DFS
NLP
2026-01-11

取代RNN——Transformer 在介绍Transformer前我们来回顾一下RNN的结构 对RNN有一定了解的话,一定会知道,RNN有两个很明显的问题 效率问题:需要逐个词进行处理,后一个词要等到前一个词的隐状态输出以后才能开始处理 如果传递距离过长还会有梯度消失、梯度爆炸和遗忘问题 为了缓解传递间的梯度和遗忘问题,设计了各种各样的RNN cell,最著名的两个就是LSTM和GRU了 LSTM (Long Short Term Memory) GRU (Gated Recurrent Unit) 但是,引用网上一个博主的比喻,这么做就像是在给马车换车轮,为什么不直接换成汽车呢? 于是就有了Transformer。Transformer 是Google Brain 2017的提出的一篇工...
Generative Model
2026-01-11

💡 Flowbased Models Normalizing Flow Normalizing Flow 是一种基于变换对概率分布进行建模的模型,其通过一系列离散且可逆的变换实现任意分布与先验分布(例如标准高斯分布)之间的相互转换。在 Normalizing Flow 训练完成后,就可以直接从高斯分布中进行采样,并通过逆变换得到原始分布中的样本,实现生成的过程。(有关 Normalizing Flow 的详细理论) 从这个角度看,Normalizing Flow 和 Diffusion Model 是有一些相通的,其做法的对比如下表所示。从表中可以看到,两者大致的过程是非常类似的,尽管依然有些地方不一样,但这两者应该可以通过一定的方法得到一个比较统一的表示。 Continuous Norma...
Generative Model
2026-01-11

SD模型原理 SD是CompVis、Stability AI和LAION等公司研发的一个文生图模型,它的模型和代码是开源的,而且训练数据LAION5B也是开源的。SD在开源90天github仓库就收获了33K的stars,可见这个模型是多受欢迎。 SD是一个基于latent的扩散模型,它在UNet中引入text condition来实现基于文本生成图像。SD的核心来源于Latent Diffusion这个工作,常规的扩散模型是基于pixel的生成模型,而Latent Diffusion是基于latent的生成模型,它先采用一个autoencoder将图像压缩到latent空间,然后用扩散模型来生成图像的latents,最后送入autoencoder的decoder模块就可以得到生成的图像。 ...
Large Model
2026-01-11
DeepSeekV2的发布引起了大家的热烈讨论。首先,最让人哗然的是1块钱100万token的价格,普遍比现有的各种竞品API便宜了两个数量级,以至于有人调侃“这个价格哪怕它输出乱码,我也会认为这个乱码是一种艺术”;其次,从模型的技术报告看,如此便宜的价格背后的关键技术之一是它新提出的MLA(Multihead Latent Attention),这是对GQA的改进,据说能比GQA更省更好,也引起了读者的广泛关注。 接下来,本文将跟大家一起梳理一下从MHA、MQA、GQA到MLA的演变历程,并着重介绍一下MLA的设计思路。 MHA MHA(MultiHead Attention),也就是多头注意力,是开山之作《Attention is all you need》所提出的一种Attention...
背景 RLHF 通常包括三个阶段: 有监督微调(SFT) 奖励建模阶段 (Reward Model) RL微调阶段 直接偏好优化(DPO) 传统的RLHF方法分两步走: 1. 先训练一个奖励模型来判断哪个回答更好 1. 然后用强化学习让语言模型去最大化这个奖励 这个过程很复杂,就像绕了一大圈:先学习"什么是好的",再学习"如何做好"。 DPO发现了一个数学上的捷径: 1. 关键发现:对于任何奖励函数,都存在一个对应的最优策略(语言模型);反过来说,任何语言模型也隐含着一个它认为最优的奖励函数 1. 直接优化:与其先训练奖励模型再训练语言模型,不如直接训练语言模型,让它自己内化"什么是好的" 1. 数学转换:DPO将"学习判断好坏"和"学习生成好内容"这两个任务合二为一,通过一个简单的数学变换...
计算几何(Computational Geometry),是一系列使用计算机解决几何问题的算法。与解析几何相比,计算几何更适合计算机运算,精度较高,运算速度较快,并且易于编写。 浮点误差 程序设计中,考虑到浮点数 double 有精度误差,在比较时,通常允许一定的误差,即对于两个数 a 、 b ,如果 [Math] ,则认为 a=b 。一般根据题目要求, d (代码中命名为 EPS)取一个较小值,如 10^{8} 。 [代码] 向量 向量(vector)是一个有大小和方向的量,在几何中,它被表示为带箭头的线段。向量可以用起点和终点的坐标来表示 —— 从点 A到点B 的向量表示为 [Math] 。 向量的书写,两个大写字母上加一个箭头(表示方向) [Math] 向量没有位置,即向量可以在平面内...
Computer Vision
2026-01-11

