
💡 引言 Trust Region Policy Optimization (TRPO) 是2015年的ICML会议上提出的一种强大的基于策略的强化学习算法。TRPO 解决了传统策略梯度方法中的一些关键问题,特别是训练不稳定和步长选择困难的问题。与传统策略梯度算法相比,TRPO 具有更高的稳健性和样本效率,能够在复杂环境中取得更好的性能。 优化基础 在深入了解 TRPO 之前,我们需要先简单回顾一些优化方法的基础知识。 梯度上升法 梯度上升法是一种迭代优化算法,用于寻找函数的局部最大值。 目标:找到使目标函数 [Math] 最大化的参数 [Math] : [公式] 梯度上升迭代过程: 1. 在当前参数 [Math] 处计算梯度: [Math] 1. 更新参数: 梯度上升法的主要问题是学习率的...
Large Model
2026-01-11

概述 Medusa 是自投机领域较早的一篇工作,对后续工作启发很大,其主要思想是 multidecoding head + tree attention + typical acceptance(threshold)。Medusa 没有使用独立的草稿模型,而是在原始模型的基础上增加多个解码头(MEDUSA heads),并行预测多个后续 token。 正常的LLM只有一个用于预测 t 时刻token的head。Medusa 在 LLM 的最后一个 Transformer层之后保留原始的 LM Head,然后额外增加多个(假设是 k 个) 可训练的Medusa Head(解码头),分别负责预测 ...
Large Model
2026-01-11

概述 MTP(Multitoken Prediction)的总体思路是:让模型使用n个独立的输出头来预测接下来的n个token,这n个独立的输出头共享同一个模型主干。这样通过解码阶段的优化,将1token的生成,转变成multitoken的生成,从而提升训练和推理的性能。 在DeepSeek之前也有几个MTP方案,其侧重点各自不同。 侧重推理时解码加速。比如论文“MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads”、论文“EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty”等。这些方案通过一次生成多个...
01背包 描述 有N件物品和一个容量为V的背包。 第i件物品的体积是vi,价值是wi。 求解将哪些物品装入背包,可使这些物品的总体积不超过背包流量,且总价值最大。 二维动态规划 f[i][j] 表示只看前i个物品,总体积是j的情况下,总价值最大是多少。 result = max(f[n][0V]) f[i][j]: 不选第i个物品:f[i][j] = f[i1][j]; 选第i个物品:f[i][j] = f[i1][jv[i]] + w[i](v[i]是第i个物品的体积) 两者之间取最大。 初始化:f[0][0] = 0 代码如下: [代码] 一维动态优化 从上面二维的情况来看,f[i] 只与f[i1]相关,因此只用使用一个一维数组[0v]来存储前一个状态。那么如何来实现呢? 第一个问题:状...
Algorithm
2026-01-11
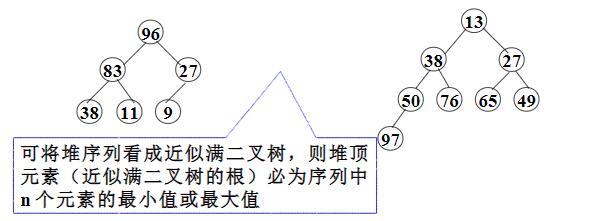
起步 heapq 模块实现了适用于Python列表的最小堆排序算法。 堆是一个树状的数据结构,其中的子节点都与父母排序顺序关系。因为堆排序中的树是满二叉树,因此可以用列表来表示树的结构,使得元素 N 的子元素位于 2N + 1 和 2N + 2 的位置(对于从零开始的索引)。 本文内容将分为三个部分,第一个部分简单介绍 heapq 模块的使用;第二部分回顾堆排序算法;第三部分分析heapq中的实现。 heapq 的使用 创建堆有两个基本的方法:heappush() 和 heapify(),取出堆顶元素用 heappop()。 heappush() 是用来向已有的堆中添加元素,一般从空列表开始构建: [代码] 如果数据已经在列表中,则使用 heapify() 进行重排: [代码] 回顾堆排序算...
计数排序、基数排序、桶排序则属于非比较排序,算法时间复杂度O(n),优于比较排序。但是也有弊端,会多占用一些空间,相当于是用空间换时间。 1. 计数排序: 计数排序的基本思想是:对每一个输入的元素a[i],确定小于 a[i] 的元素个数。所以可以直接把 a[i] 放到它输出数组中的位置上。假设有5个数小于 a[i],所以 a[i] 应该放在数组的第6个位置上。 实现代码如下: [代码] 2. 桶排序: 桶排序的基本思想是:把数组a划分为n个大小相同子区间(桶),每个子区间各自排序,最后合并。桶排序要求数据的分布必须均匀,不然可能会失效。计数排序是桶排序的一种特殊情况,可以把计数排序当成每个桶里只有一个元素的情况。 [代码] 算法实现步骤 1. 根据待排序集合中最大元素和最小元素的差值范围和映...
Algorithm
2026-01-11
题目说明 在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。 示例 1: 输入: [3,2,1,5,6,4] 和 k = 2 输出: 5 示例 2: 输入: [3,2,3,1,2,4,5,5,6] 和 k = 4 输出: 4 题解 使用快排的思想 [代码]

