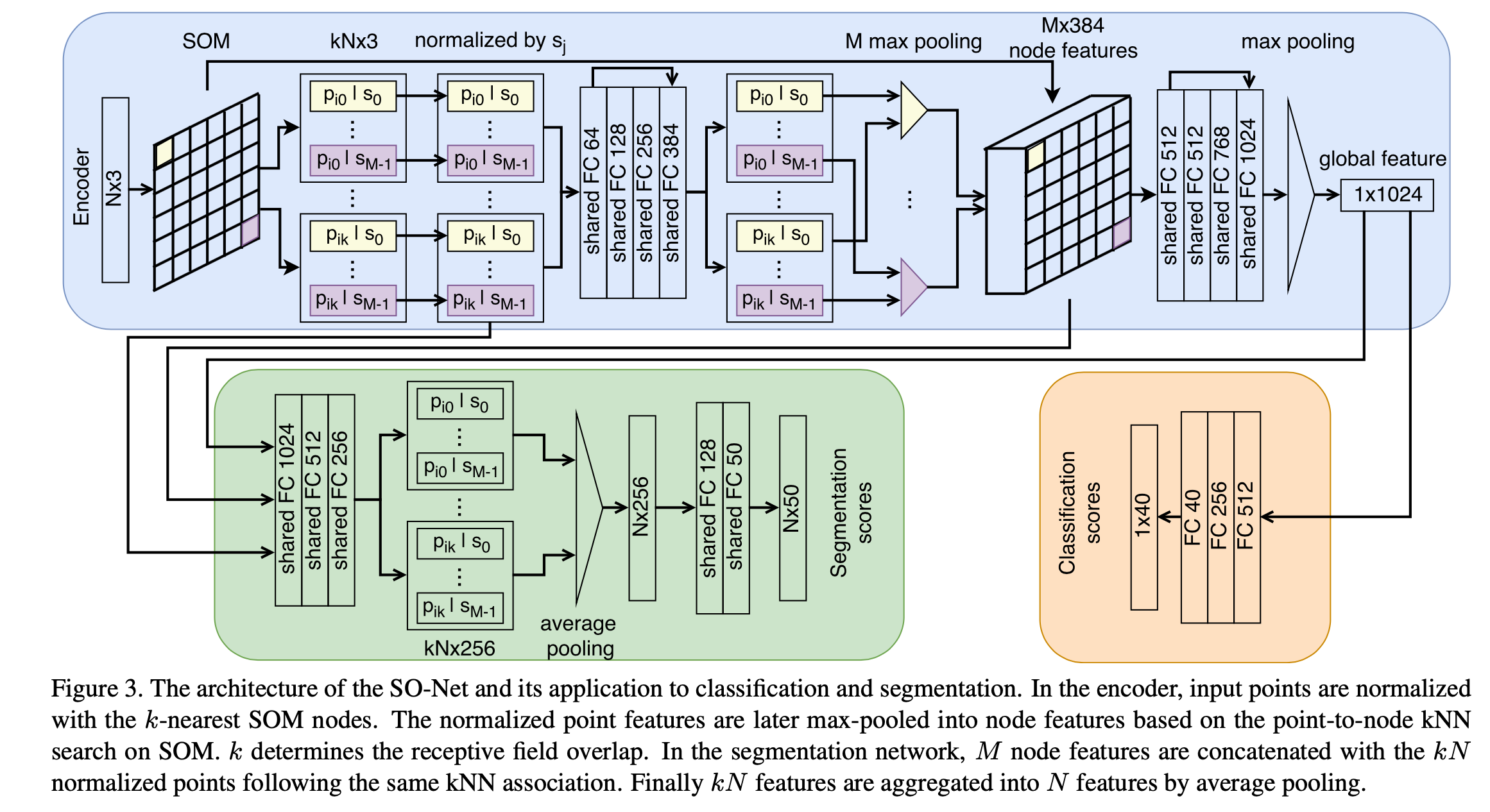
概括 针对一些网络在处理point cloud时的缺点,如:不能对点的空间分布进行建模(例如PointNet++,只是能获取局部信息不能得到局部区域之间的空间关系),提出了SONet。SO的含义是利用Selforganizing map的Net。 结果:它具有能够对点的空间分布进行建模、层次化特征提取、可调节的感受野范围的优点,并能够用于多种任务如重建、分类、分割等等。取得了相似或超过SOTA的性能,因为可并行化和架构简单使得训练速度很快。 贡献: TODO IDEA:作者发现将CNN直接用于SOM图上性能不升反降,为什么(推测:可能是SOM的2D map并不是保持了原本的空间对应关系,可能nodes之间是乱序的,导致用conv2d时精度反而降低)? 难点 如何对local regions之...
3D Model
2026-01-11
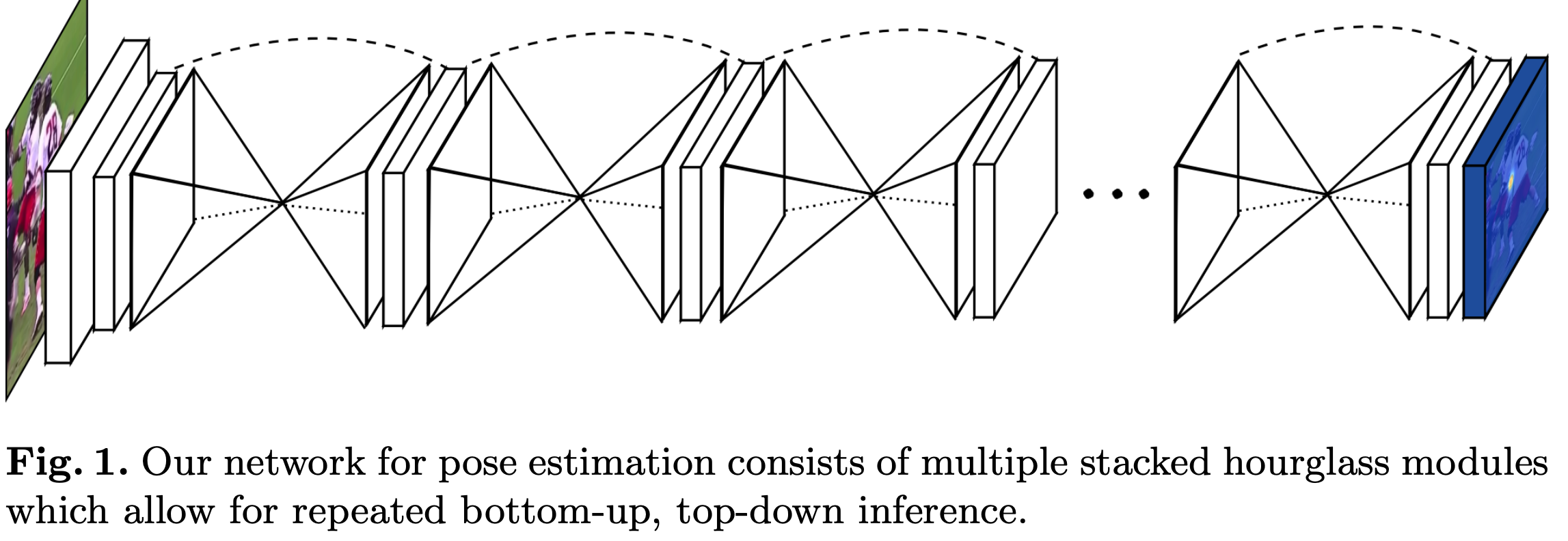
论文介绍了一种新的网络结构用于人体姿态检测,作者在论文中展现了不断重复bottomup、topdown过程以及运用intermediate supervison(中间监督)对于网络性能的提升,下面来介绍Stacked Hourglass Networks. 简介 理解人类的姿态对于一些高级的任务比如行为识别来说特别重要,而且也是一些人机交互任务的基础。