
什么是N-Gram模型 N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为 \(N\) 的滑动窗口操作,形成了长度是 \(N\) 的字节片段序列。 每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。 该模型基于这样一种假设,第 \(N\) 个词的出现只与前面 \(N-1\) 个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计 \(N\) 个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。 说完了n-gram模型的概念之后,下面讲解n-gram的一般应用。 N -Gram模型用于评估语句是否合理 如果我们有一个由 m 个词组成的序列(或者说一个句子),我们希望算得概率 \(p(w_1,w_2,...,w_m)\) ,根据链式规则,可得...
Generative Model
2026-04-15

简介 如果以概率的视角看待世界的生成模型。 在这样的世界观中,我们可以将任何类型的观察数据(例如 \(D\) )视为来自底层分布(例如 \( p_{data}\) )的有限样本集。 任何生成模型的目标都是在访问数据集 \(D\) 的情况下近似该数据分布。 如果我们能够学习到一个好的生成模型,我们可以将学习到的模型用于下游推理。 我们主要对数据分布的参数近似感兴趣,在一组有限的参数中,它总结了关于数据集 \(D\) 的所有信息。 与非参数模型相比,参数模型在处理大型数据集时能够更有效地扩展,但受限于可以表示的分布族。 在参数的设置中,我们可以将学习生成模型的任务视为在模型分布族中挑选参数,以最小化模型分布和数据分布之间的距离。 如上图,给定一个狗的图像数据集,我们的目标是学习模型族 \(M\) 中生成模型 θ 的参数,使得模型分布 \(p_θ\) 接近 \(p_{data}\) 上的数据分布。 在数学上,我们可以将我们的目标指定为以下优化问题: \[\mathop{min}\limits_{\theta\in M}d(p_\theta,p_{data})\] 其中, \(d()\)...
Computer Vision
2026-04-15

上图是Yolo v4中,对各种detector部件的总结:包含Input、backbone、neck、head、... Backbone 轻量级网络系列 Neck 例如:SPP 、 ASPP 、 RFB、 SAM 用来增加感受野 特征融合,主要是指不同输出层直接的特征融合,主要包括FPN、PAN、SFAM、ASFF和BiFPN。 结构 Path Aggregation Blcok Deformable Convolution系列 One stage Yolo系列 Focal Loss & RetinaNet Two-Stage Faster R-CNN R-FCN Anchor Free Anchor-Free Transformer DETR Problems 目标检测中的多尺度问题 NMS及其改进 IoU loss系列 目标检测中mAP计算

论文地址: https://arxiv.org/pdf/2107.11291 代码地址: https://github.com/Jeff-sjtu/res-loglikelihood-regression 前言 一般来说, 我们可以把姿态估计任务分成两个流派:Heatmap-based和Regression-based。 其主要区别在于监督信息的不同,Heatmap-based方法监督模型学习的是高斯概率分布图,即把GroundTruth中每个点渲染成一张高斯热图,最后网络输出为K张特征图对应K个关键点,然后通过argmax或soft-argmax来获取最大值点作为估计结果。这种方法由于需要渲染高斯热图,且由于热图中的最值点直接对应了结果,不可避免地需要维持一个相对高分辨率的热图(常见的是64x64,再小的话误差下界过大会造成严重的精度损失),因此也就自然而然导致了很大的计算量和内存开销。 Regression-based方法则非常简单粗暴,直接监督模型学习坐标值,计算坐标值的L1或L2...
NLP
2026-04-15
词向量,英文名叫Word Embedding,按照字面意思,应该是词嵌入。说到词向量,不少读者应该会立马想到Google出品的Word2Vec,大牌效应就是不一样。另外,用Keras之类的框架还有一个Embedding层,也说是将词ID映射为向量。由于先入为主的意识,大家可能就会将词向量跟Word2Vec等同起来,而反过来问“Embedding是哪种词向量?”这类问题,尤其是对于初学者来说,应该是很混淆的。事实上,哪怕对于老手,也不一定能够很好地说清楚。 这一切,还得从one hot说起... 五十步笑百步 one hot,中文可以翻译为“独热”,是最原始的用来表示字、词的方式。为了简单,本文以字为例,词也是类似的。假如词表中有“科、学、空、间、不、错”六个字,one hot就是给这六个字分别用一个0-1编码: \[\begin{array}{c|c}\hline\text{科} & [1, 0, 0, 0, 0, 0]\\
\text{学} & [0, 1, 0, 0, 0, 0]\\
\text{空} & [0, 0, 1, 0, 0, 0]\\
\text{间} &...
