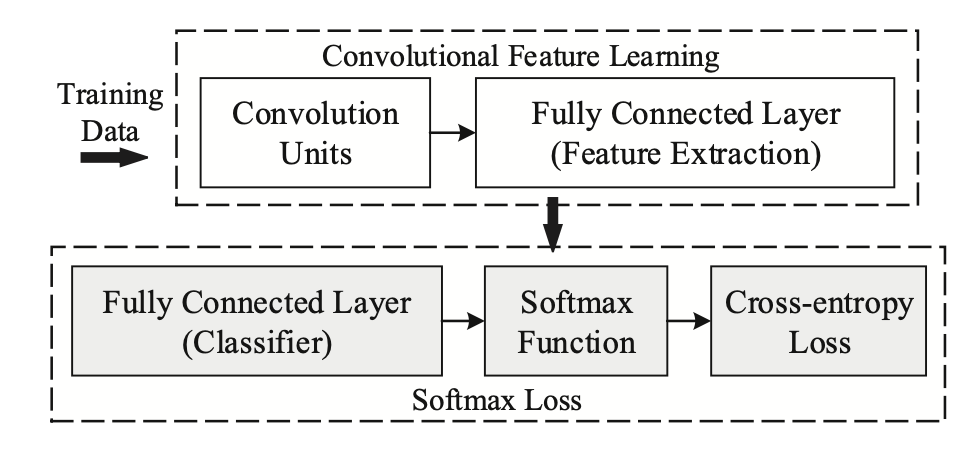
NLP
2026-01-11
问题引入 前几天在训练一个新的Transformer模型的时候,发现怎么训都不收敛了。经过一番debug,发现是在做Self Attention的时候 [Math] 之后忘记除以 [Math] 了,于是重新温习了一下为什么除以 [Math] 如此重要的原因。当然,Google的T5确实是没有除以 [Math] 的,但它依然能够正常收敛,那是因为它在初始化策略上做了些调整,所以这个事情还跟初始化有关。 藉着这个机会,本文跟大家一起梳理一下模型的初始化、参数化和标准化等内容,相关讨论将主要以Transformer为心中展开。 参数初始化 采样分布 初始化自然是随机采样的的,所以这里先介绍一下常用的采样分布。一般情况下,我们都是从指定均值和方差的随机分布中进行采样来初始化。其中常用的随机分布有三个...