
Hough Voting 本文的标题是Deep Hough Voting,先来说一下Hough Voting。 用Hough变换检测直线大家想必都听过:对于一条直线,可以使用(r, θ)两个参数进行描述,那么对于图像中的一点,过这个点的直线有很多条,可以生成一系列的(r, θ),在参数平面内就是一条曲线,也就是说,一个点对应着参数平面内的一个曲线。那如果有很多个点,则会在参数平面内生成很多曲线。那么,如果这些点是能构成一条直线的,那么这条直线的参数(r, θ)就在每条曲线中都存在,所以看起来就像是多条曲线相交在(r,θ)。可以用多条曲线投票的方式来看,其他点都是很少的票数,而(r,θ)则票数很多,所以直线的参数就是(r,θ)。 所以Hough变换的思想就是在于,在参数空间内进行投票,投票得数...
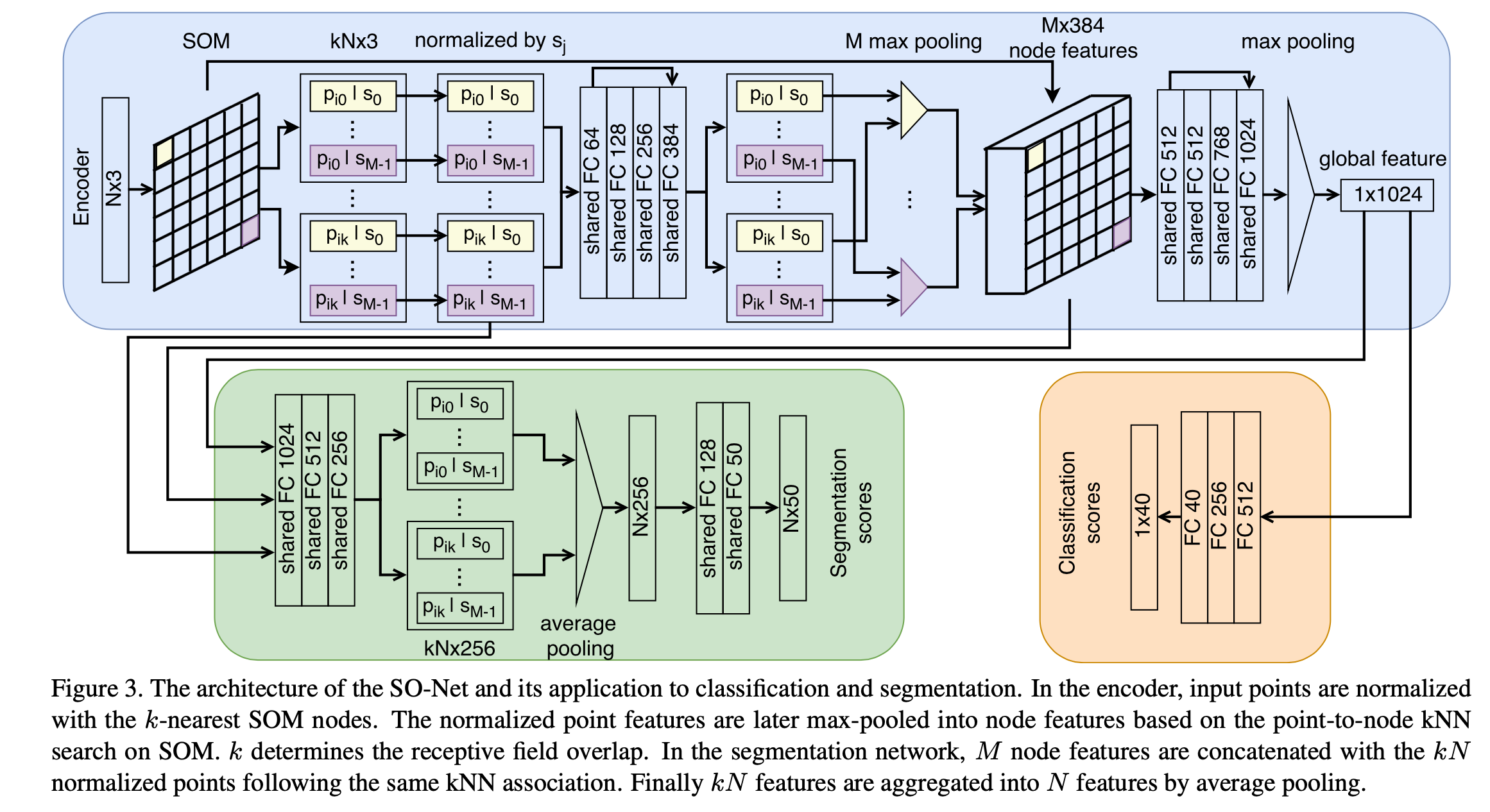
概括 针对一些网络在处理point cloud时的缺点,如:不能对点的空间分布进行建模(例如PointNet++,只是能获取局部信息不能得到局部区域之间的空间关系),提出了SONet。SO的含义是利用Selforganizing map的Net。 结果:它具有能够对点的空间分布进行建模、层次化特征提取、可调节的感受野范围的优点,并能够用于多种任务如重建、分类、分割等等。