NLP
2026-04-15

概述 SSM的概念由来已久,但这里我们特指深度学习中的SSM,一般认为其开篇之作是2021年的 S4 ,不算太老,而SSM最新最火的变体大概是 Mamba 。当然,当我们谈到SSM时,也可能泛指一切线性RNN模型,这样 RWKV 、 RetNet 还有此前LRU都可以归入此类。不少SSM变体致力于成为Transformer的竞争者,尽管笔者并不认为有完全替代的可能性,但SSM本身优雅的数学性质也值得学习一番。 尽管我们说SSM起源于S4,但在S4之前,SSM有一篇非常强大的奠基之作 《HiPPO: Recurrent Memory with Optimal Polynomial Projections》 (简称HiPPO),所以本文从HiPPO开始说起。 另外值得一提的是,SSM代表作HiPPO、S4、Mamba的一作都是 Albert Gu ,他还有很多篇SSM相关的作品,毫不夸张地说,这些工作筑起了SSM大厦的基础。不论SSM前景如何,这种坚持不懈地钻研同一个课题的精神都值得我们由衷地敬佩。 今天,基本上你能叫出的任何语言模型都是 Transformer 模型。OpenAI 的...
Computer Vision
2026-04-15

Segment Anything Segment Anything(SA)项目:一个用于图像分割的新任务、新模型和新数据集 通过FM(基础模型)+prompt解决了CV中难度较大的分割任务,给计算机视觉实现基础模型+提示学习+指令学习提供了一种思路 关键:加大模型容量(构造海量的训练数据,或者构造合适的自监督任务来预训练) Segment Anything Task SAM的一部分灵感是来源于NLP中的基座模型(Foundation Model),Foundation Model是OpenAI提出的一个概念,它指的是在超大量数据集上预训练过的大模型(如GPT系列、BERT),这些模型具有非常强大的 zero-shot 和 few-shot能力,结合prompt engineering和fine tuning等技术可以将基座模型应用在各种下游任务中并实现惊人的效果。 SAM就是想构建一个这样的图像分割基座模型,即使是一个未见过的数据集,模型也能自动或半自动(基于prompt)地完成下游的分割任务。为了实现这个目标,SAM定义了一种可提示化的分割任务(promptable...
