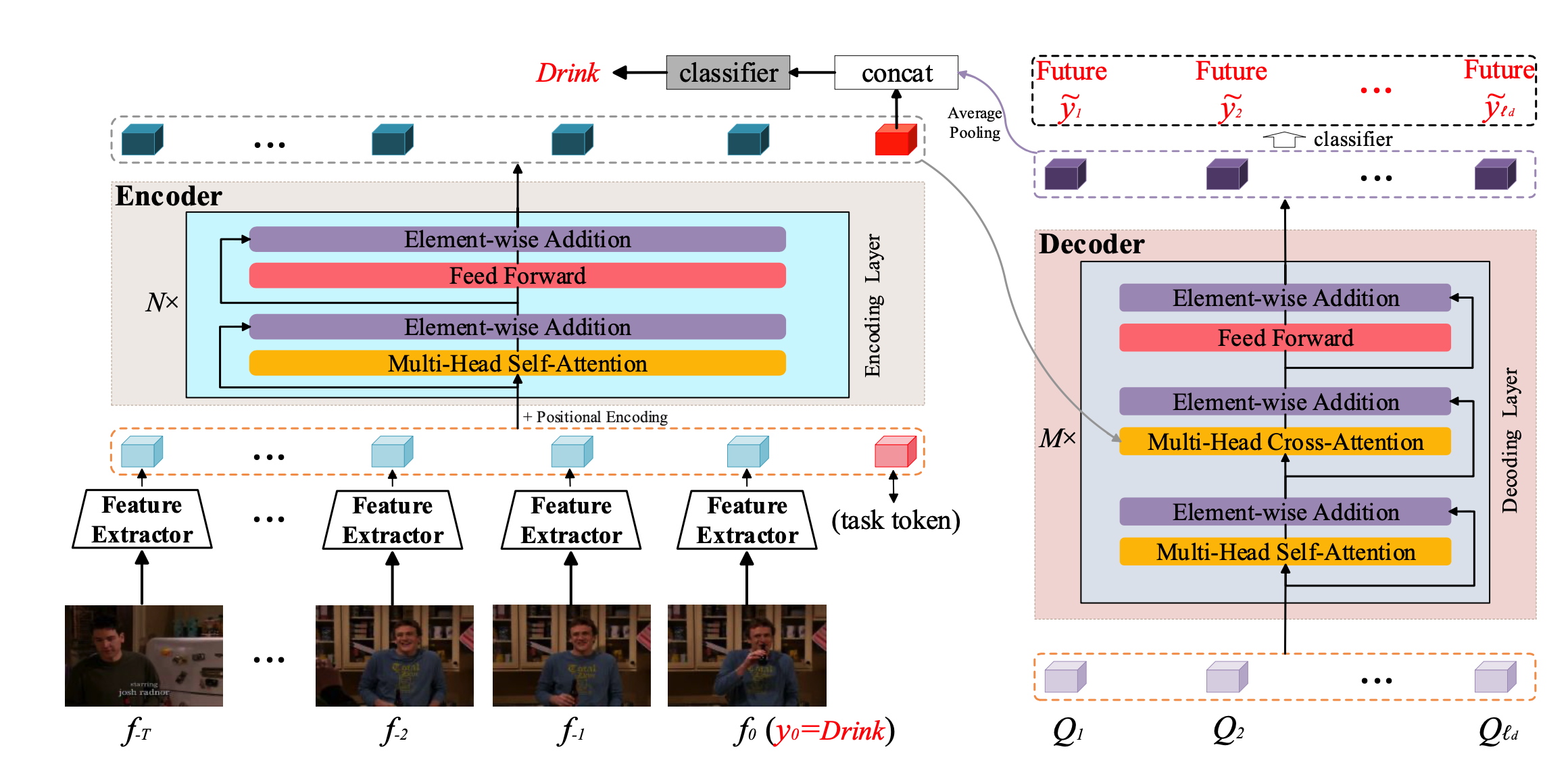
简介 之前的很多方法都是用RNN的结构去构建时序上的依赖关系,但是RNN的结构的缺点是不能并行操作,且存在梯度消失的现象。所以本文就是将之前的RNN的结构改为Transfomer的形式。延续了之前TRN的整个网络的框架,也是结合了对未来帧的预测与历史帧的表示相结合来对当前的动作进行预测。 方法 整个网络框架如上图所示, Encoder就是利用transfomer对longrange的历史和目前帧进行特征表示,其中要说明的一个点就是,这里的特征空间包含T个历史特征,当前窗口的特征以及一个task token,这个task token的作用可以从下图看出来 这幅图对比的是输入进classifier的特征与网络输入的特征的相似性,可以看出w/o task token 对应的是当前t=0时刻的特征,...
Python
2026-01-11

