
💡 引言 Trust Region Policy Optimization (TRPO) 是2015年的ICML会议上提出的一种强大的基于策略的强化学习算法。TRPO 解决了传统策略梯度方法中的一些关键问题,特别是训练不稳定和步长选择困难的问题。与传统策略梯度算法相比,TRPO 具有更高的稳健性和样本效率,能够在复杂环境中取得更好的性能。 优化基础 在深入了解 TRPO 之前,我们需要先简单回顾一些优化方法的基础知识。 梯度上升法 梯度上升法是一种迭代优化算法,用于寻找函数的局部最大值。 目标:找到使目标函数 [Math] 最大化的参数 [Math] : [公式] 梯度上升迭代过程: 1. 在当前参数 [Math] 处计算梯度: [Math] 1. 更新参数: 梯度上升法的主要问题是学习率的...
NLP
2026-01-11

概述 众所周知,尽管基于Attention机制的Transformer类模型有着良好的并行性能,但它的空间和时间复杂度都是 [Math] 级别的, n 是序列长度,所以当 n 比较大时Transformer模型的计算量难以承受。近来,也有不少工作致力于降低Transformer模型的计算量,比如模型剪枝、量化、蒸馏等精简技术,又或者修改Attention结构,使得其复杂度能降低到 [Math] 甚至 [Math] 。 改变这一复杂度的思路主要有两种: 一是走稀疏化的思路,比如OpenAI的Sparse Attention,通过“只保留小区域内的数值、强制让大部分注意力为零”的方式,来减少Attention的计算量。经过特殊设计之后,Attention矩阵的大部分元素都是0,因此理论上它也能节...
Computer Vision
2026-01-11

前言 首先看论文题目。Swin Transformer: Hierarchical Vision Transformer using Shifted Windows。即:Swin Transformer是一个用了移动窗口的层级式Vision Transformer 所以Swin来自于 Shifted Windows , 它能够使Vision Transformer像卷积神经网络一样,做层级式的特征提取,这样提取出来的特征具有多尺度的概念 ,这也是 Swin Transformer这篇论文的主要贡献。 标准的Transformer直接用到视觉领域有一些挑战,即: 多尺度问题:比如一张图片里的各种物体尺度不统一,NLP中没有这个问题; 分辨率太大:如果将图片的每一个像素值当作一个token直接输...
Reinforcement Learning
2026-01-11

引言 时序差分(TemporalDifference,TD)方法是强化学习中的一类核心算法,它结合了动态规划与蒙特卡洛方法的优点。TD方法是无模型(modelfree)学习方法,不需要环境模型即可学习价值函数和最优策略。 TD方法的核心特点是通过比较不同时间步骤的估计值之间的差异来更新价值函数,这种差异被称为"时序差分误差"(TD error)。TD方法可以被视为解决贝尔曼方程或贝尔曼最优方程的特殊随机逼近算法。 基础TD算法:状态值函数学习 给定策略 [Math] ,基础TD算法用于估计状态值函数 [Math] 。假设我们有一些按照策略 [Math] 生成的经验样本 (s_0, r_1, s_1, ..., s_t, r_{t+1}, s_{t+1}, ...) ,TD算法的更新规则为: ...
Reinforcement Learning
2026-01-11