Computer Vision
2026-04-15
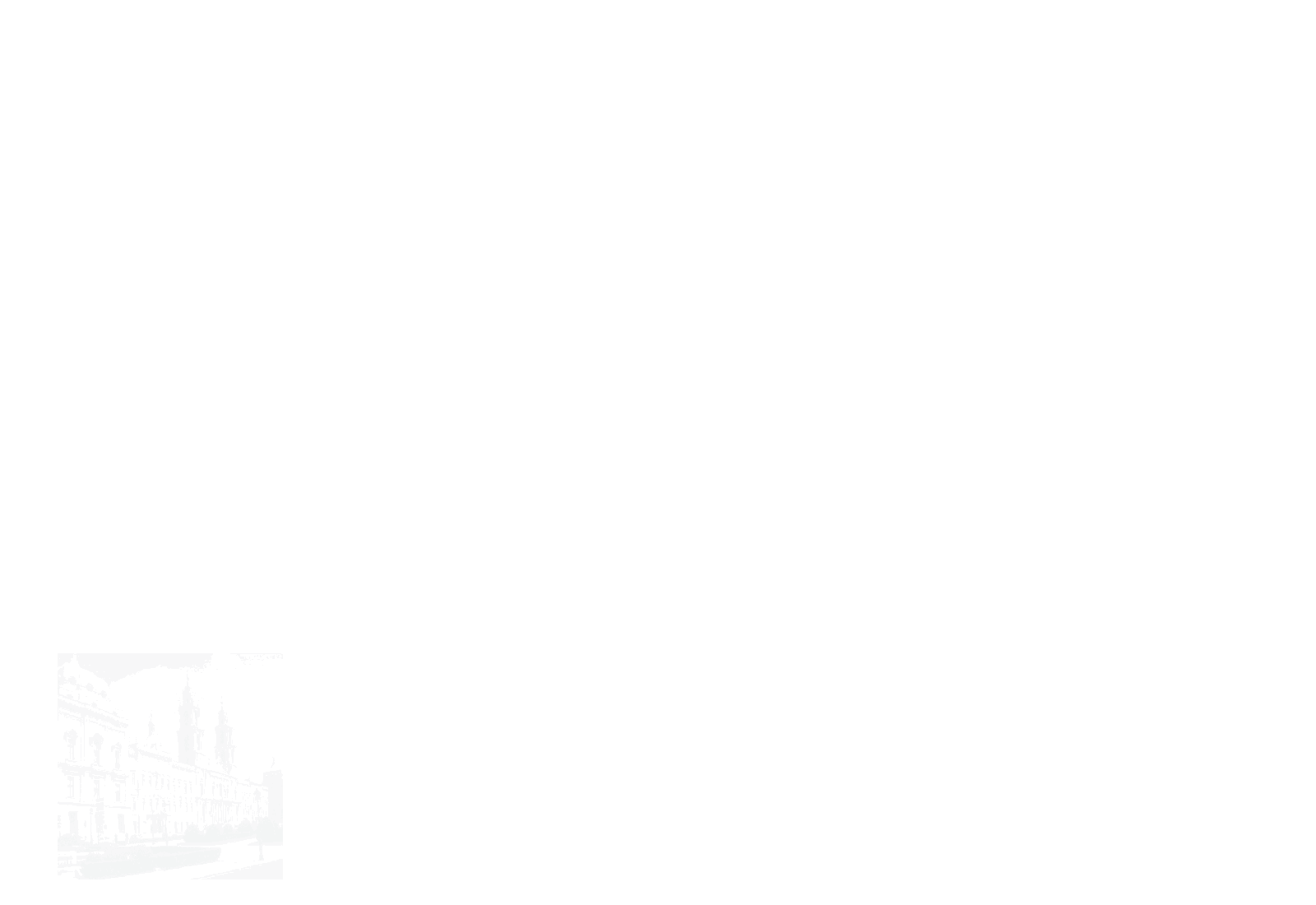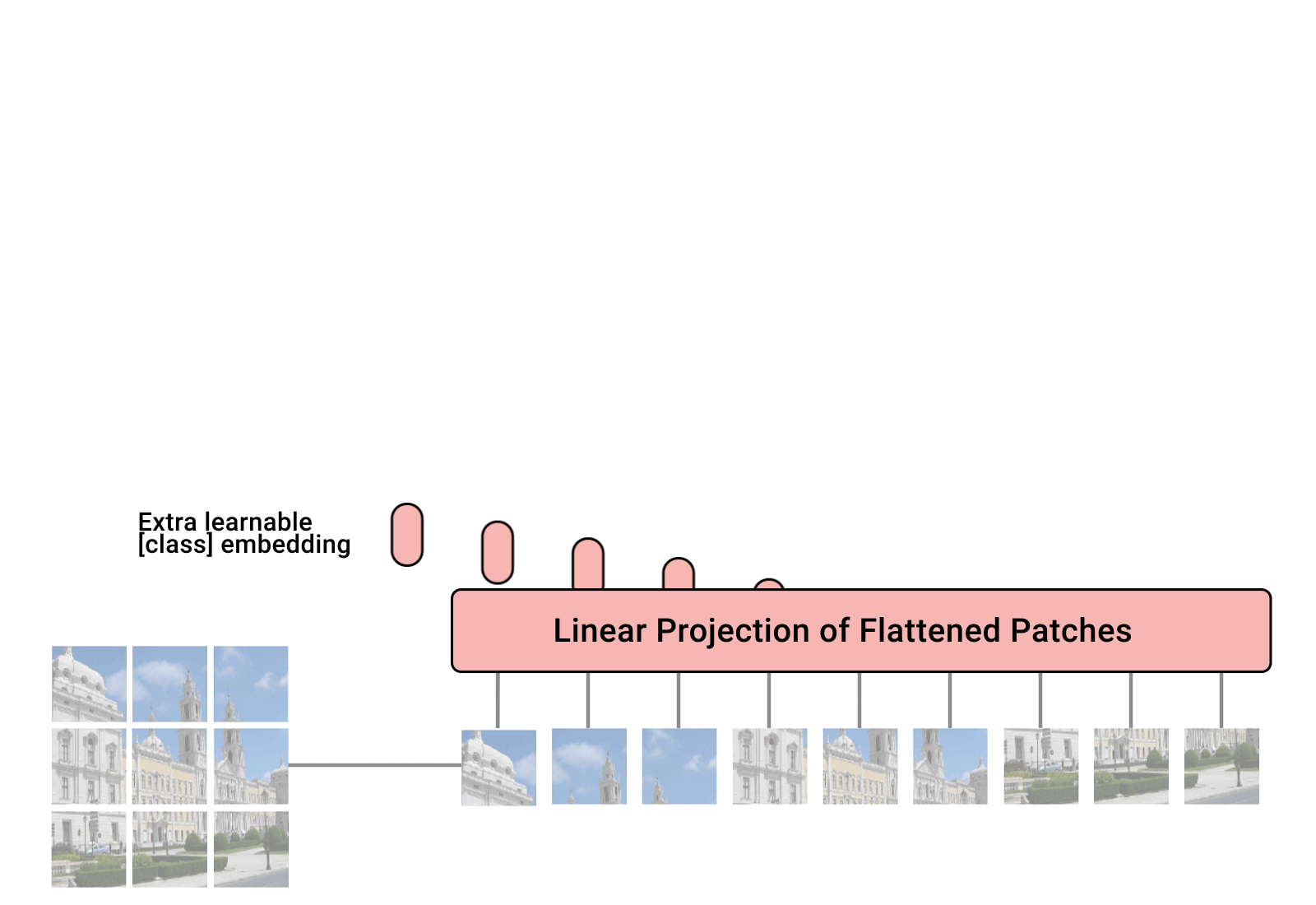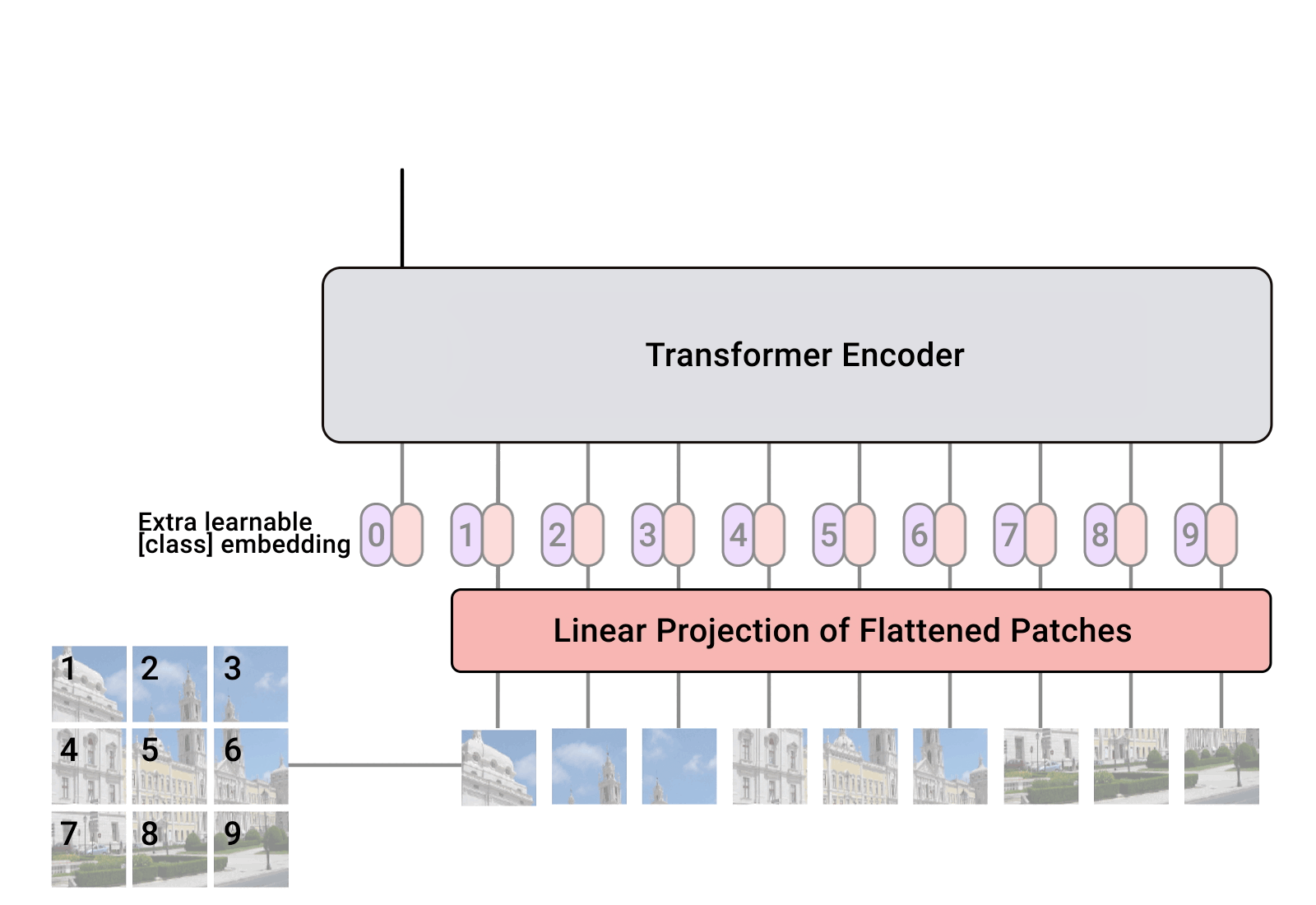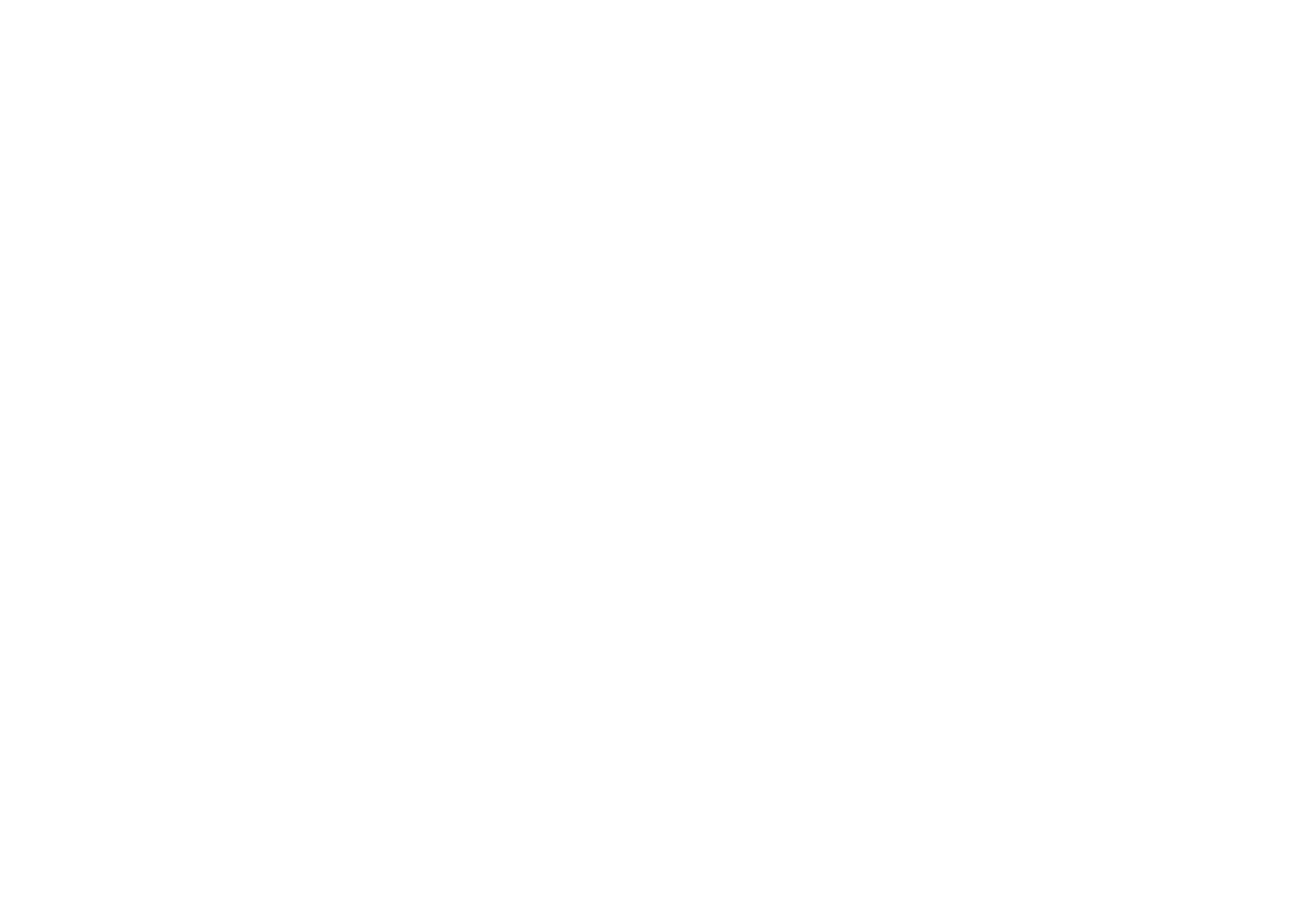
概述 在计算机视觉领域(CV),对视觉特征的理解CNN是长期处于主导地位的。而在NLP领域,Transformer框架的巨大成功,也激发了不少研究者探索将Transformer用于计算机视觉任务。ViT(Vision Transformer)的出现标志着在CV领域Transformer架构迈出了重要的一步。尤其在当前结合LLM的多模态探索上(MM-LLM),都是以LLM大语言模型为骨干架构的模型,多种模态的信息需要先做token化处理,再输入到LLM模型。