1. 列表和元组总结 列表和元组都是一个可以放置任意数据类型的有序集合,他们有以下共同点 列表和元组中的元素可以任意,并且都可以嵌套。 列表和元组都支持索引,且都支持负数索引,1表示最后一个元素,2表示倒数第二个元素 列表和元组都支持切片操作 都支持in关键词 都可以使用.index()、.count()、sorted()和enumerate()等方法 两者之间的相互转换,list()和tuple() 但是他们也是有区别 列表是动态的,长度大小不固定,可以随意地增加、删减或者改变元素(mutable) 元组是静态的,长度大小不固定,无法增删改,想要对已有的元组做任何“改变”,就只能开辟一块内存,创建新的元组 2. 列表和元组存储方式的差异 由于列表是动态的;元组是静态的,不可变的。这样的差异...
Python
2026-01-11
生成器 什么是生成器? 通过列表生成式,我们可以直接创建一个列表,但是,受到内存限制,列表容量肯定是有限的,而且创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。 所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间,在Python中,这种一边循环一边计算的机制,称为生成器:generator 生成器是一个特殊的程序,可以被用作控制循环的迭代行为,python中生成器是迭代器的一种,使用yield返回值函数,每次调用yield会暂停,而可以使用next()函数和send()函数恢复生成器。 生成器类似于返回值为数组的一...
Python
2026-01-11
概念 可变对象与不可变对象的区别在于对象本身是否可变。 python内置的一些类型中 可变对象:list dict set 不可变对象:tuple string int float bool 举一个例子 [代码] 上面例子很直观地展现了,可变对象是可以直接被改变的,而不可变对象则不可以 地址问题 下面我们来看一下可变对象的内存地址变化 [代码] 我们可以看到,可变对象变化后,地址是没有改变的 如果两个变量同时指向一个地址 1.可变对象 [代码] 我们可以看到,改变a则b也跟着变,因为他们始终指向同一个地址 2.不可变对象 [代码] 我们可以看到,a改变后,它的地址也发生了变化,而b则维持原来的地址,原来地址中的内容也没有发生变化 作为函数参数 1.可变对象 [代码] 我们可以看到,可变对象作...
Python
2026-01-11
概述 python采用的是引用计数机制为主,标记清除和分代收集两种机制为辅的策略。 引用计数 Python语言默认采用的垃圾收集机制是『引用计数法 Reference Counting』,该算法最早George E. Collins在1960的时候首次提出,50年后的今天,该算法依然被很多编程语言使用。 『引用计数法』的原理是:每个对象维护一个ob_ref字段,用来记录该对象当前被引用的次数,每当新的引用指向该对象时,它的引用计数ob_ref加1,每当该对象的引用失效时计数ob_ref减1,一旦对象的引用计数为0,该对象立即被回收,对象占用的内存空间将被释放。 它的缺点是需要额外的空间维护引用计数,这个问题是其次的,不过最主要的问题是它不能解决对象的“循环引用”,因此,也有很多语言比如Jav...

