
论文地址: 🔖 https://arxiv.org/pdf/2107.11291 代码地址: 前言 一般来说,我们可以把姿态估计任务分成两个流派:Heatmapbased和Regressionbased。 其主要区别在于监督信息的不同,Heatmapbased方法监督模型学习的是高斯概率分布图,即把GroundTruth中每个点渲染成一张高斯热图,最后网络输出为K张特征图对应K个关键点,然后通过argmax或softargmax来获取最大值点作为估计结果。这种方法由于需要渲染高斯热图,且由于热图中的最值点直接对应了结果,不可避免地需要维持一个相对高分辨率的热图(常见的是64x64,再小的话误差下界过大会造成严重的精度损失),因此也就自然而然导致了很大的计算量和内存开销。 Regression...
问题定义 多元二次多项式,维度为 n ,那么可以用以下公式描述该函数: [Formula] 其中 a_{i,j} 为二次项系数,共有 n^2 项, 1≤i,j≤n ,且所有的 a 不全为0,即 ∃a_{i,j}≠0 ; b_k 为一次项系数,共 n 项, 1≤k≤n ; c 为常数项。 记 f(x)=[x_1,x_2,...,x_n]^T ,则上述函数可以写作二次型的形式: 转化过程中A,b满足: A 为n阶对称方阵, A_{i,j}=a_{i,j} 因为 ∃a_{i,j}≠0 ,A不为零矩阵 b_i=b_i 为了后续计算简便,我们将二次型稍作改动: [Formula] 我们的目标就是寻找该函...
基本概念 方向导数:是一个数;反映的是 f(x,y) 在 P_0 点沿方向 v 的变化率。 偏导数:是多个数(每元有一个);是指多元函数沿坐标轴方向的方向导数,因此二元函数就有两个偏导数。 偏导函数:是一个函数;是一个关于点的偏导数的函数。 梯度:是一个向量;每个元素为函数对一元变量的偏导数;它既有大小(其大小为最大方向导数),也有方向。 方向导数 反映的是 f(x,y) 在 P_0 点沿方向 v 的变化率。 例子如下: 题目 设二元函数 f(x, y) = x^2 + y^2 ,分别计算此函数在点 (1, 2) 沿方向 w=\{3, 4\} 与方向 u=\{1, 0\} 的方向导数。 解: ...
3D Model
2026-01-11
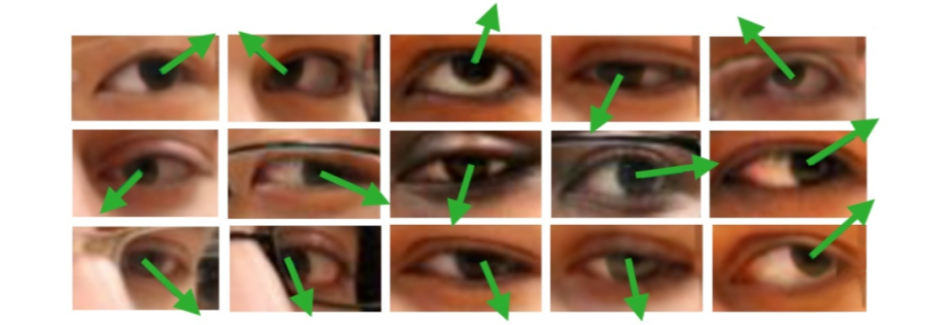
概述 问题定义 广义的 Gaze Estimation 泛指与眼球、眼动、视线等相关的研究,因此有不少做 saliency 和 egocentric 的论文也以 gaze 为关键词。而本文介绍的 Gaze Estimation 主要以眼睛图像或人脸图像为处理对象,估算人的视线方向或注视点位置, 如下图所示。 gaze角度的表示一般使用一个3d向量作为表示,也可以转换为pitch 和yaw角度,具体可参考 Model Gaze模型一般使用回归模型,所以这里基本只介绍一些在gaze model中使用的小技巧 Rle Loss 实际问题
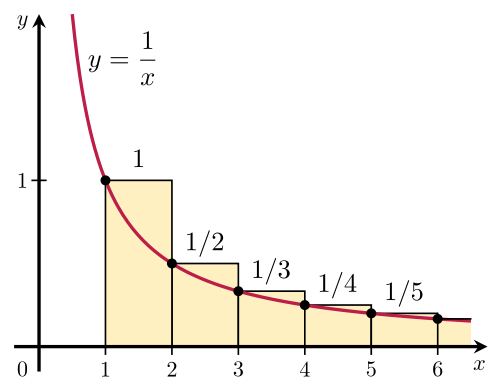
调和级数记住下面的公式就够了: [Formula] 证明方法就是下面这张图