作者提出了一种新的网络结构Stacked Hourglass Networks来对人体的姿态进行识别,这个网络结构能够捕获并整合图像所有尺度的信息。之所以称这种网络为Stacked Hourglass Networks,主要是它长得很像堆叠起来的沙漏,如下图所示: 这种堆叠在一起的Hourglass模块结构是对称的,bottomup过程将图片从...
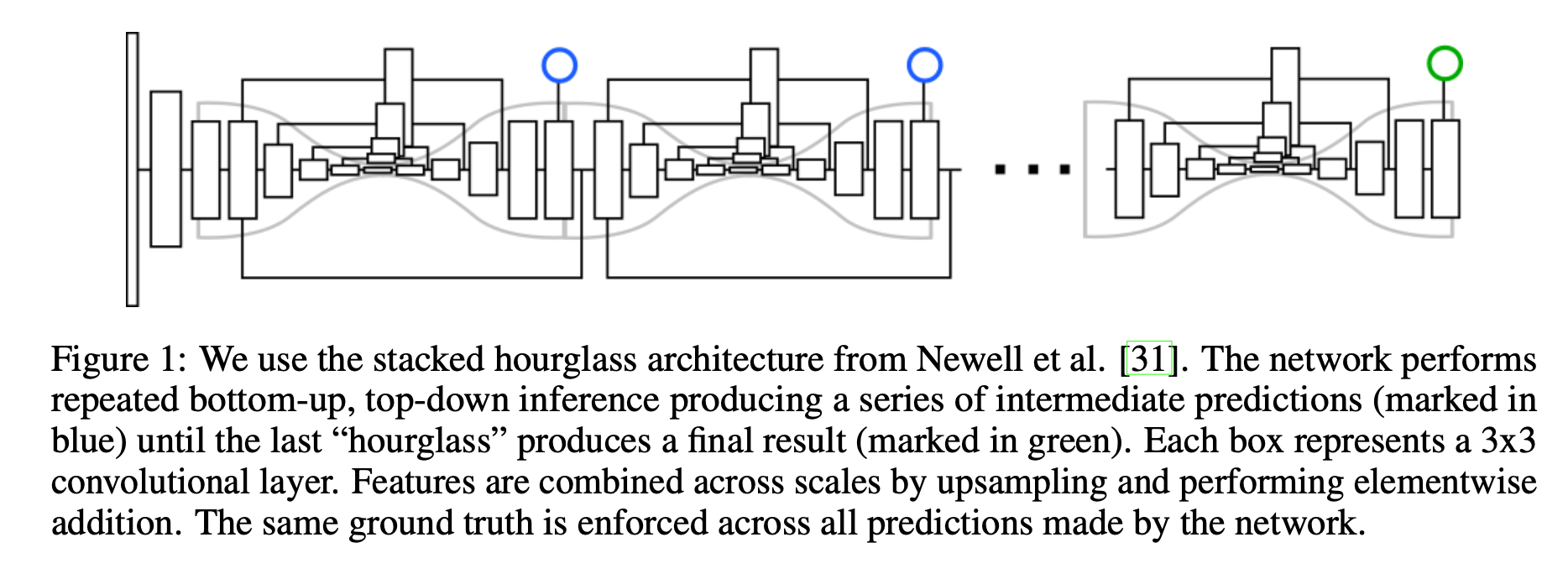
简介 作者认为许多计算机视觉的任务可以看作是检测和分组问题检测一些小的单元,然后将它们组合成更大的单元,例如,多人目标检测可以通过检测人的关节点然后再将它们进行分组(属于同一个人的关节点为一组)解决;实例分割问题可以看作是检测一些相关的像素然后将它们组合成一个目标实例。 Associative Embedding是一种表示关节检测和分组任务的输出的新方法,其基本思想是为每次检测引入一个实数,用作识别对象所属组的“tag”,换句话说,标签将每个检测与同一组中的其他检测相关联。作者使用一个损失函数使得如果相应的检测属于ground truth中的相同组则促使这一对标签具有相似的值。需要注意的是,这里标签具体的值并不重要,重要的是不同标签之间的差异。 这篇其实是源自Stacked Hourglas...
Generative Model
2026-01-11