Pycharm 的图形化界面虽然好用,但是在某些场景中,是无法使用的。而 Python 本身已经给我们提供了一个调试神器 pdb. 准备文件 在调试之前先将这两个文件准备好(做为演示用),并放在同级目录中。 utils.py [代码] pdb_demo.py [代码] 进入调试模式 主要有两种方法 做为脚本调用,方法很简单,就像正常执行python脚本一样,只是多加了m pdb [代码] 使用这个方式进入调试模式,会在脚本的第一行开始单步调试。 对于单文件的脚本并没有什么问题,如果是一个大型的项目,项目里有很多的文件,使用这种方式只能大大降低我们的效率。 一般情况下,都会直接在你需要的地方打一个断点,那如何打呢? 只需在你想要打断点的地方加上这两行。 [代码] 然后执行时,也不需要再指定m ...
Python
2026-01-11
通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”,继承的过程,就是从一般到特殊的过程。在某些 OOP 语言中,一个子类可以继承多个基类。但是一般情况下,一个子类只能有一个基类,要实现多重继承,可以通过多级继承来实现 python2中经典类和新式类的继承方式不同,经典类采用深度优先搜索的继承,新式类采用的是广度优先搜索的继承方式 python3中经典类和新式类的继承方式都采用的是都采用广度优先搜索的继承方式 [代码] [代码] 举个例子来说明:现有4个类,A,B,C,D类,D类继承于B类和C类,B类与C类继承于A类。class D(B,C) 实例化D类 深度优先 现在构造函数的继承情况为: 若D类有构造函数,则重写所有父类的继承 若D类没有构造函数,B类有...
3D Model
2026-01-11

整体流程: [代码] 0. 数据预处理 这个步骤主要是crop四路数据,及生成后续步骤所需要的yaml文件。 1. 四路相机与双路相机标定 内参标定 [代码] 这里主要的函数就是: pts = cv2.findChessboardCorners(img, (board_width, board_height))[1] cv2.cornerSubPix(gray, pts, (12, 12), (1, 1), (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_COUNT, 30, 0.1)) det, intr, dist, _, _ = cv2.calibrateCamera(obj_pts, img_pts, self.imgSize, None, No...
Python
2026-01-11
Python程序中存储的所有数据都是对象,每一个对象有一个身份,一个类型和一个值。 看变量的实际作用,执行a = 8 这行代码时,就会创建一个值为8的int对象。 变量名是对这个"一个值为8的int对象"的引用。(也可以简称a绑定到8这个对象) 1、可以通过id()来取得对象的身份 这个内置函数,它的参数是a这个变量名,这个函数返回的值 是这个变量a引用的那个"一个值为8的int对象"的内存地址。 [代码] 2、可以通过type()来取得a引用对象的数据类型 [代码] 3、对象的值 当变量出现在表达式中,它会被它引用的对象的值替代。 总结:类型是属于对象,而不是变量。变量只是对对象的一个引用。 对象有可变对象和不可变对象之分。 Python函数传递参数到底是传值还是引用? 传值、引用这个是c...
NLP
2026-01-11

取代RNN——Transformer 在介绍Transformer前我们来回顾一下RNN的结构 对RNN有一定了解的话,一定会知道,RNN有两个很明显的问题 效率问题:需要逐个词进行处理,后一个词要等到前一个词的隐状态输出以后才能开始处理 如果传递距离过长还会有梯度消失、梯度爆炸和遗忘问题 为了缓解传递间的梯度和遗忘问题,设计了各种各样的RNN cell,最著名的两个就是LSTM和GRU了 LSTM (Long Short Term Memory) GRU (Gated Recurrent Unit) 但是,引用网上一个博主的比喻,这么做就像是在给马车换车轮,为什么不直接换成汽车呢? 于是就有了Transformer。Transformer 是Google Brain 2017的提出的一篇工...
Generative Model
2026-01-11

SD模型原理 SD是CompVis、Stability AI和LAION等公司研发的一个文生图模型,它的模型和代码是开源的,而且训练数据LAION5B也是开源的。SD在开源90天github仓库就收获了33K的stars,可见这个模型是多受欢迎。 SD是一个基于latent的扩散模型,它在UNet中引入text condition来实现基于文本生成图像。SD的核心来源于Latent Diffusion这个工作,常规的扩散模型是基于pixel的生成模型,而Latent Diffusion是基于latent的生成模型,它先采用一个autoencoder将图像压缩到latent空间,然后用扩散模型来生成图像的latents,最后送入autoencoder的decoder模块就可以得到生成的图像。 ...
Deep Learning
2026-01-11

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 1、Upsampling(上采样)[没有学习过程] 在FCN、Unet等网络结构中,涉及到了上采样。上采样概念:上采样指的是任何可以让图像变成更高分辨率的技术。最简单的方式是重采样和插值:将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在torch.nn中的Vision Layers里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d 0)PixelShuffl...