💡 不断排除不存在解的区间,直至最后剩下一个 这里归纳最重要的部分: 分析题意,挖掘题目中隐含的 单调性; while (left < right) 退出循环的时候有 left == right 成立,因此无需考虑返回left还是right; 始终思考下一轮搜索区间是什么,如果是 [mid, right] 就对应 left = mid ,如果是 [left, mid 1] 就对应 right = mid 1,是保留 mid 还是 +1、−1 就在这样的思考中完成; 从一个元素什么时候不是解开始考虑下一轮搜索区间是什么 ,把区间分为 2个部分(一个部分肯定不存在目标元素,另一个部分有可能存在目标元素),问题会变得简单很多,这是一条 非常有用 的经验; 每一轮区间被划分成 2 部分,理解 区间划...
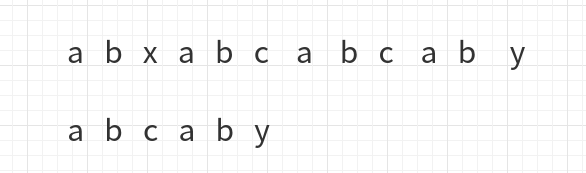
kmp算法用于字符串的模式匹配,也就是找到模式字符串在目标字符串的第一次出现的位置比如abababc那么bab在其位置1处,bc在其位置5处,我们首先想到的最简单的办法就是蛮力的一个字符一个字符的匹配,但那样的时间复杂度会是O(mn)。kmp算法保证了时间复杂度为O(m+n)。 基本原理 举个例子: 发现x与c不同后,进行移动 a与x不同,再次移动 此时比较到了c与y, 于是下一步移动成了下面这样 这一次的移动与前两次的移动不同,之前每次比较到上面长字符串的字符位置后,直接把模式字符串的首字符与它对齐,这次并没有,原因是这次移动之前,y与c对齐,但是y前边的ab是与自己的前缀ab一样,于是ab并不用再比较,直接从第三个位置开始比较,如图: 所以说kmp算法对于这种情况就直接使用当前比较字符之...
Algorithm
2026-01-11
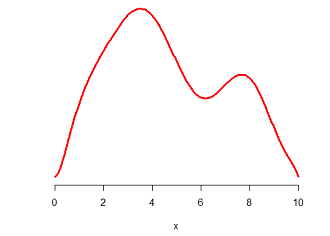
题意 给定平面上一个圆的圆心位置和半径,从圆中以均匀的概率随机选取点。 分析 拒绝取样 其实我的第一反应是用拒绝取样(Rejection Sampling)的思路来做:首先从这个圆的与坐标轴平行的外切正方形中均匀随机选取点,然后判断点是否位于圆中;如果不在,重新生成一个新的点,再次进行判断;否则直接返回。 直觉上来说,拒绝取样显然是正确的;不过我们可以用一种稍微更加形式化的方法来描述。(以下内容参考了拒绝采样(reject sampling)的简单认识,非常直观形象。) 下图是一个随机变量的密度函数曲线,试问如何获得这个随机变量的样本呢? 如果你像我一样,已经把概率论与数理统计统统还给数学老师了,那么提示一下,概率密度函数(PDF)是累积分布函数(CDF)的导数,反映的是概率的“密集程度”。...
Algorithm
2026-01-11
根据一棵树的先序遍历和中序遍历,或者后序遍历和中序遍历序列,都可以唯一地确定一棵树。 树中的节点,分为度为0,1,2的结点。如果树中只有一个节点,那么可以唯一确定一棵树,即只有一个节点的树。 当树中结点个数大于等于2的情况,树中的叶子结点和它的父亲结点中,至少有一种存在如下的情况。(为方便起见,我们先从叶子节点入手) case 1: case2: case 3: A D F / \ / \ B C E G 即,叶子结点的父亲有两个孩子,只有左孩子,只有右孩子的情况。我们只需要证明,如果树存在这三种结构中的哪一种,可以唯一确定一棵树,什么情况下又不能唯一确定一棵树呢? 1. case 1: A / \ B C 前序遍历: ABC, 后序遍历: BCA 现在,我们根据遍历序列,看看能否得到另一种...
Search&Rec
2026-01-11
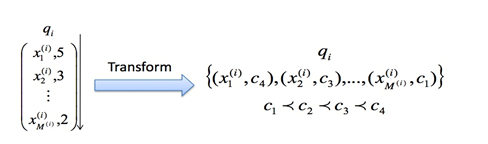
Learning to rank 排序学习是推荐、搜索、广告的核心方法。排序结果的好坏很大程度影响用户体验、广告收入等。排序学习可以理解为机器学习中用户排序的方法,这里首先推荐一本微软亚洲研究院刘铁岩老师关于LTR的著作,Learning to Rank for Information Retrieval,书中对排序学习的各种方法做了很好的阐述和总结。我这里是一个超级精简版。 排序学习是一个有监督的机器学习过程,对每一个给定的查询-文档对,抽取特征,通过日志挖掘或者人工标注的方法获得真实数据标注。然后通过排序模型,使得输入能够和实际的数据相似。常用的排序学习分为三种类型:PointWise,PairWise和ListWise。 PointWise 单文档方法的处理对象是单独的一篇文档,将文档...