问题定义 多元二次多项式,维度为 n ,那么可以用以下公式描述该函数: [Formula] 其中 a_{i,j} 为二次项系数,共有 n^2 项, 1≤i,j≤n ,且所有的 a 不全为0,即 ∃a_{i,j}≠0 ; b_k 为一次项系数,共 n 项, 1≤k≤n ; c 为常数项。 记 f(x)=[x_1,x_2,...,x_n]^T ,则上述函数可以写作二次型的形式: 转化过程中A,b满足: A 为n阶对称方阵, A_{i,j}=a_{i,j} 因为 ∃a_{i,j}≠0 ,A不为零矩阵 b_i=b_i 为了后续计算简便,我们将二次型稍作改动: [Formula] 我们的目标就是寻找该函...
Large Model
2026-01-11

Chameleon:生成理解统一模型的开山之作 🔖 https://arxiv.org/pdf/2405.09818 Chameleon 是一个既能做图像理解,又可以做图像或者文本生成任务的,从头训练的 Transformer 模型。完整记录了为实现 mixedmodal 模型的架构设计,稳定训练方法,对齐的配方。并在一系列全面的任务上进行评估:有纯文本任务,也有图像文本任务 (视觉问答、图像字幕),也有图像生成任务,还有混合模态的生产任务。 如下图所示,Chameleon 将所有模态数据 (图像、文本和代码) 都表示为离散 token,并使用统一的 Transformer 架构。训练数据是交错混合模态数据 ∼10T token,以端到端的方式从头开始训练。文本 token 用绿色表示,图像...
基本概念 方向导数:是一个数;反映的是 f(x,y) 在 P_0 点沿方向 v 的变化率。 偏导数:是多个数(每元有一个);是指多元函数沿坐标轴方向的方向导数,因此二元函数就有两个偏导数。 偏导函数:是一个函数;是一个关于点的偏导数的函数。 梯度:是一个向量;每个元素为函数对一元变量的偏导数;它既有大小(其大小为最大方向导数),也有方向。 方向导数 反映的是 f(x,y) 在 P_0 点沿方向 v 的变化率。 例子如下: 题目 设二元函数 f(x, y) = x^2 + y^2 ,分别计算此函数在点 (1, 2) 沿方向 w=\{3, 4\} 与方向 u=\{1, 0\} 的方向导数。 解: ...
Algorithm
2026-01-11
题目 给定一个无序的数组,找出数组在排序之后,相邻元素之间最大的差值。 如果数组元素个数小于 2,则返回 0。 Example 1: [代码] 解题思路:如果进行排序,这里会超时。采用桶排序 排序算法 的思想,可以在线性时间解决。 1. 首先建立桶,每个桶中只需要存放这个桶中元素的最大值和最小值。 1. 我们期望将数组中的各个数等距离分配,也就是每个桶的长度相同,也就是对于所有桶来说,桶内最大值减去桶内最小值都是一样的。可以当成公式来记。 1. 确定桶的数量,最后的加一保证了数组的最大值也能分到一个桶。为什么需要这样规定桶的尺寸呢?因为这样可以让最大的间距的两个元素在两个不同的桶中。可以证明一下,因为我们用元素范围之差除以元素个数,所以桶的尺寸就是平均的元素间距,显然最大间距的两个元素不可能...
Algorithm
2026-01-11

1. 可以重复选取 给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。 candidates 中的数字可以无限制重复被选取。 画出树状搜索图如下, 为了去除重复的情况, 我们需要按照某种顺序搜索,具体做法是:每一次搜索的时候,设置下一轮搜索的起点 [代码] 2. 不能被重复选取 与上面的区别在于 1. index每次不要重复搜索,而是去寻找下一个 1. 排除重复的元素 [代码]
Large Model
2026-01-11

问题背景 首先简化一下问题,本文所讨论的多模态,主要指图文混合的双模态,即输入和输出都可以是图文。可能有不少读者的第一感觉是:多模态模型难道不也是烧钱堆显卡,Transformer“一把梭”,最终“大力出奇迹”吗? 其实没那么简单。先看文本生成,事实上文本生成自始至终都只有一条主流路线,那就是语言模型,即建模条件概率 [Math] ,不论是最初的 ngram语言模型,还是后来的Seq2Seq、GPT,都是这个条件概率的近似。也就是说,一直以来,人们对“实现文本生成需要往哪个方向走”是很明确的,只是背后所用的模型有所不同,比如LSTM、CNN、Attention乃至最近复兴的线性RNN等。所以,文本生成确实可以All in Transformer来大力出奇迹,因为方向是标准的、清晰的。 然而,...
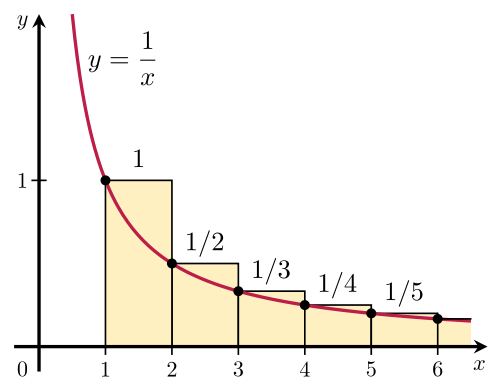
调和级数记住下面的公式就够了: [Formula] 证明方法就是下面这张图

