Preformer Performer的出发点还是标准的Attention,所以在它那里还是有 [Math] ,然后它希望将复杂度线性化,那就是需要找到新的 [Math] ,使得: [公式] 如果找到合理的从 [Math] 到 [Math] 的映射方案,便是该思路的最大难度了。 激活函数 线性Attention的常见形式如 式3,其中 [Math] 、 [Math] 是值域非负的激活函数。那么如何选取这个激活函数呢?Performer告诉我们,应该选择指数函数 [公式] 首先,我们来看它跟已有的结果有什么不一样。在 Transformers are RNNs 给出的选择是: [公式] 我们知道 1+x 正是 e^x 在 x=0 处的一阶泰勒展开,因此 [Math] 这个选择其实已经相当接近 ...
NLP
2026-01-11

简介 承接 Transformers are RNNs 这篇论文 目的: 为了分析之前linear transformer的效果为什么不好。发现主要是两个原因造成的: 1. 无界梯度(unbounded gradient),会导致模型在训练时不稳定,收敛不好; 1. 注意力稀释(attention dilution),transformer在lower level时应该更关注局部特征,而higher level更关注全局特征,但线性transformer中的attention往往weight 更均匀化,不能聚焦在local区域上,因此称为attention稀释。 解决方案: 1. 对linear attention算出来的output接着做个normalization,形成NormForme...
Computer Vision
2026-01-11

上图是Yolo v4中,对各种detector部件的总结:包含Input、backbone、neck、head、... Backbone Neck 例如:SPP 、 ASPP 、 RFB、 SAM 用来增加感受野 特征融合,主要是指不同输出层直接的特征融合,主要包括FPN、PAN、SFAM、ASFF和BiFPN。 结构 One stage TwoStage Anchor Free Transformer Problems
Computer Vision
2026-01-11
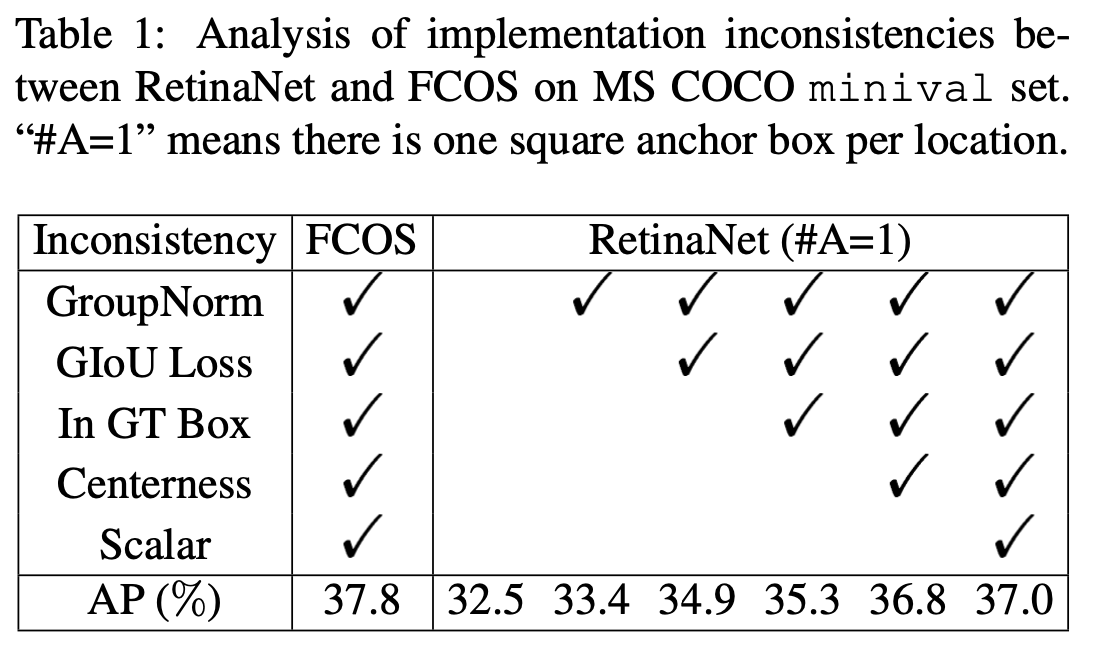
Introduction 由于FPN和Focal loss 的加入,anchorfree模型变得越来越多。在仔细比对了anchorbased和anchorfree目标检测方法后,结合实验结果,论文认为两者的性能差异主要来源于正负样本的定义,假如训练过程中使用相同的正负样本,两者的最终性能将会相差无几。 作者将目前的Anchorfree分为两个大类: 1. keypointbased methods:以CornerNet和ExtremeNet为代表,首先定位几个预定义或自学习的关键点,然后限制物体的空间范围; 1. centerbased methods:以FCOS和Foveabox为代表,使用物体的中心点或区域定义基准点,然后预测从该点到物体边界的四个距离。 为此,论文提出ATSS( Ada...