取得了相似或超过SOTA的性能,因为可并行化和架构简单使得训练速度很快。 贡献: TODO IDEA:作者发现将CNN直接用于SOM图上性能不升反降,为什么(推测:可能是SOM的2D map并不是保持了原本的空间对应关系,可能nodes之间是乱序的,导致用conv2d时精度反而降低)? 难点 如何对local regions之...
3D Model
2026-01-11
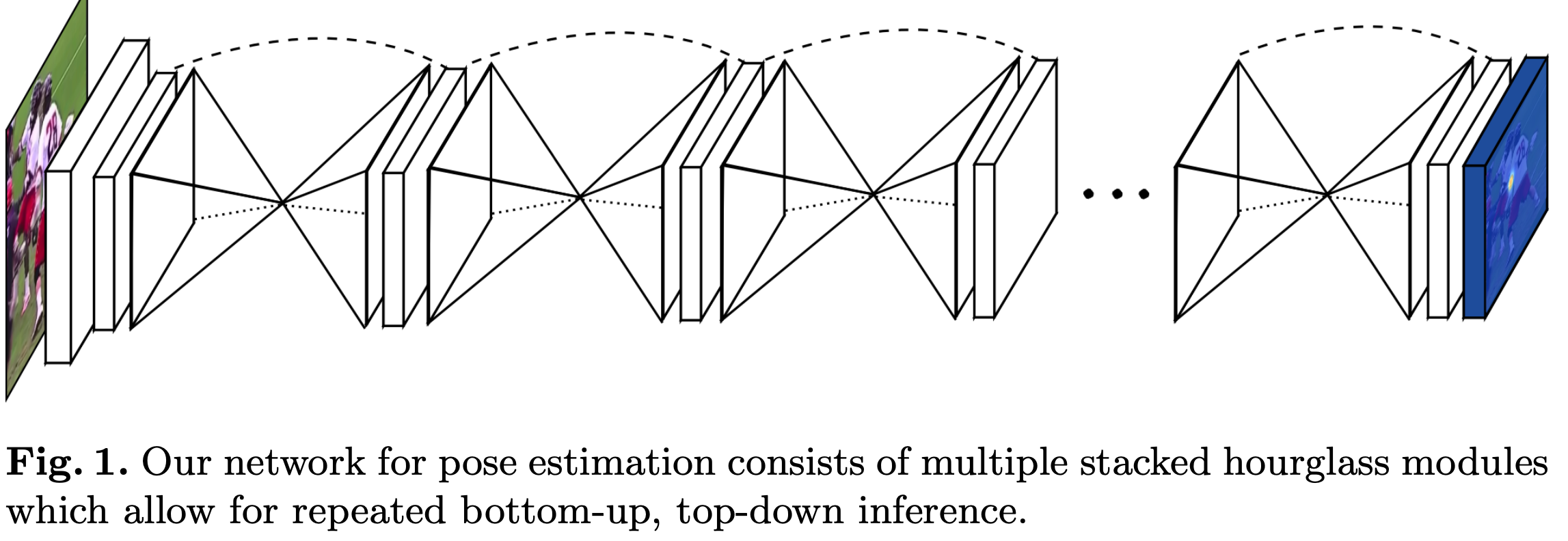
论文介绍了一种新的网络结构用于人体姿态检测,作者在论文中展现了不断重复bottomup、topdown过程以及运用intermediate supervison(中间监督)对于网络性能的提升,下面来介绍Stacked Hourglass Networks. 简介 理解人类的姿态对于一些高级的任务比如行为识别来说特别重要,而且也是一些人机交互任务的基础。作者提出了一种新的网络结构Stacked Hourglass Networks来对人体的姿态进行识别,这个网络结构能够捕获并整合图像所有尺度的信息。之所以称这种网络为Stacked Hourglass Networks,主要是它长得很像堆叠起来的沙漏,如下图所示: 这种堆叠在一起的Hourglass模块结构是对称的,bottomup过程将图片从...
