
1. 什么是NGram模型 NGram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。 每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。 该模型基于这样一种假设,第N个词的出现只与前面N1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的BiGram和三元的TriGram。 说完了ngram模型的概念之后,下面讲解ngram的一般应用。 2. NGram模型用于评估语句是否合理 如果...
NLP
2026-01-11
词向量,英文名叫Word Embedding,按照字面意思,应该是词嵌入。说到词向量,不少读者应该会立马想到Google出品的Word2Vec,大牌效应就是不一样。另外,用Keras之类的框架还有一个Embedding层,也说是将词ID映射为向量。由于先入为主的意识,大家可能就会将词向量跟Word2Vec等同起来,而反过来问“Embedding是哪种词向量?”这类问题,尤其是对于初学者来说,应该是很混淆的。事实上,哪怕对于老手,也不一定能够很好地说清楚。 这一切,还得从one hot说起... 五十步笑百步 one hot,中文可以翻译为“独热”,是最原始的用来表示字、词的方式。为了简单,本文以字为例,词也是类似的。假如词表中有“科、学、空、间、不、错”六个字,one hot就是给这六个字分...
Large Model
2026-01-11

引言 Structured Generation with LLM,是指让LLM按照预先定义的schema,输出符合schema的结构化结果。 常见的应用场景有: 1. 数据处理。主要功能为a b,即从源文本中抽取/生成符合schema的结果,例如给定新闻,进行分类、抽取关键词、生成总结等; 1. Agent。主要功能是Tool Calling,即根据用户query,选择适当的tool和入参。 将 LLM 限制为始终生成符合特定模式的、有效的 JSON 或 YAML,是许多应用的关键功能。 Kor Kor,一个基于prompt的技术方案;Kor比较适合数据处理场景,且原理简单、易于理解,适合作为入门, 并且Kor适用于那些不支持function calling的比较旧的模型。 使用Kor进行...
Large Model
2026-01-11

概述 Medusa 是自投机领域较早的一篇工作,对后续工作启发很大,其主要思想是 multidecoding head + tree attention + typical acceptance(threshold)。Medusa 没有使用独立的草稿模型,而是在原始模型的基础上增加多个解码头(MEDUSA heads),并行预测多个后续 token。 正常的LLM只有一个用于预测 t 时刻token的head。Medusa 在 LLM 的最后一个 Transformer层之后保留原始的 LM Head,然后额外增加多个(假设是 k 个) 可训练的Medusa Head(解码头),分别负责预测 ...

💡 GRPO相比PPO主要优势: 背景 GRPO是 DeepSeekMath model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO回顾 PPO的目标函数为: [公式] 其中: [Math] 和 [Math] 分别是当前和旧策略模型 A_t 是优势函数 [Math] 是裁剪相关的超参数 模型训练 如图1上所示,PPO需要同时训练一个Value Model [Math] 和策略模型, 同时需要reference model(通常从SFT model初始化)来限制策略模型训练保持和reference model的行为接近,而 Reward model用来计算...
Large Model
2026-01-11

概述 投机解码(Speculative Decoding)也叫预测解码/投机采样,它会利用小模型来预测大型模型的行为,从而提升模型在解码(decoding)阶段的解码效率问题,加速大型模型的执行。其核心思路如下图所示,首先以低成本的方式(以小模型为主,也有多头,检索,Early Exit 等方式)快速生成多个候选 Token(串行序列、树、多头树等),然后通过一次并行验证阶段快速验证多个 Token的正确性,只要平均每个 Step 验证的 Token 数 1,就可以一次性生成多个token,进而减少总的 Decoding 步数,实现加速的目的。 下图左侧是自回归解码模型,右侧是投机解码机制。 从本质上来说,投机解码希望在推理阶段在不大幅度改变模型的情况下,通过更好利用冗余算力来并行"投机"地...
Reinforcement Learning
2026-01-11
引言 大语言模型(LLMs)在近年来取得了显著进展,展现出上下文学习、指令跟随和逐步推理等突出特性。然而,由于这些模型是在包含高质量和低质量数据的预训练语料库上训练的,它们可能会表现出编造事实、生成有偏见或有毒文本等意外行为。因此,将LLMs与人类价值观对齐变得至关重要,特别是在帮助性、诚实性和无害性(3H)方面。 基于人类反馈的强化学习(RLHF)已被验证为有效的对齐方法,但训练过程复杂且不稳定。本文深入分析了RLHF框架,特别是PPO算法的内部工作原理,并提出了PPOmax算法,以提高策略模型训练的稳定性和效果。 RLHF的基本框架 RLHF训练过程包括三个主要阶段: 1. 监督微调(SFT):模型通过模仿人类标注的对话示例来学习一般的人类对话方式, 优化模型的指令跟随能力 1. 奖励模...
Large Model
2026-01-11
比起两年前,NLG任务已经得到了非常有效的发展,transformers模块的使用广泛程度也达到前所未有的程度。在模型推理预测时,一个核心的语句就是model.generate(),本文就来详细介绍一下generate方法是如何运作的。在生成的过程中,包含了诸多生成策略,本文将以最常用的beam search为例,尽可能详细地展开介绍。 随着各种LLM的出现,transformers中与generate相关的代码发生了一些变化,主要区别在于: generate的源码位置发生了改变; generate方法中,采用一个generation_config参数来管理生成相关的各种配置,并优化了逻辑,使得逻辑更加清晰。 1. generate的代码位置 在之前版本的transformers中(tran...
Search&Rec
2026-01-11
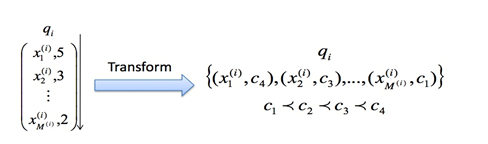
Learning to rank 排序学习是推荐、搜索、广告的核心方法。排序结果的好坏很大程度影响用户体验、广告收入等。排序学习可以理解为机器学习中用户排序的方法,这里首先推荐一本微软亚洲研究院刘铁岩老师关于LTR的著作,Learning to Rank for Information Retrieval,书中对排序学习的各种方法做了很好的阐述和总结。我这里是一个超级精简版。 排序学习是一个有监督的机器学习过程,对每一个给定的查询-文档对,抽取特征,通过日志挖掘或者人工标注的方法获得真实数据标注。然后通过排序模型,使得输入能够和实际的数据相似。常用的排序学习分为三种类型:PointWise,PairWise和ListWise。 PointWise 单文档方法的处理对象是单独的一篇文档,将文档...