堆和优先队列的关系 这是一个非常经典且核心的计算机科学概念问题。一言以蔽之: 优先队列(Priority Queue)是逻辑接口(ADT),而堆(Heap)是实现这个接口最高效的物理数据结构。 它们的关系可以类比为 “接口(Interface)” 与 “实现类(Implementation)” 的关系,或者 “汽车(功能)”与 “发动机(核心组件)” 的关系。 优先队列 (Priority Queue) —— 逻辑层 (ADT) 定义 :它是一种 抽象数据类型 (Abstract Data Type, ADT) 。它定义了数据的 行为 ,而不是数据的存储方式。 规则 :普通的队列是“先进先出”(FIFO),而优先队列是 “优先级最高的先出” 。 核心操作 : insert(item, priority) : 插入一个带优先级的元素。 deleteMax() 或 deleteMin() : 取出并删除优先级最高(或最低)的元素。 peek() : 查看优先级最高的元素。 堆 (Heap) —— 物理层 (Data Structure) 定义 :它是一种具体的 数据结构 。通常指 二叉堆...
引入 在具体讲何为「背包 dp」前,先来看如下的例题: 题意概要:有 \( 𝑛\) 个物品和一个容量为 \( 𝑊\) 的背包,每个物品有重量 \(𝑤_𝑖\) 和价值 \(𝑣_𝑖\) 两种属性,要求选若干物品放入背包使背包中物品的总价值最大且背包中物品的总重量不超过背包的容量. 在上述例题中,由于每个物体只有两种可能的状态(取与不取),对应二进制中的 0 和 1,这类问题便被称为「0-1 背包问题」. 0-1背包 解释 例题中已知条件有第 \(𝑖\) 个物品的重量 \(𝑤_𝑖\) ,价值 \(𝑣_𝑖\) ,以及背包的总容量 \(𝑊\) . 设 DP 状态 \(𝑓_{𝑖,𝑗} \) 为在只能放前 \(𝑖\) 个物品的情况下,容量为 \(𝑗\) 的背包所能达到的最大总价值. 考虑转移.假设当前已经处理好了前 \(𝑖 −1 \) 个物品的所有状态,那么对于第 \(𝑖\) 个物品,当其不放入背包时,背包的剩余容量不变,背包中物品的总价值也不变,故这种情况的最大价值为 \(𝑓_{𝑖−1,𝑗}\) ;当其放入背包时,背包的剩余容量会减小 \(𝑤_𝑖\) ,背包中物品的总价值会增大 \(𝑣_𝑖\)...

简介 生成树(spanning tree) 在图论中,无向图 \(G=(V,E)\) 的生成树(spanning tree)是具有 \(G\) 的全部顶点,但边数最少的联通子图。假设 \(G\) 中一共有 \(n\) 个顶点,一颗生成树满足下列条件 \(n\) 个顶点; \(n-1\) 条边; \(n\) 个顶点联通; 一个图的生成树可能有多个。 最小生成树(minimum spanning tree, MST)/最小生成森林 :联通加权无向图中边缘权重加和最小的生成树。给定无向图 \(G=(V,E)\) , \((u,v)\) 代表顶点 \(u\) 与顶点 \(v\) 的边, \(w(u,v)\) 代表此边的权重,若存在生成树T使得: \[w(T) = \sum_{(u,v)\in T}w(w,v)\] 最小,则 \(T\) 为 \(G\) 的最小生成树。对于非连通无向图来说,它的每一 连通分量 同样有最小生成树,它们的并被称为 最小生成森林 。最小生成树除了继承生成树的性质之外,还存在下面两个特点: 当图的每一条边的权值都相同时,该图的所有生成树都是最小生成树;...

Hough Voting 本文的标题是Deep Hough Voting,先来说一下Hough Voting。 用Hough变换检测直线大家想必都听过:对于一条直线,可以使用 \((r,θ)\) 两个参数进行描述,那么对于图像中的一点,过这个点的直线有很多条,可以生成一系列的 \((r,θ)\) ,在参数平面内就是一条曲线,也就是说,一个点对应着参数平面内的一个曲线。那如果有很多个点,则会在参数平面内生成很多曲线。那么,如果这些点是能构成一条直线的,那么这条直线的参数 \((r,θ)\) 就在每条曲线中都存在,所以看起来就像是多条曲线相交在 \((r,θ)\) 。可以用多条曲线投票的方式来看,其他点都是很少的票数,而 \((r,θ)\) 则票数很多,所以直线的参数就是 \((r,θ)\) 。 所以Hough变换的思想就是在于,在参数空间内进行投票,投票得数高的就是要得到的值。 文中提到的Hough Voting如下: A traditional Hough voting 2D detector comprises an offline and an online step....
3D Model
2026-02-12