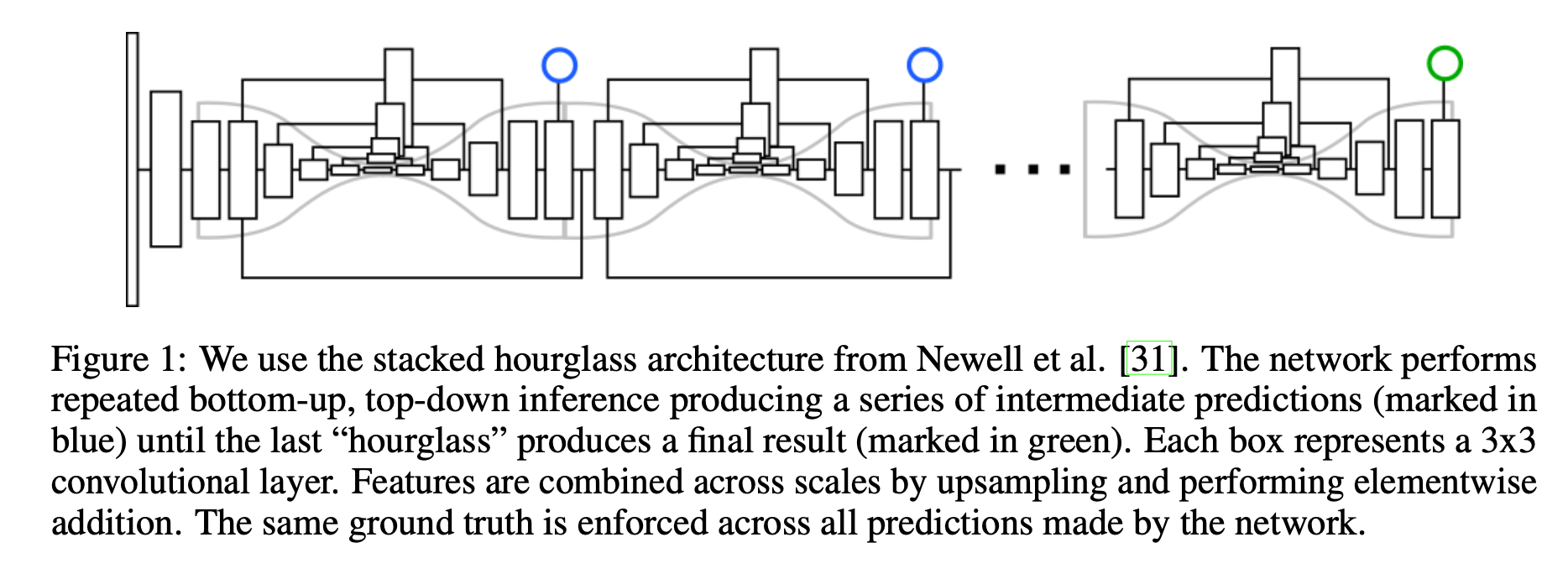
简介 作者认为许多计算机视觉的任务可以看作是检测和分组问题检测一些小的单元,然后将它们组合成更大的单元,例如,多人目标检测可以通过检测人的关节点然后再将它们进行分组(属于同一个人的关节点为一组)解决;实例分割问题可以看作是检测一些相关的像素然后将它们组合成一个目标实例。 Associative Embedding是一种表示关节检测和分组任务的输出的新方法,其基本思想是为每次检测引入一个实数,用作识别对象所属组的“tag”,换句话说,标签将每个检测与同一组中的其他检测相关联。作者使用一个损失函数使得如果相应的检测属于ground truth中的相同组则促使这一对标签具有相似的值。需要注意的是,这里标签具体的值并不重要,重要的是不同标签之间的差异。 这篇其实是源自Stacked Hourglas...