一、泊松分布 日常生活中,大量事件是有固定频率的。 某医院平均每小时出生3个婴儿 某公司平均每10分钟接到1个电话 某超市平均每天销售4包xx牌奶粉 某网站平均每分钟有2次访问 它们的特点就是,我们可以预估这些事件的总数,但是没法知道具体的发生时间。已知平均每小时出生3个婴儿,请问下一个小时,会出生几个? 有可能一下子出生6个,也有可能一个都不出生。这是我们没法知道的。 泊松分布就是描述某段时间内,事件具体的发生概率。 [Formula] 上面就是泊松分布的公式。等号的左边, P 表示概率, N 表示某种函数关系, t 表示时间, n 表示数量,1小时内出生3个婴儿的概率,就表示为 P(N(1...
NLP
2026-01-11
概述 HiPPO(Highorder Polynomial Projection Operators)是目前大热的structured state space model (S4)及其后续工作的backbone. State space mode主要是控制学科里的内容,最近被引入深度学习领域来解决长距离依赖问题。长距离依赖建模的核心问题是如何通过有限的memory来尽可能记住之前所有的历史信息。当前的主流序列建模模型(即Transformer和RNN) 存在着普遍的遗忘问题 fixedsize context windows: Transformer的window size通常是有限的,一般来说quadratic的attention最多建模到大约10k的token就到计算极限了 vanish...
01背包 描述 有N件物品和一个容量为V的背包。 第i件物品的体积是vi,价值是wi。 求解将哪些物品装入背包,可使这些物品的总体积不超过背包流量,且总价值最大。 二维动态规划 f[i][j] 表示只看前i个物品,总体积是j的情况下,总价值最大是多少。 result = max(f[n][0V]) f[i][j]: 不选第i个物品:f[i][j] = f[i1][j]; 选第i个物品:f[i][j] = f[i1][jv[i]] + w[i](v[i]是第i个物品的体积) 两者之间取最大。 初始化:f[0][0] = 0 代码如下: [代码] 一维动态优化 从上面二维的情况来看,f[i] 只与f[i1]相关,因此只用使用一个一维数组[0v]来存储前一个状态。那么如何来实现呢? 第一个问题:状...
Large Model
2026-01-11

简介 🔖 https://bagelai.org/ BAGEL 模型原生支持统一的多模态理解和生成,是一个 decoderonly 的模型,BAGEL 在包含文本、图像、视频和网络数据的大量多模态数据上进行了预训练,包括数万亿 tokens。尽管有一些研究尝试扩展其统一模型,但它们主要仍然依赖于标准图像生成和理解任务中的图像文本配对数据进行训练。 然而,最近的研究发现,学术模型与 GPT4o 和 Gemini 2.0 等专有系统在统一多模态理解和生成方面存在显著差距,而这些专有系统的底层技术并未公开。作者认为,弥合这一差距的关键在于使用精心构建的多模态交错数据进行规模化训练。这种多模态交错数据整合了文本、图像、视频和网络来源。通过使用这种多样化的多模态交错数据进行扩展时,模型展现出复杂的、新...
Algorithm
2026-01-11
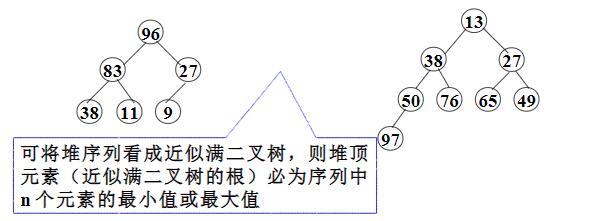
起步 heapq 模块实现了适用于Python列表的最小堆排序算法。 堆是一个树状的数据结构,其中的子节点都与父母排序顺序关系。因为堆排序中的树是满二叉树,因此可以用列表来表示树的结构,使得元素 N 的子元素位于 2N + 1 和 2N + 2 的位置(对于从零开始的索引)。 本文内容将分为三个部分,第一个部分简单介绍 heapq 模块的使用;第二部分回顾堆排序算法;第三部分分析heapq中的实现。 heapq 的使用 创建堆有两个基本的方法:heappush() 和 heapify(),取出堆顶元素用 heappop()。 heappush() 是用来向已有的堆中添加元素,一般从空列表开始构建: [代码] 如果数据已经在列表中,则使用 heapify() 进行重排: [代码] 回顾堆排序算...