一、泊松分布 日常生活中,大量事件是有固定频率的。 某医院平均每小时出生3个婴儿 某公司平均每10分钟接到1个电话 某超市平均每天销售4包xx牌奶粉 某网站平均每分钟有2次访问 它们的特点就是,我们可以预估这些事件的总数,但是没法知道具体的发生时间。已知平均每小时出生3个婴儿,请问下一个小时,会出生几个? 有可能一下子出生6个,也有可能一个都不出生。这是我们没法知道的。 泊松分布就是描述某段时间内,事件具体的发生概率。 [Formula] 上面就是泊松分布的公式。等号的左边, P 表示概率, N 表示某种函数关系, t 表示时间, n 表示数量,1小时内出生3个婴儿的概率,就表示为 P(N(1...
Computer Vision
2026-01-11
mAP定义及相关概念 mAP: mean Average Precision, 即各类别AP的平均值 AP: PR曲线下面积,后文会详细讲解 PR曲线: PrecisionRecall曲线 Precision: TP / (TP + FP) Recall: TP / (TP + FN) TP: IoU0.5的检测框数量(同一Ground Truth只计算一次) FP: IoU= 0, 0.1, 0.2, ..., 1共11个点时的Precision最大值,然后AP就是这11个Precision的平均值。 在VOC2010及以后,需要针对每一个不同的Recall值(包括0和1),选取其大于等于这些Recall值时的Precision最大值,然后计算PR曲线下面积作为AP值。 mAP计算示例 假...
NLP
2026-01-11
概述 HiPPO(Highorder Polynomial Projection Operators)是目前大热的structured state space model (S4)及其后续工作的backbone. State space mode主要是控制学科里的内容,最近被引入深度学习领域来解决长距离依赖问题。长距离依赖建模的核心问题是如何通过有限的memory来尽可能记住之前所有的历史信息。当前的主流序列建模模型(即Transformer和RNN) 存在着普遍的遗忘问题 fixedsize context windows: Transformer的window size通常是有限的,一般来说quadratic的attention最多建模到大约10k的token就到计算极限了 vanish...
Deep Learning
2026-01-11

Random erasing data augmentation 论文名称:Random erasing data augmentation 论文地址:https://arxiv.org/pdf/1708.04896v2.pdf 随机擦除增强,非常容易理解。作者提出的目的主要是模拟遮挡,从而提高模型泛化能力,这种操作其实非常make sense,因为我把物体遮挡一部分后依然能够分类正确,那么肯定会迫使网络利用局部未遮挡的数据进行识别,加大了训练难度,一定程度会提高泛化能力。其也可以被视为add noise的一种,并且与随机裁剪、随机水平翻转具有一定的互补性,综合应用他们,可以取得更好的模型表现,尤其是对噪声和遮挡具有更好的鲁棒性。具体操作就是:随机选择一个区域,然后采用随机值进行覆盖,模拟遮...
Deep Learning
2026-01-11

DropBlock 论文题目:DropBlock: A regularization method for convolutional networks 论文地址:https://arxiv.org/abs/1810.12890 由于dropBlock其实是dropout在卷积层上的推广,故很有必须先说明下dropout操作。 dropout,训练阶段在每个minibatch中,依概率P随机屏蔽掉一部分神经元,只训练保留下来的神经元对应的参数,屏蔽掉的神经元梯度为0,参数不参数与更新。而测试阶段则又让所有神经元都参与计算。 dropout操作流程:参数是丢弃率p 1)在训练阶段,每个minibatch中,按照伯努利概率分布(采样得到0或者1的向量,0表示丢弃)随机的丢弃一部分神经元(即神经元...