三维深度学习简介 多视角(multi-view):通过多视角二维图片组合为三维物体,此方法将传统CNN应用于多张二维视角的图片,特征被view pooling procedure聚合起来形成三维物体; 体素(volumetric):通过将物体表现为空间中的体素进行类似于二维的三维卷积(例如,卷积核大小为5x5x5),是规律化的并且易于类比二维的,但同时因为多了一个维度出来,时间和空间复杂度都非常高,目前已经不是主流的方法了; 点云(point clouds):直接将三维点云抛入网络进行训练,数据量小。主要任务有分类、分割以及大场景下语义分割; 非欧式(manifold,graph):在流形或图的结构上进行卷积,三维点云可以表现为mesh结构,可以通过点对之间临接关系表现为图的结构。 点云的特性 无序性...

概括 这篇文章将卷积比较自然地拓展到点云的情形,思路很赞! 文章的主要创新点:“weight function”和“density function”,并能实现translation-invariance和permutation-invariance,可以实现层级化特征提取,而且能自然推广到其deconvolution的情形实现分割,在二维CIFAR-10图像分类任务中精度堪比CNN(表明能够充分近似卷积网络),达到了SOTA的性能。 缺点:每个kernel都需要由“kernel function”生成,而“kernel function”实质上是一个CNN网络,计算量比较大。 思想 察觉到:二维卷积中pixel的相对centroid位置与kernel vector的生成方式有关。 以二维卷积为例说明一下如何将卷积拓展到点云。这里只考虑使用一个kernel在一个location的一次卷积操作。 对于二维图像,我们可以将图像的pixels看作是一个点,那么图像就是整齐排列的点阵。每个point都有维度为 \(C_{in}\)...

160. 相交链表 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交 : 题目数据 保证 整个链式结构中不存在环。 注意 ,函数返回结果后,链表必须 保持其原始结构 。 自定义评测: 评测系统 的输入如下(你设计的程序 不适用 此输入): intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0 listA - 第一个链表 listB - 第二个链表 skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数 skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数 评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。 示例 1: 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2,...
Large Model
2026-01-20
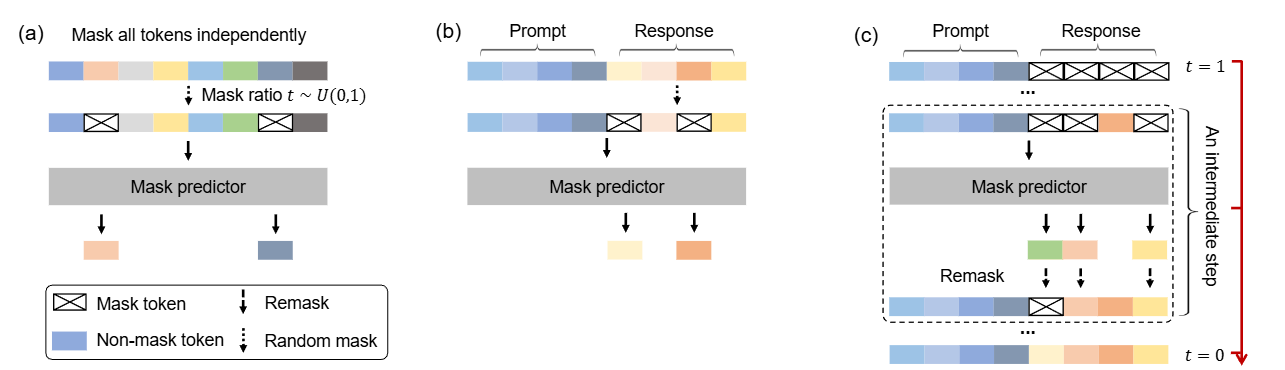
这是一篇尝试改变LLM「范式」的文章:当前主流的LLM架构都是「自回归」的,通俗地理解就是必须「从左到右依次生成」。这篇文章挑战了这一范式,探索扩散模型在 LLMs 上的可行性,通过 随机掩码 - 预测 的逆向思维,让模型学会「全局思考」。 论文: [2502.09992] Large Language Diffusion Models 背景 主流大语言模型架构:自回归模型 (Autoregressive LLMs) 过去几年, 自回归模型(Autoregressive Models, ARMs)一直是大语言模型(LLM)的主流架构。典型的自回归语言模型以Transformer解码器为基础,按照从左到右 的顺序依次预测下一个词元(token)。 形式化地,自回归模型将一个长度为 \(N\) 的文本序列 \(X=(x_1, x_2, ..., x_N)\) 的概率分解为各位置的条件概率连乘积: \[P_{\theta}(x_1, x_2, \dots, x_N) = \prod_{i=1}^{N} P_{\theta}(x_i \mid x_1, x_2, \dots,...
Large Model
2026-01-20