Computer Vision
2026-01-11

空洞卷积 Dilated/Atrous Convolution 或者是 Convolution with holes 从字面上就很好理解,是在标准的 convolution map 里注入空洞,以此来增加 reception field。相比原来的正常convolution,dilated convolution 多了一个 hyperparameter 称之为 dilation rate 指的是kernel的间隔数量(e.g. 正常的 convolution 是 dilatation rate 1)。 一个简单的例子 一维情况下空洞卷积的公式如下 [Formula] 不过光理解他的工作原理还是...
Computer Vision
2026-01-11
PA Pixel Accuracy(PA,像素精度):这是最简单的度量,为标记正确的像素占总像素的比例。 [公式] 图像中共有k+1(包含背景)类, p_{ii} 表示将第i类分成第 i 类的像素数量(正确分类的像素数量), p_{ij} 表示将第 i 类分成第 j 类的像素数量(所有像素数量) 因此该比值表示正确分类的像素数量占总像素数量的比例。 优点:简单 缺点:如果图像中大面积是背景,而目标较小,即使将整个图片预测为背景,也会有很高的PA得分,因此该指标不适用于评价以小目标为主的图像分割效果。 MPA Mean Pixel Accuracy(MPA,均像素精度):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。 [公式] MIoU Mean Interse...
3D Model
2026-01-11

整体流程: [代码] 0. 数据预处理 这个步骤主要是crop四路数据,及生成后续步骤所需要的yaml文件。 1. 四路相机与双路相机标定 内参标定 [代码] 这里主要的函数就是: pts = cv2.findChessboardCorners(img, (board_width, board_height))[1] cv2.cornerSubPix(gray, pts, (12, 12), (1, 1), (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_COUNT, 30, 0.1)) det, intr, dist, _, _ = cv2.calibrateCamera(obj_pts, img_pts, self.imgSize, None, No...
