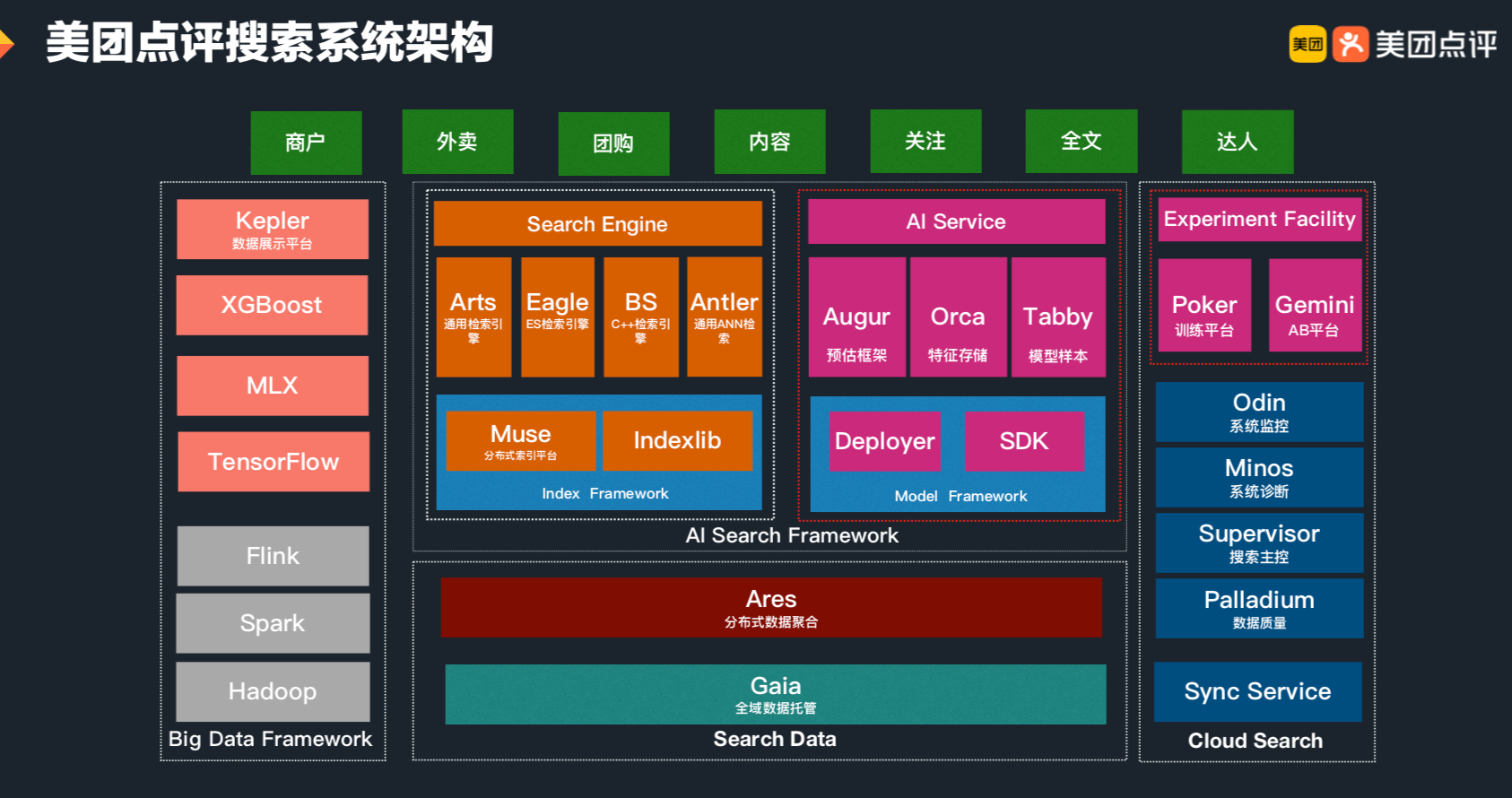
Computer Vision
2026-01-11
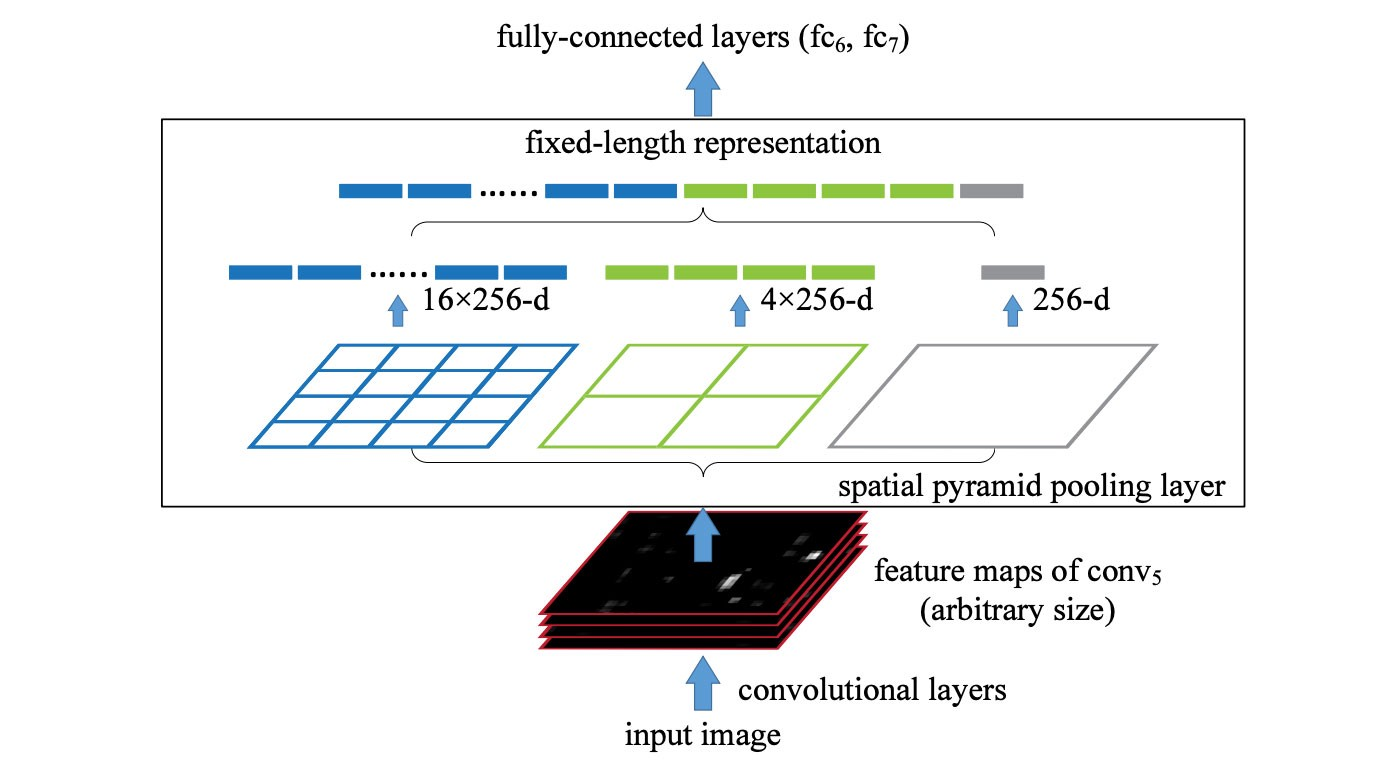
SPP (spatial pyramid pooling layer) SPP applies a slightly different strategy in detecting objects of different scales. It replaces the last pooling layer (after the last convolutional layer) with a spatial pyramid pooling layer. The feature maps are spatially divided into m×m bins with m, say, equals 1, 2, and 4 respectively. Then a maximum pool i...