💡 原本随机采样的DDPM模型中,也隐含了一个确定性的采样过程DDIM,它的连续极限也是一个ODE。 细想上述过程,可以发现不管是“DDPM→DDIM”还是“SDE→ODE”,都是从随机采样模型过渡到确定性模型,而如果我们一开始的目标就是ODE,那么该过程未免显得有点“迂回”了。在本文中,笔者尝试给出ODE扩散模型的直接推导,并揭示了它与雅可比行列式、热传导方程等内容的联系。 Rectified Flow 理论推导 微分方程 像GAN这样的生成模型,它本质上是希望找到一个确定性变换,能将从简单分布(如标准正态分布)采样出来的随机变量,变换为特定数据分布的样本。flow模型也是生成模型之一,它的思路是反过来,先找到一个能将数据分布变换简单分布的可逆变换,再求解相应的逆变换来得到一个生成模型。 ...
Generative Model
2026-01-11

DDPM 有一个非常明显的问题:采样过程很慢。因为 DDPM 的反向过程利用了马尔可夫假设,所以每次都必须在相邻的时间步之间进行去噪,而不能跳过中间步骤。原始论文使用了 1000 个时间步,所以我们在采样时也需要循环 1000 次去噪过程,这个过程是非常慢的。 为了加速 DDPM 的采样过程,DDIM 在不利用马尔可夫假设的情况下推导出了 diffusion 的反向过程,最终可以实现仅采样 20~100 步的情况下达到和 DDPM 采样 1000 步相近的生成效果,也就是提速 10~50 倍。这篇文章将对 DDIM 的理论进行讲解,并实现 DDIM 采样的代码。 DDPM 的反向过程 首先我们回顾一下 DDPM 反向过程的推导,为了推导出 [Math] 这个条件概率分布,DDPM 利用贝叶斯...
3D Model
2026-01-11