引言 强化学习中,找到最优策略是核心目标。本文详细介绍三种能够找到最优策略的基础算法:价值迭代、策略迭代和截断策略迭代。这些算法属于动态规划范畴,需要系统模型,是后续无模型强化学习算法的重要基础。 在强化学习的发展路线中,这些算法处于"基础工具"到"算法/方法"的过渡阶段,是从"有模型"到"无模型"学习的重要桥梁。 价值迭代(Value iteration) 价值迭代算法基于收缩映射定理求解贝尔曼最优方程。其核心迭代公式为: [公式] 根据收缩映射定理,当 [Math] 时, v_k 和 [Math] 分别收敛到最优状态值和最优策略。 每次迭代包含两个步骤: 1. 策略更新步骤 (policy update step):找到能解决以下优化问题的策略 1. 价值更新步骤(value updat...
Preformer Performer的出发点还是标准的Attention,所以在它那里还是有 [Math] ,然后它希望将复杂度线性化,那就是需要找到新的 [Math] ,使得: [公式] 如果找到合理的从 [Math] 到 [Math] 的映射方案,便是该思路的最大难度了。 激活函数 线性Attention的常见形式如 式3,其中 [Math] 、 [Math] 是值域非负的激活函数。那么如何选取这个激活函数呢?Performer告诉我们,应该选择指数函数 [公式] 首先,我们来看它跟已有的结果有什么不一样。在 Transformers are RNNs 给出的选择是: [公式] 我们知道 1+x 正是 e^x 在 x=0 处的一阶泰勒展开,因此 [Math] 这个选择其实已经相当接近 ...
Computer Vision
2026-01-11

Segment Anything Segment Anything(SA)项目:一个用于图像分割的新任务、新模型和新数据集 通过FM(基础模型)+prompt解决了CV中难度较大的分割任务,给计算机视觉实现基础模型+提示学习+指令学习提供了一种思路 关键:加大模型容量(构造海量的训练数据,或者构造合适的自监督任务来预训练) Segment Anything Task SAM的一部分灵感是来源于NLP中的基座模型(Foundation Model),Foundation Model是OpenAI提出的一个概念,它指的是在超大量数据集上预训练过的大模型(如GPT系列、BERT),这些模型具有非常强大的 zeroshot 和 fewshot能力,结合prompt engineering和fine ...

引言与背景 策略梯度方法是强化学习中的一种重要方法,它标志着从基于价值的方法向基于策略的方法的重要转变。之前我们主要讨论了基于价值的方法(valuebased),而策略梯度方法则直接优化策略函数(policybased),这是一个重要的进步。 当策略用函数表示时,策略梯度方法的核心思想是通过优化某些标量指标来获得最优策略。与传统的表格表示策略不同,策略梯度方法使用参数化函数 [Math] 来表示策略,其中 [Math] 是参数向量。这种表示方法也可以写成其他形式,如 [Math] 、 [Math] 或 [Math] 。 策略梯度方法具有多种优势: 更高效地处理大型状态/动作空间 具有更强的泛化能力 样本使用效率更高 策略表示:从表格到函数 当策略的表示从表格转变为函数时,存在以下几个关键区别...

💡 GRPO相比PPO主要优势: 背景 GRPO是 DeepSeekMath model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO回顾 PPO的目标函数为: [公式] 其中: [Math] 和 [Math] 分别是当前和旧策略模型 A_t 是优势函数 [Math] 是裁剪相关的超参数 模型训练 如图1上所示,PPO需要同时训练一个Value Model [Math] 和策略模型, 同时需要reference model(通常从SFT model初始化)来限制策略模型训练保持和reference model的行为接近,而 Reward model用来计算...
Reinforcement Learning
2026-01-11
引言 大语言模型(LLMs)在近年来取得了显著进展,展现出上下文学习、指令跟随和逐步推理等突出特性。然而,由于这些模型是在包含高质量和低质量数据的预训练语料库上训练的,它们可能会表现出编造事实、生成有偏见或有毒文本等意外行为。因此,将LLMs与人类价值观对齐变得至关重要,特别是在帮助性、诚实性和无害性(3H)方面。 基于人类反馈的强化学习(RLHF)已被验证为有效的对齐方法,但训练过程复杂且不稳定。本文深入分析了RLHF框架,特别是PPO算法的内部工作原理,并提出了PPOmax算法,以提高策略模型训练的稳定性和效果。 RLHF的基本框架 RLHF训练过程包括三个主要阶段: 1. 监督微调(SFT):模型通过模仿人类标注的对话示例来学习一般的人类对话方式, 优化模型的指令跟随能力 1. 奖励模...
NLP
2026-01-11

