transformer还有decoder部分,用于实现sequence to sequence,比如机器翻译)。下面将分别对各个部分做详细的介绍。 Patch Embedding 对于ViT来说,首先要将原始的2-D图像转换成一系列1-D的patch embeddings,这就好似NLP中的word embedding。输入的2-D图像记为 \(x\in...
Generative Model
2026-01-19

💡 扩散模型:通过加噪的方式去学习原始数据的分布, 从学到的分布中去生成样本 DDPM 关键点: 1. 正向加噪是离散时间马尔可夫链:从 \(x_0\) 逐步加噪得到 \(x_1,x_2,...,x_T\) ;在合适的噪声调度与足够大的 \(T\) 下, \(x_T\) 近似服从 \( N(0,I) \) 的各向同性高斯。 2. 每一步噪声方差 \(β_t\) 满足 \(0<β_t<1\) ,通常随 \(t\) 增大;因此 \(q(x_t|x_{t-1}) \) 的均值缩放系数 \(\sqrt{1-β_t} \) 逐渐减小。 3. 训练通过最大化对数似然的变分下界(ELBO)来学习反向过程 \( p_θ(x_{t-1}|x_t)\) ,并将其参数化为高斯分布(神经网络预测均值/噪声或 score)。 4. 将目标写成 score/DSM 形式时,loss 的权重与对应噪声层的方差尺度(如 \(1-\bar{α}_t\) 或相关量)有关;采样通常是按学习到的反向转移逐步生成(祖先采样),与经典 Langevin MCMC 更新形式不同,但可在 SDE 视角下统一理解。...
Generative Model
2026-01-18

2022年中旬,以扩散模型为核心的图像生成模型将AI绘画带入了大众的视野。实际上,在更早的一年之前,就有了一个能根据文字生成高清图片的模型——VQGAN。VQGAN不仅本身具有强大的图像生成能力,更是传承了前作VQVAE把图像压缩成离散编码的思想,推广了「先压缩,再生成」的两阶段图像生成思路,启发了无数后续工作。 VQGAN 核心思想 VQGAN的论文名为 Taming Transformers for High-Resolution Image Synthesis,直译过来是「驯服Transformer模型以实现高清图像合成」。可以看出,该方法是在用Transformer生成图像。可是,为什么这个模型叫做VQGAN,是一个GAN呢?这是因为,VQGAN使用了两阶段的图像生成方法: 训练时,先训练一个图像压缩模型(包括编码器和解码器两个子模型),再训练一个生成压缩图像的模型。 生成时, 先用第二个模型生成出一个压缩图像,再用第一个模型复原成真实图像 。 其中,第一个图像压缩模型叫做VQGAN,第二个压缩图像生成模型是一个基于Transformer的模型。...

简介 生成对抗网络 ( Generative Adversarial Network, GAN ) 是由 Goodfellow 于 2014 年提出的一种对抗网络。这个网络框架包含两个部分,一个生成模型 (generative model) 和一个判别模型 (discriminative model)。其中,生成模型可以理解为一个伪造者,试图通过构造假的数据骗过判别模型的甄别;判别模型可以理解为一个警察,尽可能甄别数据是来自于真实样本还是伪造者构造的假数据。两个模型都通过不断的学习提高自己的能力,即生成模型希望生成更真的假数据骗过判别模型,而判别模型希望能学习如何更准确的识别生成模型的假数据。 网络框架 GAN 由两部分构成,一个 生成器 ( Generator ) 和一个 判别器 ( Discriminator )。对于生成器,我们需要学习关于数据 \(x\) 的一个分布 \(p_g\) ,首先定义一个输入数据的先验分布 \(p_z(z)\) ,其次定义一个映射 \(G \left(\boldsymbol{z}; \theta_g\right): \boldsymbol{z}...
Generative Model
2026-01-18

分布变换 通常我们会拿VAE跟GAN比较,的确,它们两个的目标基本是一致的——希望构建一个从隐变量 \(Z\) 生成目标数据 \(X\) 的模型,但是实现上有所不同。更准确地讲,它们是假设了 \(Z\) 服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型 \(X=g(Z)\) ,这个模型能够将原来的概率分布映射到训练集的概率分布,也就是说,它们的目的都是进行分布之间的变换。 生成模型的难题就是判断生成分布与真实分布的相似度,因为我们只知道两者的采样结果,不知道它们的分布表达式 那现在假设 \(Z\) 服从标准的正态分布,那么我就可以从中采样得到若干个 \(Z_1, Z_2, \dots, Z_n\) ,然后对它做变换得到 \(\hat{X}_1 = g(Z_1),\hat{X}_2 = g(Z_2),\dots,\hat{X}_n = g(Z_n)\) ,我们怎么判断这个通过 \(g\)...
Generative Model
2026-01-18

研究对象与基本设定 我们希望学习一个能够“生成数据”的概率模型。假设我们有一个数据集 \(D\) ,每个样本是 \(n\) 维二值向量: \(x \in \{0,1\}^n\) 我们的目标是用一个参数化分布 \(p_\theta(x)\) 去逼近真实数据分布 \(p_{\text{data}}(x)\) ,并最终能够: 密度估计 :给定 \(x\) 计算 \(p_\theta(x)\) 或 \(\log p_\theta(x)\) 采样生成 :从 \(p_\theta(x)\) 采样得到新的 \(x\) 表示:链式法则与自回归分解 链式法则分解联合分布 任意联合分布都可用概率链式法则分解为条件概率的乘积: \[p(x) = \prod_{i=1}^{n} p(x_i \mid x_1, x_2, \dots, x_{i-1}) = \prod_{i=1}^{n} p(x_i \mid x_{<i})\] 其中: \(x_{<i} = [x_1, x_2, \dots, x_{i-1}]\) ,这意味着:只要我们能为每个维度 \(i\) 学好一个条件分布 \(p(x_i \mid...
Computer Vision
2026-01-11
PA Pixel Accuracy(PA,像素精度):这是最简单的度量,为标记正确的像素占总像素的比例。 [公式] 图像中共有k+1(包含背景)类, p_{ii} 表示将第i类分成第 i 类的像素数量(正确分类的像素数量), p_{ij} 表示将第 i 类分成第 j 类的像素数量(所有像素数量) 因此该比值表示正确分类的像素数量占总像素数量的比例。 优点:简单 缺点:如果图像中大面积是背景,而目标较小,即使将整个图片预测为背景,也会有很高的PA得分,因此该指标不适用于评价以小目标为主的图像分割效果。 MPA Mean Pixel Accuracy(MPA,均像素精度):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。 [公式] MIoU Mean Interse...
Generative Model
2026-01-11

ControlNet应该算是2023年文生图领域最重要的工作,它让文生图模型Stable Diffusion实现了文本之外的可控生成,让AI绘画实现了质的飞跃。这篇文章我们将简单总结一下ControlNet技术细节。 模型设计 ControlNet的模型结构如下所示,这里是直接复制一份SD的上半部分:Encoder和中间的Middle Block。 ControlNet的输入和原始的SD一样,包括noisy latents、time embedding以及text embedding。除此之外,ControlNet还需要引入额外的condition,这个condition是和原图一样大小的图像,比如canny边界图或者人体骨架图。这里并没有像SD那样采用VAE对condition进行编码,而...