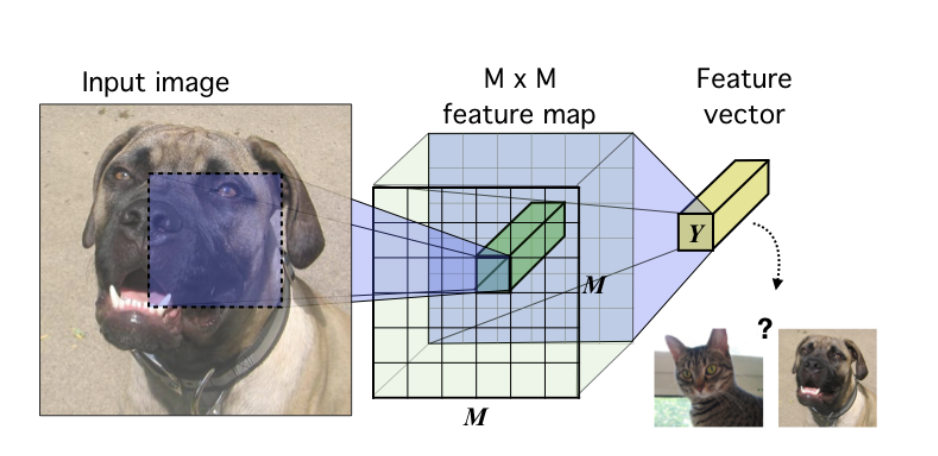
Generative Model
2026-01-19

💡 扩散模型:通过加噪的方式去学习原始数据的分布, 从学到的分布中去生成样本 DDPM 关键点: 1. 正向加噪是离散时间马尔可夫链:从 \(x_0\) 逐步加噪得到 \(x_1,x_2,...,x_T\) ;在合适的噪声调度与足够大的 \(T\) 下, \(x_T\) 近似服从 \( N(0,I) \) 的各向同性高斯。 2. 每一步噪声方差 \(β_t\) 满足 \(0<β_t<1\) ,通常随 \(t\) 增大;因此 \(q(x_t|x_{t-1}) \) 的均值缩放系数 \(\sqrt{1-β_t} \) 逐渐减小。 3. 训练通过最大化对数似然的变分下界(ELBO)来学习反向过程 \( p_θ(x_{t-1}|x_t)\) ,并将其参数化为高斯分布(神经网络预测均值/噪声或 score)。 4. 将目标写成 score/DSM 形式时,loss 的权重与对应噪声层的方差尺度(如 \(1-\bar{α}_t\) 或相关量)有关;采样通常是按学习到的反向转移逐步生成(祖先采样),与经典 Langevin MCMC 更新形式不同,但可在 SDE 视角下统一理解。...