
Pycharm 的图形化界面虽然好用,但是在某些场景中,是无法使用的。而 Python 本身已经给我们提供了一个调试神器 pdb. 准备文件 在调试之前先将这两个文件准备好(做为演示用),并放在同级目录中。 utils.py [代码] pdb_demo.py [代码] 进入调试模式 主要有两种方法 做为脚本调用,方法很简单,就像正常执行python脚本一样,只是多加了m pdb [代码] 使用这个方式进入调试模式,会在脚本的第一行开始单步调试。 对于单文件的脚本并没有什么问题,如果是一个大型的项目,项目里有很多的文件,使用这种方式只能大大降低我们的效率。 一般情况下,都会直接在你需要的地方打一个断点,那如何打呢? 只需在你想要打断点的地方加上这两行。 [代码] 然后执行时,也不需要再指定m ...
Python
2026-01-11
通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”,继承的过程,就是从一般到特殊的过程。在某些 OOP 语言中,一个子类可以继承多个基类。但是一般情况下,一个子类只能有一个基类,要实现多重继承,可以通过多级继承来实现 python2中经典类和新式类的继承方式不同,经典类采用深度优先搜索的继承,新式类采用的是广度优先搜索的继承方式 python3中经典类和新式类的继承方式都采用的是都采用广度优先搜索的继承方式 [代码] [代码] 举个例子来说明:现有4个类,A,B,C,D类,D类继承于B类和C类,B类与C类继承于A类。class D(B,C) 实例化D类 深度优先 现在构造函数的继承情况为: 若D类有构造函数,则重写所有父类的继承 若D类没有构造函数,B类有...

PrefixTuning Paper: 2021.1 Optimizing Continuous Prompts for GenerationGithub:https://github.com/XiangLi1999/PrefixTuningPrompt: Continus Prefix PromptTask & Model:BART(Summarization), GPT2(Table2Text) 最早提出Prompt微调的论文之一,其实是可控文本生成领域的延伸,因此只针对摘要和Table2Text这两个生成任务进行了评估。 PrefixTuning可以理解是CTRL模型的连续化升级版,为了生成不同领域和话题的文本,CTRL是在预训练阶段在输入文本前加入了control code,例如好评...
Large Model
2026-01-11

背景 随着预训练语言模型进入LLM时代,其参数量愈发庞大。全量微调模型所有参数所需的显存早已水涨船高。 例如: 全参微调Qwen1.57BChat预估要2张80GB的A800,160GB显存 全参微调Qwen1.572BChat预估要20张80GB的A800,至少1600GB显存。 而且,通常不同的下游任务还需要LLM的全量参数,对于算法服务部署来说简直是个灾难 当然,一种折衷做法就是全量微调后把增量参数进行SVD分解保存,推理时再合并参数 为了寻求一个不更新全部参数的廉价微调方案,之前一些预训练语言模型的高效微调(Parameter Efficient finetuning, PEFT)工作,要么插入一些参数或学习外部模块来适应新的下游任务。 Adapter tuning Adapter ...
Large Model
2026-01-11
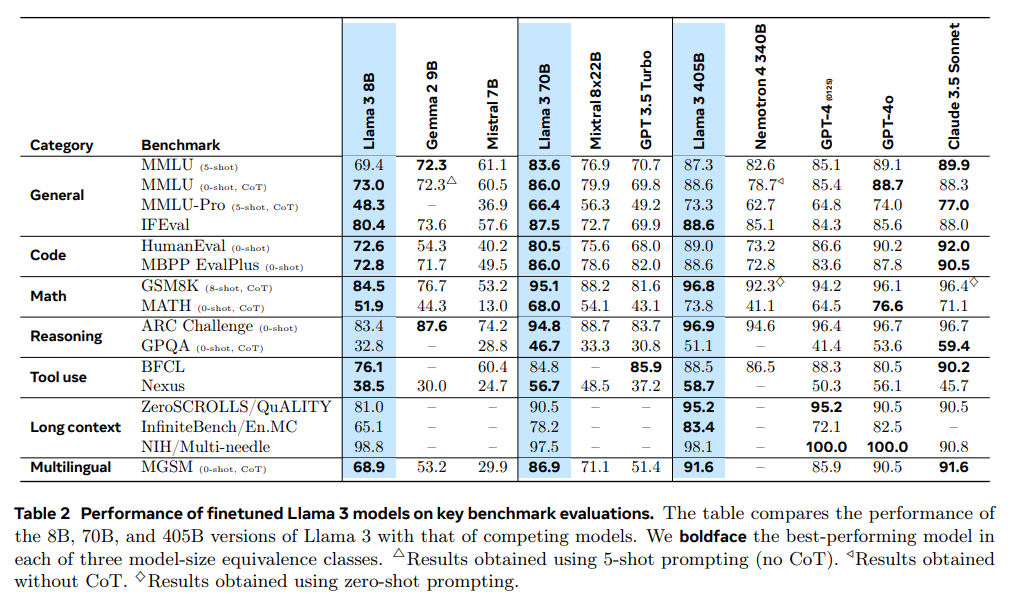
🔖 https://ai.meta.com/research/publications/thellama3herdofmodels/ 简介 本文归纳llm的训练分为两个主要阶段: 预训练阶段 pretraining,模型通过使用简单的任务如预测下一个词或caption进行大规模训练 后训练阶段 posttraining,模型经过调整以遵循指令、与人类偏好保持一致,并提高特定能力, 例如编码和推理。 Llama 3.1 发布,在 15.6T 多语言 tokens 上训练,支持多语言,编程,推理和工具使用。新模型支持 128K tokens 长度的上下文。最大的旗舰模型参数量为 405B,效果达到了闭源模型的 SOTA。 模型结构 Llama 3.1 的模型和 Llama 3 是一样的,只是做了...
Large Model
2026-01-11
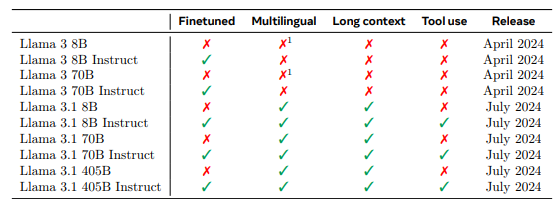
LLaMA 一直致力于LLM模型研究的国外TOP 3大厂除了OpenAI、Google,便是Meta(原来的Facebook) Meta曾第一个发布了基于LLM的聊天机器人——BlenderBot 3,但输出不够安全,很快下线;再后来,Meta发布一个专门为科学研究设计的模型Galactica,但用户期望过高,发布三天后又下线 23年2.24日,Meta通过论文《LLaMA: Open and Efficient Foundation Language Models》发布了自家的大型语言模型LLaMA,有多个参数规模的版本(7B 13B 33B 65B),并于次月3.8日被迫开源 LLaMA只使用公开的数据(总计1.4T即1,400GB的token,其中CommonCrawl的数据占比67%...
Large Model
2026-01-11

