Search&Rec
2026-01-11
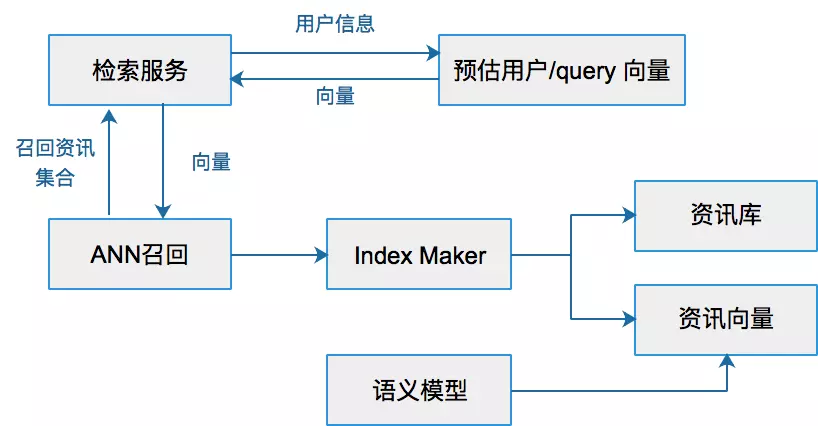
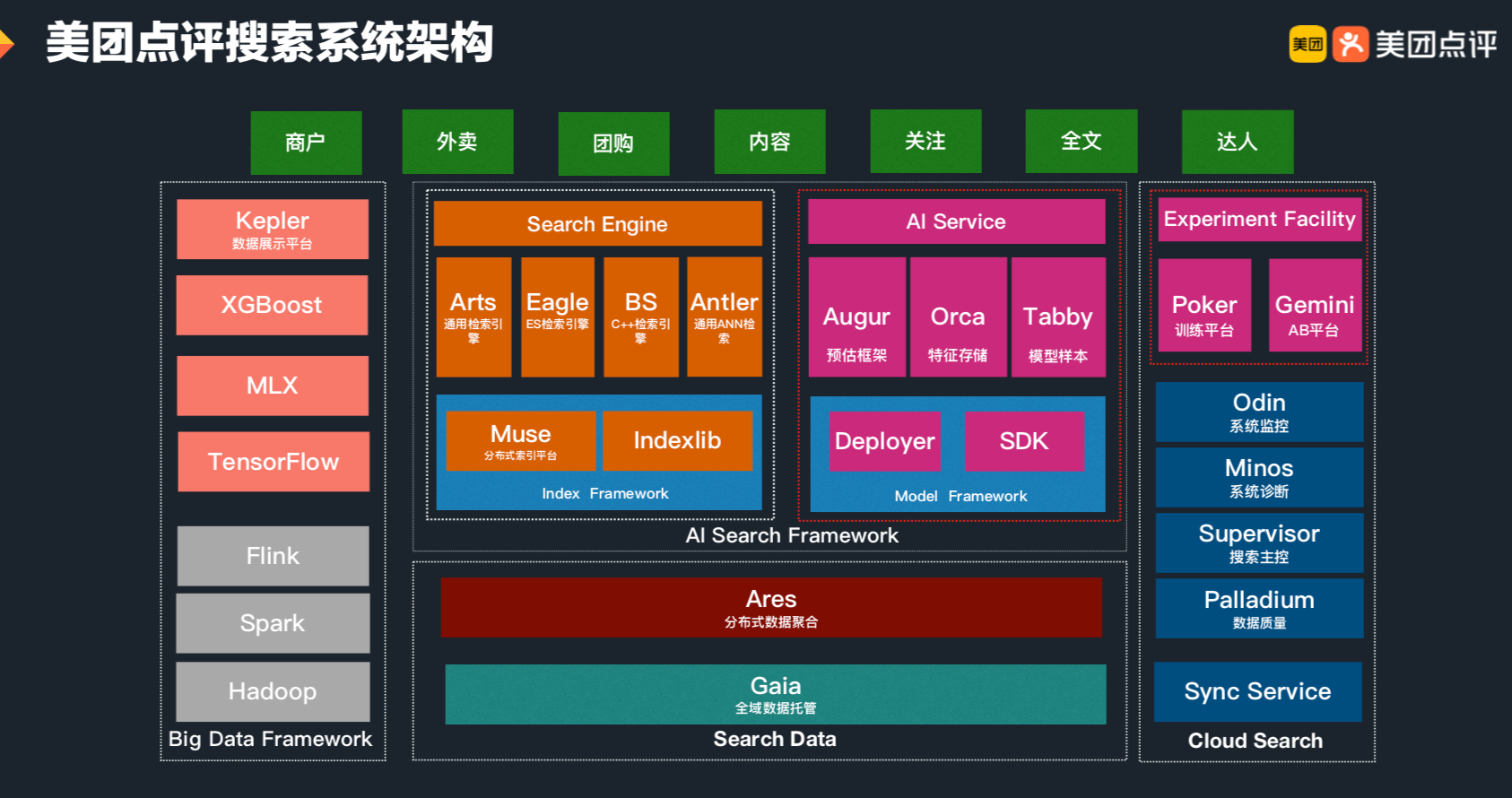
1. 概述 新闻推荐系统从海量新闻中推荐出你感兴趣的新闻,百度从海量的搜索结果中找到最优的结果,短视频推荐出你每天都停不下来的视频流,这些里面都包含ANN方法。当然,在现在的检索系统中,往往是多分支并行触发的效果,虽然DNN 大行其道,但是 ANN 一直不可或缺。 通用理解上,ANN(Approximate Nearest Neighbor)是在向量空间中搜索向量最近邻的优化问题。目前业界常用nmslib、Annoy算法作为实现。在实际的工程应用中,ANN是作为一种向量检索技术应用,用于解决长尾Query召回问题。将一个资讯的ANN 召回系统抽象出来大概是下面的样子。 Ann(approximate nearest neighbor)是指一系列用于解决最近邻查找问题的近似算法。最近邻查找问题...