原理分析 网络架构: 本文的任务是Object detection,用到的工具是Transformers,特点是Endtoend。 目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他...
Large Model
2026-01-11

Stanford Alpaca 结合英文语料通过Self Instruct方式微调LLaMA 7B Stanford Alpaca简介 2023年3月中旬,斯坦福的Rohan Taori等人发布Alpaca(中文名:羊驼):号称只花100美元,人人都可微调Meta家70亿参数的LLaMA大模型(即LLaMA 7B),具体做法是通过52k指令数据,然后在8个80GB A100上训练3个小时,使得Alpaca版的LLaMA 7B在单纯对话上的性能比肩GPT3.5(textdavinci003),这便是指令调优LLaMA的意义所在 论文《Alpaca: A Strong OpenSource InstructionFollowing Model》 GitHub地址:https://github.c...
Large Model
2026-01-11
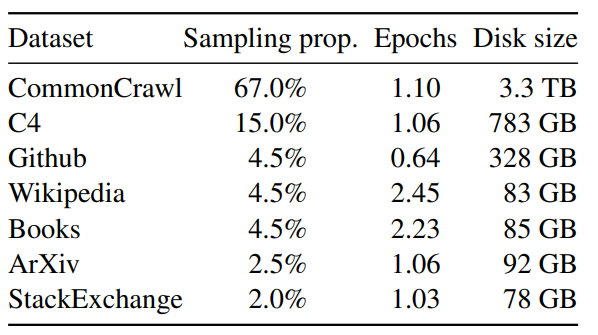
论文名称:LLaMA: Open and Efficient Foundation Language Models 论文地址: https://arxiv.org/pdf/2302.13971.pdf 代码链接: https://github.com/facebookresearch/llama 背景 模型参数量级的积累,或者训练数据的增加,哪个对性能提升帮助更大? 以 GPT3 为代表的大语言模型 (Large language models, LLMs) 在海量文本集合上训练,展示出了惊人的涌现能力以及零样本迁移和少样本学习能力。GPT3 把模型的量级缩放到了 175B,也使得后面的研究工作继续去放大语言模型的量级。大家好像有一个共识,就是:模型参数量级的增加就会带来同样的性能提升。 但...
Large Model
2026-01-11

背景 随着预训练语言模型进入LLM时代,其参数量愈发庞大。全量微调模型所有参数所需的显存早已水涨船高。 例如: 全参微调Qwen1.57BChat预估要2张80GB的A800,160GB显存 全参微调Qwen1.572BChat预估要20张80GB的A800,至少1600GB显存。 而且,通常不同的下游任务还需要LLM的全量参数,对于算法服务部署来说简直是个灾难 当然,一种折衷做法就是全量微调后把增量参数进行SVD分解保存,推理时再合并参数 为了寻求一个不更新全部参数的廉价微调方案,之前一些预训练语言模型的高效微调(Parameter Efficient finetuning, PEFT)工作,要么插入一些参数或学习外部模块来适应新的下游任务。 LoRA LoRA(LowRank Adapt...
NLP
2026-01-11

摘掉Softmax 制约Attention性能的关键因素,其实是定义里边的Softmax!事实上,简单地推导一下就可以得到这个结论。 [Math] 这一步我们得到一个 [Math] 的矩阵,就是这一步决定了Attention的复杂度是 [Math] ;如果没有Softmax,那么就是三个矩阵连乘 [Math] ,而矩阵乘法是满足结合率的,所以我们可以先算 [Math] ,得到一个 [Math] 的矩阵,然后再用 [Math] 左乘它,由于 [Math] ,所以这样算大致的复杂度只是 [Math] (就是 [Math] 左乘那一步占主导)。 也就是说,去掉Softmax的Attention的复杂度可以降到最理想的线性级别 [Math] !这显然就是我们的终极追求:Linear Attentio...