概述 在大型语言模型(LLM)中,幻觉(Hallucination)通常指模型生成不实、虚构、不一致或无意义的内容。本文将幻觉问题聚焦于模型输出未被上下文或世界知识所支撑的情况。 幻觉的分类 幻觉主要分为两类: 1. 内在幻觉(Incontext hallucination):模型输出和上下文(prompt+input)不一致。 1. 外在幻觉(Extrinsic hallucination):不符合事实知识。具体来说,模型输出应基于预训练数据集。由于预训练数据规模庞大,验证成本高昂,因此需要确保模型输出: 后文重点关注外在幻觉问题。 幻觉产生的原因 预训练数据问题 预训练数据量巨大,通常从公开互联网爬取,数据中存在过时、缺失或错误的信息,模型通过最大化对数似然进行记忆,可能错误地学习这些信...
Python
2026-01-11
Python程序中存储的所有数据都是对象,每一个对象有一个身份,一个类型和一个值。 看变量的实际作用,执行a = 8 这行代码时,就会创建一个值为8的int对象。 变量名是对这个"一个值为8的int对象"的引用。(也可以简称a绑定到8这个对象) 1、可以通过id()来取得对象的身份 这个内置函数,它的参数是a这个变量名,这个函数返回的值 是这个变量a引用的那个"一个值为8的int对象"的内存地址。 [代码] 2、可以通过type()来取得a引用对象的数据类型 [代码] 3、对象的值 当变量出现在表达式中,它会被它引用的对象的值替代。 总结:类型是属于对象,而不是变量。变量只是对对象的一个引用。 对象有可变对象和不可变对象之分。 Python函数传递参数到底是传值还是引用? 传值、引用这个是c...
Machine Learning
2026-01-11

1. 从GBDT到XGBoost 作为GBDT的高效实现,XGBoost是一个上限特别高的算法,因此在算法竞赛中比较受欢迎。简单来说,对比原算法GBDT,XGBoost主要从下面三个方面做了优化: 一是算法本身的优化:在算法的弱学习器模型选择上,对比GBDT只支持决策树,还可以选择很多其他的弱学习器。在算法的损失函数上,除了本身的损失,还加上了正则化部分。在算法的优化方式上,GBDT的损失函数只对误差部分做负梯度(一阶泰勒)展开,而XGBoost损失函数对误差部分做二阶泰勒展开,更加准确。算法本身的优化是我们后面讨论的重点。 二是算法运行效率的优化:对每个弱学习器,比如决策树建立的过程做并行选择,找到合适的子树分裂特征和特征值。在并行选择之前,先对所有的特征的值进行排序分组,方便前面说的并行...
DFS
Machine Learning
2026-01-11

这篇博客介绍一下集成学习的几类:Bagging,Boosting以及Stacking。 传统机器学习算法 (例如:决策树,人工神经网络,支持向量机,朴素贝叶斯等) 的目标都是寻找一个最优分类器尽可能的将训练数据分开。集成学习 (Ensemble Learning) 算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话:三个臭皮匠,赛过诸葛亮。 Thomas G. Dietterich 指出了集成算法在统计,计算和表示上的有效原因: 统计上的原因 一个学习算法可以理解为在一个假设空间 H 中选找到一个最好的假设。但是,当训练样本的数据量小到不够用来精确的学习到目标假设时,学习算法可以找到很多满足训练样本的分类器。所以,学习算法选择...
Large Model
2026-01-11
DeepSeekV2的发布引起了大家的热烈讨论。首先,最让人哗然的是1块钱100万token的价格,普遍比现有的各种竞品API便宜了两个数量级,以至于有人调侃“这个价格哪怕它输出乱码,我也会认为这个乱码是一种艺术”;其次,从模型的技术报告看,如此便宜的价格背后的关键技术之一是它新提出的MLA(Multihead Latent Attention),这是对GQA的改进,据说能比GQA更省更好,也引起了读者的广泛关注。 接下来,本文将跟大家一起梳理一下从MHA、MQA、GQA到MLA的演变历程,并着重介绍一下MLA的设计思路。 MHA MHA(MultiHead Attention),也就是多头注意力,是开山之作《Attention is all you need》所提出的一种Attention...