引言 Diffusion模型近年来在图像生成这一连续域任务中取得了显著成果,展现出强大的生成能力。然而,在文本生成这一离散域任务中整体效果仍不尽如人意,未能在该领域引起广泛关注。 去年,一篇研究离散扩散模型在文本生成的文章《Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution》获得ICML 2024的Best Paper,引发了学术界的广泛兴趣,也激发了新一轮的研究热潮。随后在2025年,越来越多高校和企业也开始积极探索基于Diffusion的文本生成方法。其中,近期备受关注的Block Diffusion也成功入选ICLR oral,进一步推动了该方向的发展。...
Large Model
2026-01-15

简介 后训练(post-training)已成为完整训练流程中的重要组成部分。相比于预训练,后训练需要的计算资源相对较少,但能够: 提高推理任务的准确性 使模型与社会价值观保持一致 适应用户偏好 OpenAI 的 o1 系列模型首次引入了通过增加思维链(Chain-of-Thought)推理过程长度来实现推理时间,扩展这种方法在数学、编程和科学推理等各种推理任务上取得了显著改进 研究界已探索多种方法来提高模型的推理能力:比如 基于过程的奖励模型 (Process-based Reward Models) 强化学习 (Reinforcement Learning), 代表工作:InstructGPT, 以及 搜索算法( 蒙特卡洛树搜索(Monte Carlo Tree Search)、束搜索(Beam Search))。然而,这些方法尚未达到与 OpenAI o1 系列模型相当的通用推理性能。 DeepSeek-R1-Zero 本文首先探索使用纯强化学习(RL)来提高语言模型的推理能力,重点关注: 探索 LLM 在没有任何监督数据的情况下,通过纯 RL 过程的自我进化来发展推理能力...
Large Model
2026-01-15

简介 24年12月,研究团队开发了 DeepSeek-V3,这是一个基于 MoE 架构的大模型,总参数量达到 671B,其中每个 token 会激活 37B 个参数。 基于提升性能和降低成本的双重目标,在架构设计方面,DeepSeek-V3 采用了 MLA 来确保推理效率,并使用 DeepSeekMoE 来实现经济高效的训练。这两种架构在 DeepSeek-V2 中已经得到验证,证实了它们能够在保持模型性能的同时实现高效的训练和推理。 除了延续这些基础架构外,研究团队还引入了两项创新策略来进一步提升模型性能。 首先,DeepSeek-V3 首创了 无辅助损失的负载均衡 策略(auxiliary-loss-free strategy for load balancing),有效降低了负载均衡对模型性能的负面影响。另外,DeepSeek-V3 采用了 多 token 预测训练目标, 这种方法在评估基准测试中展现出了显著的性能提升。 为了提高训练效率,该研究采用了 FP8 混合精度训练技术...
Reinforcement Learning
2026-01-11
引言 大语言模型(LLMs)在近年来取得了显著进展,展现出上下文学习、指令跟随和逐步推理等突出特性。然而,由于这些模型是在包含高质量和低质量数据的预训练语料库上训练的,它们可能会表现出编造事实、生成有偏见或有毒文本等意外行为。因此,将LLMs与人类价值观对齐变得至关重要,特别是在帮助性、诚实性和无害性(3H)方面。 基于人类反馈的强化学习(RLHF)已被验证为有效的对齐方法,但训练过程复杂且不稳定。本文深入分析了RLHF框架,特别是PPO算法的内部工作原理,并提出了PPOmax算法,以提高策略模型训练的稳定性和效果。 RLHF的基本框架 RLHF训练过程包括三个主要阶段: 1. 监督微调(SFT):模型通过模仿人类标注的对话示例来学习一般的人类对话方式, 优化模型的指令跟随能力 1. 奖励模...