Computer Vision
2026-01-11
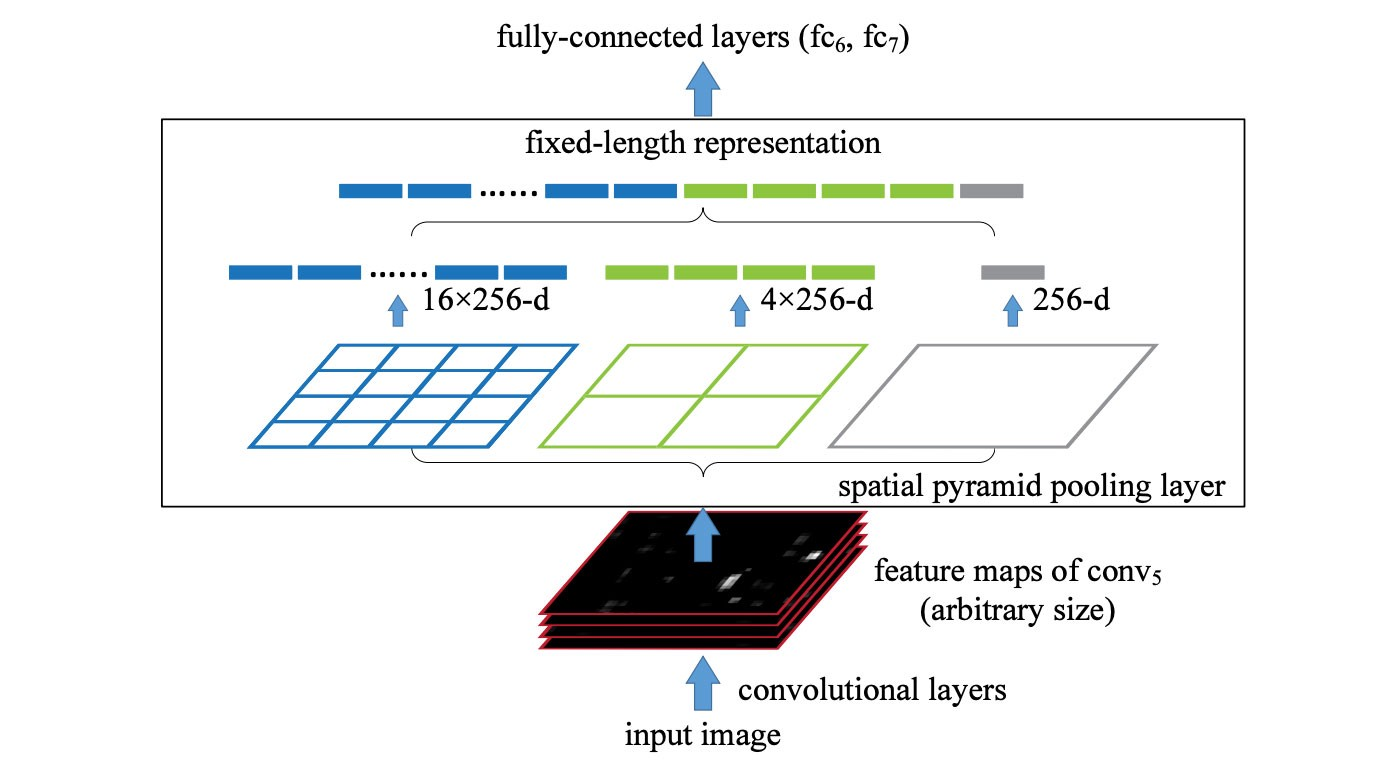
SPP (spatial pyramid pooling layer) SPP applies a slightly different strategy in detecting objects of different scales. It replaces the last pooling layer (after the last convolutional layer) with a spatial pyramid pooling layer. The feature maps are spatially divided into m×m bins with m, say, equals 1, 2, and 4 respectively. Then a maximum pool i...
Computer Vision
2026-01-11

原理分析 网络架构: 本文的任务是Object detection,用到的工具是Transformers,特点是Endtoend。 目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他...
NLP
2026-01-11

摘掉Softmax 制约Attention性能的关键因素,其实是定义里边的Softmax!事实上,简单地推导一下就可以得到这个结论。 [Math] 这一步我们得到一个 [Math] 的矩阵,就是这一步决定了Attention的复杂度是 [Math] ;如果没有Softmax,那么就是三个矩阵连乘 [Math] ,而矩阵乘法是满足结合率的,所以我们可以先算 [Math] ,得到一个 [Math] 的矩阵,然后再用 [Math] 左乘它,由于 [Math] ,所以这样算大致的复杂度只是 [Math] (就是 [Math] 左乘那一步占主导)。 也就是说,去掉Softmax的Attention的复杂度可以降到最理想的线性级别 [Math] !这显然就是我们的终极追求:Linear Attentio...