这篇文章主要去“复盘”一下主流的长度外推结果,并试图从中发现免训练长度外推的关键之处。 问题定义 顾名思义,免训练长度外推,就是不需要用长序列数据进行额外的训练,只用短序列语料对模型进行训练,就可以得到一个能够处理和预测长序列的模型,即“Train Short, Test Long”。那么如何判断一个模型能否用于长序列呢?最基本的指标就是模型的长序列Loss或者PPL不会爆炸,更加符合实践的评测则是输入足够长的Context,让模型去预测答案,然后跟真实答案做对比,算BLEU、ROUGE等,LongBench就是就属于这类榜单。 但要注意的是,长度外推应当不以牺牲远程依赖为代价——否则考虑长度外推就没有意义了,倒不如直接截断文本——这意味着通过显式地截断远程依赖的方案都需要谨慎选择,比如AL...
Reinforcement Learning
2026-01-11
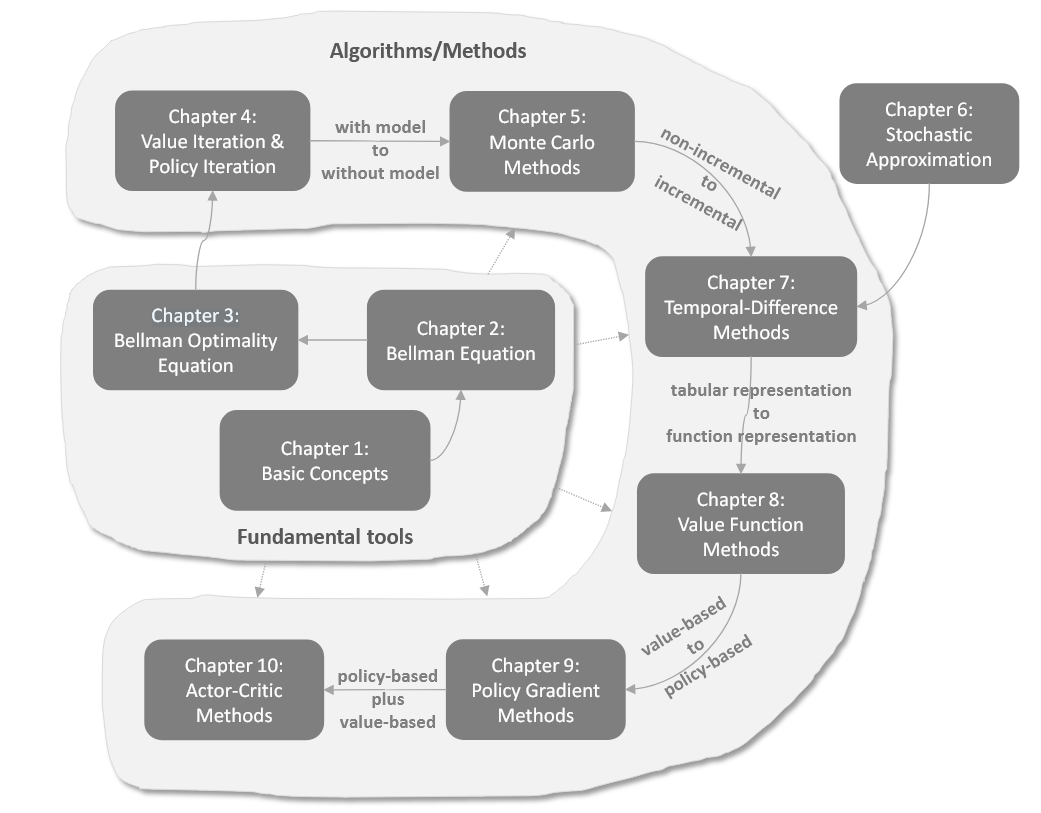
强化学习基础 改进算法 LLM中的RL