
论文地址: 🔖 https://arxiv.org/pdf/2107.11291 代码地址: 前言 一般来说,我们可以把姿态估计任务分成两个流派:Heatmapbased和Regressionbased。 其主要区别在于监督信息的不同,Heatmapbased方法监督模型学习的是高斯概率分布图,即把GroundTruth中每个点渲染成一张高斯热图,最后网络输出为K张特征图对应K个关键点,然后通过argmax或softargmax来获取最大值点作为估计结果。这种方法由于需要渲染高斯热图,且由于热图中的最值点直接对应了结果,不可避免地需要维持一个相对高分辨率的热图(常见的是64x64,再小的话误差下界过大会造成严重的精度损失),因此也就自然而然导致了很大的计算量和内存开销。 Regression...
Generative Model
2026-01-11

🔖 https://stability.ai/news/stablediffusion3researchpaper 概述 SD3 模型与训练策略改进细节 SD3除了将去噪网络从 UNet 改成 DiT 外,SD3 还在模型结构与训练策略上做了很多小改进: 改变训练时噪声采样方法 将一维位置编码改成二维位置编码 提升 VAE 隐空间通道数 对注意力 QK 做归一化以确保高分辨率下训练稳定 本文会简单介绍这些改进。 论文阅读 核心贡献 介绍 Stable Diffusion 3 (SD3) 的文章标题为 Scaling Rectified Flow Transformers for HighResolution Image Synthesis。与其说它是一篇技术报告,更不如说它是一篇论文,因为它...
杂七杂八
2026-01-11

分布式深度学习里的通信严重依赖于规则的集群通信,诸如 allreduce, reducescatter, allgather 等,因此,实现高度优化的集群通信,以及根据任务特点和通信拓扑选择合适的集群通信算法至关重要。 本文以数据并行经常使用的 allreduce 为例来展示集群通信操作的数学性质。 Allreduce 在干什么? 如图 1 所示,一共 4个设备,每个设备上有一个矩阵(为简单起见,我们特意让每一行就一个元素),allreduce 操作的目的是,让每个设备上的矩阵里的每一个位置的数值都是所有设备上对应位置的数值之和。 如图 2 所示, allreduce 可以通过 reducescatter 和 allgather 这两个更基本的集群通信操作来实现。基于 ring 状通信可以高...
3D Model
2026-01-11
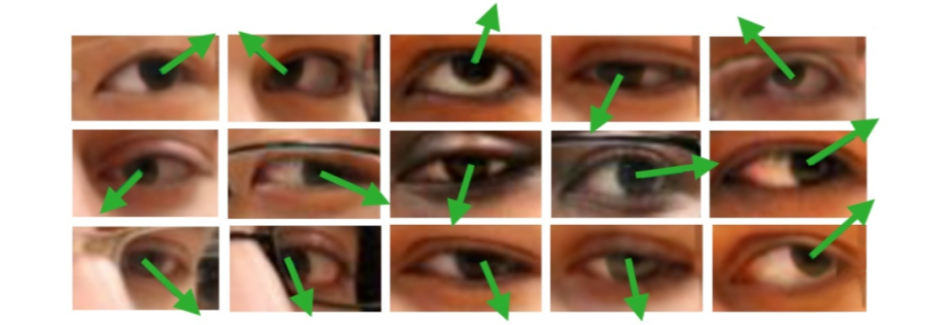
概述 问题定义 广义的 Gaze Estimation 泛指与眼球、眼动、视线等相关的研究,因此有不少做 saliency 和 egocentric 的论文也以 gaze 为关键词。而本文介绍的 Gaze Estimation 主要以眼睛图像或人脸图像为处理对象,估算人的视线方向或注视点位置, 如下图所示。 gaze角度的表示一般使用一个3d向量作为表示,也可以转换为pitch 和yaw角度,具体可参考 Model Gaze模型一般使用回归模型,所以这里基本只介绍一些在gaze model中使用的小技巧 Rle Loss 实际问题
Computer Vision
2026-01-11
mAP定义及相关概念 mAP: mean Average Precision, 即各类别AP的平均值 AP: PR曲线下面积,后文会详细讲解 PR曲线: PrecisionRecall曲线 Precision: TP / (TP + FP) Recall: TP / (TP + FN) TP: IoU0.5的检测框数量(同一Ground Truth只计算一次) FP: IoU= 0, 0.1, 0.2, ..., 1共11个点时的Precision最大值,然后AP就是这11个Precision的平均值。 在VOC2010及以后,需要针对每一个不同的Recall值(包括0和1),选取其大于等于这些Recall值时的Precision最大值,然后计算PR曲线下面积作为AP值。 mAP计算示例 假...
Deep Learning
2026-01-11

Random erasing data augmentation 论文名称:Random erasing data augmentation 论文地址:https://arxiv.org/pdf/1708.04896v2.pdf 随机擦除增强,非常容易理解。作者提出的目的主要是模拟遮挡,从而提高模型泛化能力,这种操作其实非常make sense,因为我把物体遮挡一部分后依然能够分类正确,那么肯定会迫使网络利用局部未遮挡的数据进行识别,加大了训练难度,一定程度会提高泛化能力。其也可以被视为add noise的一种,并且与随机裁剪、随机水平翻转具有一定的互补性,综合应用他们,可以取得更好的模型表现,尤其是对噪声和遮挡具有更好的鲁棒性。具体操作就是:随机选择一个区域,然后采用随机值进行覆盖,模拟遮...
Deep Learning
2026-01-11

DropBlock 论文题目:DropBlock: A regularization method for convolutional networks 论文地址:https://arxiv.org/abs/1810.12890 由于dropBlock其实是dropout在卷积层上的推广,故很有必须先说明下dropout操作。 dropout,训练阶段在每个minibatch中,依概率P随机屏蔽掉一部分神经元,只训练保留下来的神经元对应的参数,屏蔽掉的神经元梯度为0,参数不参数与更新。而测试阶段则又让所有神经元都参与计算。 dropout操作流程:参数是丢弃率p 1)在训练阶段,每个minibatch中,按照伯努利概率分布(采样得到0或者1的向量,0表示丢弃)随机的丢弃一部分神经元(即神经元...