ViT天然具有序列化特征的建模能力,自然在MM-LLM探索中大放异彩~ ViT在多模态模型中的角色类似于自然语言建模中的Tokenizer组件,对图像进行视觉特征编码,产出图像的序列特征。只不过ViT的编码过程本身也是采用了Transformer的模型结构。 本文主要结合几篇paper和源码讲讲ViT和针对ViT的一些优化方法~ ViT(Vision Transformer)...
Large Model
2026-04-15

总览 由于是“图文多模态”,还是要从“图”和“文”的表征方法讲起,然后讲清楚图文表征的融合方法。这里只讲两件事情: 视觉表征 :分为两个部分问题,一是如何合理建模视觉输入特征,二是如何通过预训练手段进行充分学习表征,这两点是基于视觉完成具体算法任务的基础; 视觉与自然语言的对齐(Visul Language Alignment)或融合 :目的是将视觉和自然语言建模到同一表征空间并进行融合,实现自然语言和视觉语义的互通,这点同样离不开预训练这一过程。模态对齐是处理多模态问题的基础,也是现在流行的多模态大模型技术前提。 对于视觉表征,从发展上可以分为卷积神经网络(CNN)和Vision Transformer(VIT)两大脉络,二者分别都有各自的表征、预训练以及多模态对齐的发展过程。而对于VIT线,另有多模态大模型如火如荼的发展,可谓日新月异。 CNN:视觉理解的一代先驱 点击展开 卷积视觉表征模型和预训练...
Computer Vision
2026-01-11
PA Pixel Accuracy(PA,像素精度):这是最简单的度量,为标记正确的像素占总像素的比例。 [公式] 图像中共有k+1(包含背景)类, p_{ii} 表示将第i类分成第 i 类的像素数量(正确分类的像素数量), p_{ij} 表示将第 i 类分成第 j 类的像素数量(所有像素数量) 因此该比值表示正确分类的像素数量占总像素数量的比例。 优点:简单 缺点:如果图像中大面积是背景,而目标较小,即使将整个图片预测为背景,也会有很高的PA得分,因此该指标不适用于评价以小目标为主的图像分割效果。 MPA Mean Pixel Accuracy(MPA,均像素精度):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。 [公式] MIoU Mean Interse...