整体流程: [代码] 0. 数据预处理 这个步骤主要是crop四路数据,及生成后续步骤所需要的yaml文件。 1. 四路相机与双路相机标定 内参标定 [代码] 这里主要的函数就是: pts = cv2.findChessboardCorners(img, (board_width, board_height))[1] cv2.cornerSubPix(gray, pts, (12, 12), (1, 1), (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_COUNT, 30, 0.1)) det, intr, dist, _, _ = cv2.calibrateCamera(obj_pts, img_pts, self.imgSize, None, No...
Generative Model
2026-01-11

Diffusion Models from SDE 连续扩散模型 (Continuous Diffusion Models) 将传统的离散时间扩散过程扩展到连续时间域,可以被视为一个随机过程,使用随机微分方程(SDE)来描述。其前向过程可以写成如下形式: [公式] 其中, f(x,t) 可以看成偏移系数, g(t) 可以看成是扩散系数, dw 是标准布朗运动。这个SDE 描述了数据在连续时间域内如何被噪声逐渐破坏。 这个随机过程的逆向过程存在(更准确的描述:下面的逆向时间SDE具有与正向过程SDE相同的联合分布)为 [公式] 前面我们得到了扩散过程的逆向过程可以用一个SDE描述(逆向随机过程),事实上,存在一个确定性过程 (用ODE描述)也是它的逆向过程 (更准确的描述:这个ODE过程的在任...
Generative Model
2026-01-11

💡 Flowbased Models Normalizing Flow Normalizing Flow 是一种基于变换对概率分布进行建模的模型,其通过一系列离散且可逆的变换实现任意分布与先验分布(例如标准高斯分布)之间的相互转换。在 Normalizing Flow 训练完成后,就可以直接从高斯分布中进行采样,并通过逆变换得到原始分布中的样本,实现生成的过程。(有关 Normalizing Flow 的详细理论) 从这个角度看,Normalizing Flow 和 Diffusion Model 是有一些相通的,其做法的对比如下表所示。从表中可以看到,两者大致的过程是非常类似的,尽管依然有些地方不一样,但这两者应该可以通过一定的方法得到一个比较统一的表示。 Continuous Norma...
Generative Model
2026-01-11
技术分析 从方法上来看,条件控制生成的方式分两种:事后修改(ClassifierGuidance)和事前训练(ClassifierFree)。 对于大多数人来说,一个SOTA级别的扩散模型训练成本太大了,而分类器(Classifier)的训练还能接受,所以就想着直接复用别人训练好的无条件扩散模型,用一个分类器来调整生成过程以实现控制生成,这就是事后修改的ClassifierGuidance方案;而对于“财大气粗”的Google、OpenAI等公司来说,它们不缺数据和算力,所以更倾向于往扩散模型的训练过程中就加入条件信号,达到更好的生成效果,这就是事前训练的ClassifierFree方案。 ClassifierGuidance方案最早出自《Diffusion Models Beat GANs...
Generative Model
2026-01-11

SD模型原理 SD是CompVis、Stability AI和LAION等公司研发的一个文生图模型,它的模型和代码是开源的,而且训练数据LAION5B也是开源的。SD在开源90天github仓库就收获了33K的stars,可见这个模型是多受欢迎。 SD是一个基于latent的扩散模型,它在UNet中引入text condition来实现基于文本生成图像。SD的核心来源于Latent Diffusion这个工作,常规的扩散模型是基于pixel的生成模型,而Latent Diffusion是基于latent的生成模型,它先采用一个autoencoder将图像压缩到latent空间,然后用扩散模型来生成图像的latents,最后送入autoencoder的decoder模块就可以得到生成的图像。 ...
Deep Learning
2026-01-11

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 1、Upsampling(上采样)[没有学习过程] 在FCN、Unet等网络结构中,涉及到了上采样。上采样概念:上采样指的是任何可以让图像变成更高分辨率的技术。最简单的方式是重采样和插值:将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在torch.nn中的Vision Layers里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d 0)PixelShuffl...
Generative Model
2026-01-11

ControlNet应该算是2023年文生图领域最重要的工作,它让文生图模型Stable Diffusion实现了文本之外的可控生成,让AI绘画实现了质的飞跃。这篇文章我们将简单总结一下ControlNet技术细节。 模型设计 ControlNet的模型结构如下所示,这里是直接复制一份SD的上半部分:Encoder和中间的Middle Block。 ControlNet的输入和原始的SD一样,包括noisy latents、time embedding以及text embedding。除此之外,ControlNet还需要引入额外的condition,这个condition是和原图一样大小的图像,比如canny边界图或者人体骨架图。这里并没有像SD那样采用VAE对condition进行编码,而...