Computer Vision
2026-01-11
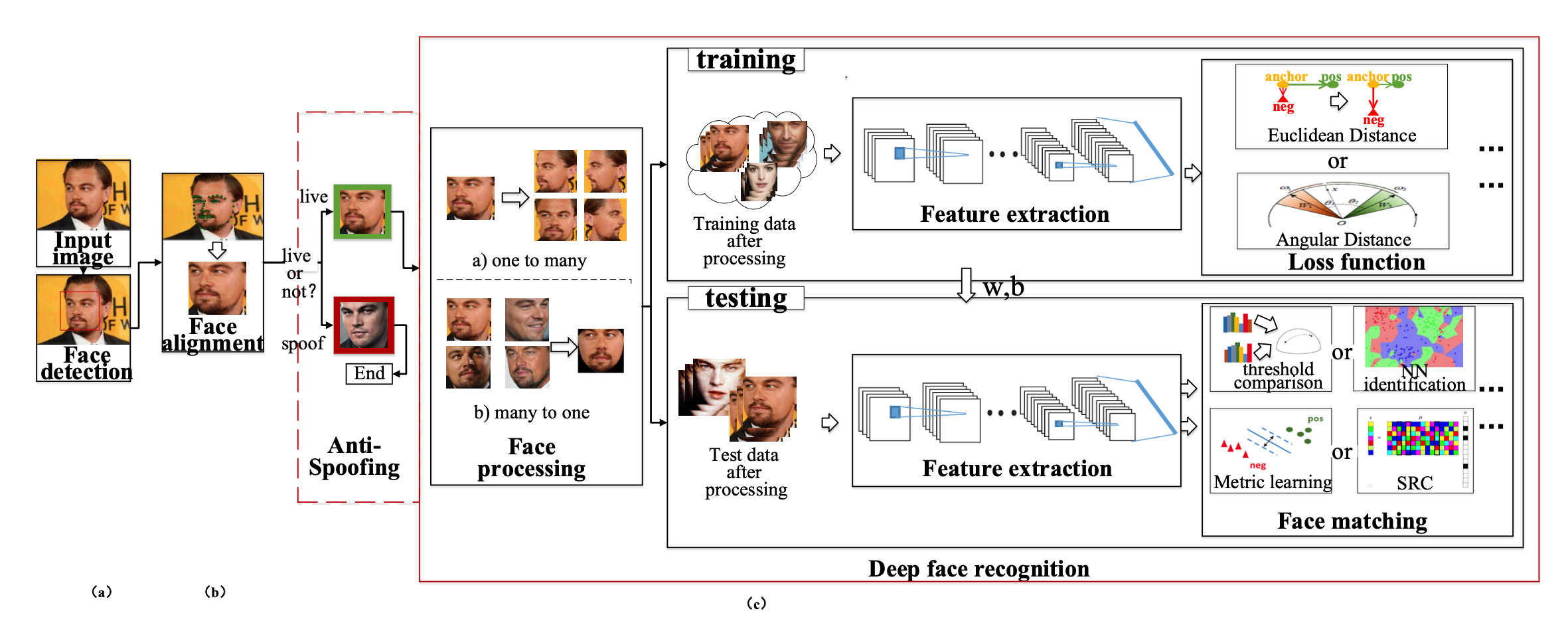
简介 一个完整的人脸识别系统包含以下几个模块 Face Detection: 人脸检测 Face Alignment:基于人脸关键点坐标对齐到正则坐标系下坐标 Face Recognition:基于对齐人脸进行识别 人脸识别的算法流程 人脸的识别流程:面部姿态处理(处理姿态,亮度,表情,遮挡),特征提取,人脸比对。 面部处理 face processing 这部分主要对姿态(主要)、亮度、表情、遮挡进行处理,可提升FR模型性能 主要包含两种处理方式: 1. "Onetomany Augmentation": 从单个图像生成不同姿态的图像,使模型学习到姿态不变性的表示 1. "Manytoone Normalization": 从多个不同姿态的图像中恢复人脸图像的标准视图 特征提取 Backb...
NLP
2026-01-11

概述 本文介绍一个比较有意思的高效Transformer工作——来自Google的《Transformer Quality in Linear Time》,经过细读之后,笔者认为论文里边真算得上是“惊喜满满”了~ 什么样的结果值得我们用“惊喜”来形容?有没有言过其实?我们不妨先来看看论文做到了什么: 1. 提出了一种新的Transformer变体,它依然具有二次的复杂度,但是相比标准的Transformer,它有着更快的速度、更低的显存占用以及更好的效果; 1. 提出一种新的线性化Transformer方案,它不但提升了原有线性Attention的效果,还保持了做Decoder的可能性,并且做Decoder时还能保持高效的训练并行性。 说实话,笔者觉得做到以上任意一点都是非常难得的,而这篇论...