引言与背景 策略梯度方法是强化学习中的一种重要方法,它标志着从基于价值的方法向基于策略的方法的重要转变。之前我们主要讨论了基于价值的方法(valuebased),而策略梯度方法则直接优化策略函数(policybased),这是一个重要的进步。 当策略用函数表示时,策略梯度方法的核心思想是通过优化某些标量指标来获得最优策略。与传统的表格表示策略不同,策略梯度方法使用参数化函数 [Math] 来表示策略,其中 [Math] 是参数向量。这种表示方法也可以写成其他形式,如 [Math] 、 [Math] 或 [Math] 。 策略梯度方法具有多种优势: 更高效地处理大型状态/动作空间 具有更强的泛化能力 样本使用效率更高 策略表示:从表格到函数 当策略的表示从表格转变为函数时,存在以下几个关键区别...
💡 不断排除不存在解的区间,直至最后剩下一个 这里归纳最重要的部分: 分析题意,挖掘题目中隐含的 单调性; while (left < right) 退出循环的时候有 left == right 成立,因此无需考虑返回left还是right; 始终思考下一轮搜索区间是什么,如果是 [mid, right] 就对应 left = mid ,如果是 [left, mid 1] 就对应 right = mid 1,是保留 mid 还是 +1、−1 就在这样的思考中完成; 从一个元素什么时候不是解开始考虑下一轮搜索区间是什么 ,把区间分为 2个部分(一个部分肯定不存在目标元素,另一个部分有可能存在目标元素),问题会变得简单很多,这是一条 非常有用 的经验; 每一轮区间被划分成 2 部分,理解 区间划...

💡 GRPO相比PPO主要优势: 背景 GRPO是 DeepSeekMath model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO回顾 PPO的目标函数为: [公式] 其中: [Math] 和 [Math] 分别是当前和旧策略模型 A_t 是优势函数 [Math] 是裁剪相关的超参数 模型训练 如图1上所示,PPO需要同时训练一个Value Model [Math] 和策略模型, 同时需要reference model(通常从SFT model初始化)来限制策略模型训练保持和reference model的行为接近,而 Reward model用来计算...
Large Model
2026-01-11

概述 投机解码(Speculative Decoding)也叫预测解码/投机采样,它会利用小模型来预测大型模型的行为,从而提升模型在解码(decoding)阶段的解码效率问题,加速大型模型的执行。其核心思路如下图所示,首先以低成本的方式(以小模型为主,也有多头,检索,Early Exit 等方式)快速生成多个候选 Token(串行序列、树、多头树等),然后通过一次并行验证阶段快速验证多个 Token的正确性,只要平均每个 Step 验证的 Token 数 1,就可以一次性生成多个token,进而减少总的 Decoding 步数,实现加速的目的。 下图左侧是自回归解码模型,右侧是投机解码机制。 从本质上来说,投机解码希望在推理阶段在不大幅度改变模型的情况下,通过更好利用冗余算力来并行"投机"地...
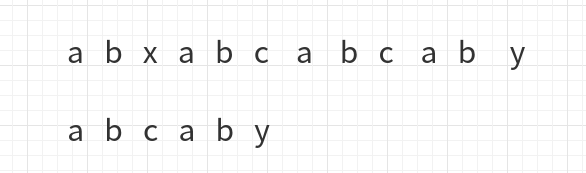
kmp算法用于字符串的模式匹配,也就是找到模式字符串在目标字符串的第一次出现的位置比如abababc那么bab在其位置1处,bc在其位置5处,我们首先想到的最简单的办法就是蛮力的一个字符一个字符的匹配,但那样的时间复杂度会是O(mn)。kmp算法保证了时间复杂度为O(m+n)。 基本原理 举个例子: 发现x与c不同后,进行移动 a与x不同,再次移动 此时比较到了c与y, 于是下一步移动成了下面这样 这一次的移动与前两次的移动不同,之前每次比较到上面长字符串的字符位置后,直接把模式字符串的首字符与它对齐,这次并没有,原因是这次移动之前,y与c对齐,但是y前边的ab是与自己的前缀ab一样,于是ab并不用再比较,直接从第三个位置开始比较,如图: 所以说kmp算法对于这种情况就直接使用当前比较字符之...