Large Model
2026-01-26
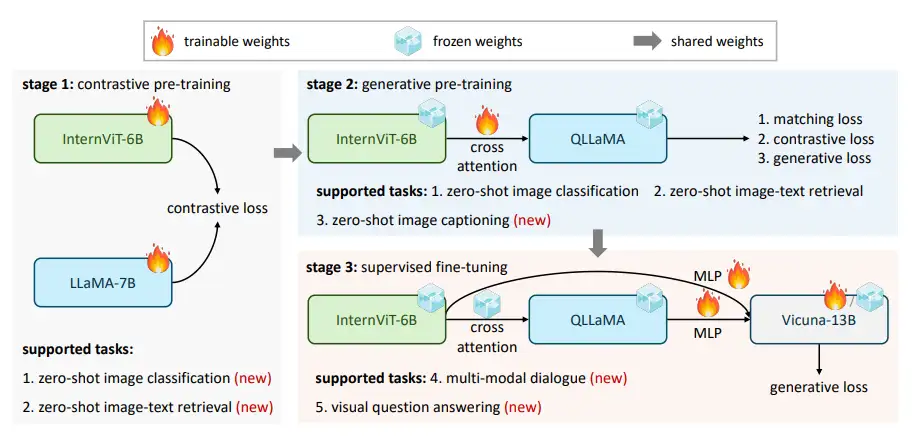
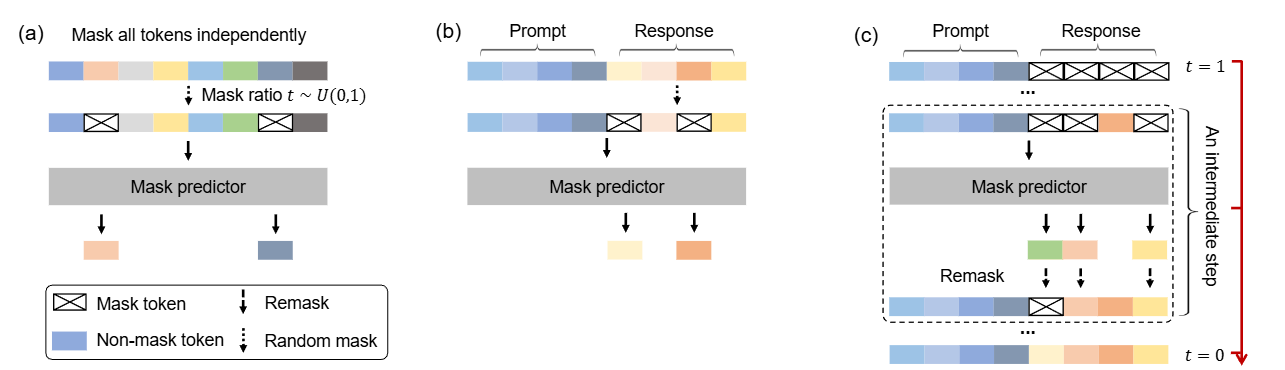
InternVL Blog: https://internvl.github.io/blog/ Github: https://github.com/OpenGVLab/InternVL InternVL 1.0 对齐策略 语言模型和视觉模型各自发展,各有突破,但如何让语言模型会看图,或者让视觉模型会说话?为了将视觉模型与语言模型进行连接,对齐如同“胶水”,将两种模型链接在一起,如使用QFormer或线性投影这样的轻量级“胶水”层,来形成视觉-语言模型,如InstructBLIP和LLaVA,但均存在局限性。 现有对齐策略的局限性 参数规模的不一致: LLM的参数规模已经达到1000亿,而广泛使用的VLLM的视觉编码器仍在10亿参数左右。这种差距可能导致LLM的能力无法被充分利用。 特征表示的不一致: 在纯视觉数据上训练的视觉模型或与BERT系列对齐的模型往往与LLM存在表示上的不一致。 连接效率低下: “胶水”层通常是轻量的、随机初始化的,可能无法捕捉到多模态理解和生成所需的丰富的跨模态交互和依赖关系。 InternVL引入全新的对齐策略...