Computer Vision
2026-01-11
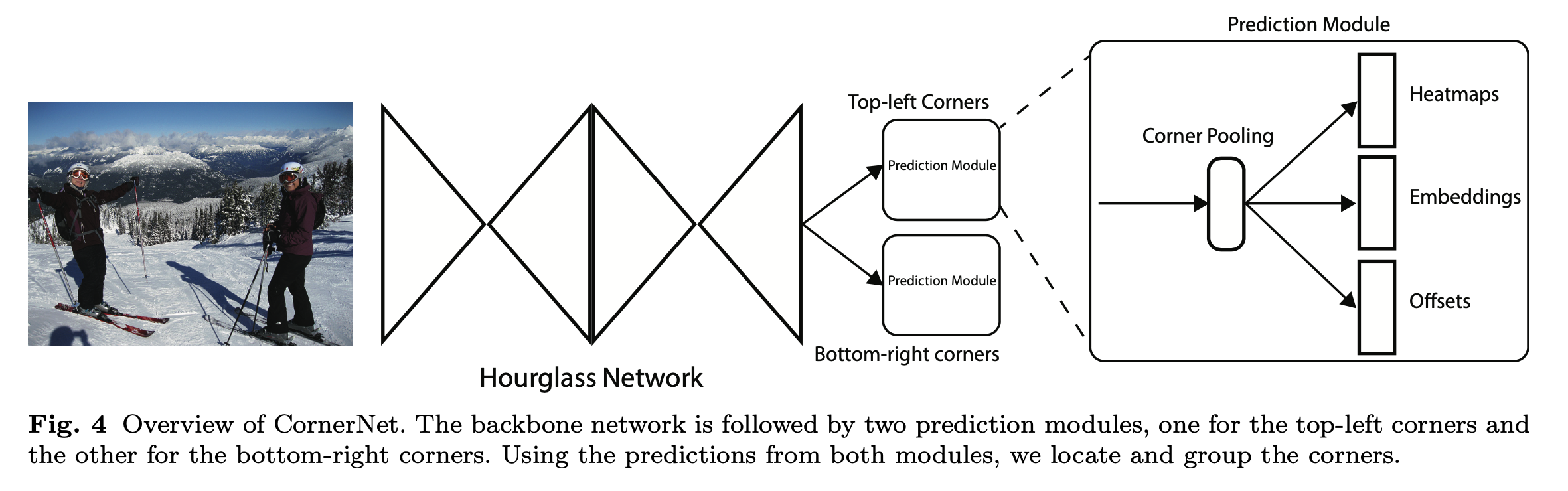
简介 CornerNet是密歇根大学Hei Law等人在发表ECCV2018的一篇论文,作者总结目前anchorbased方法存在两个缺点: 1. 提取的anchor boxes数量较多,比如DSSD使用40k, RetinaNet使用100k,anchor boxes众多造成anchor boxes正负样本的不均衡; 1. anchor boxes需要调整很多超参数,比如anchor boxes数量、尺寸、比率,影响模型的训练和推断速率。 作者的思路其实来源于一篇多人姿态估计的论文"Endtoend learning for joint detection and grouping"。基于CNN的2D多人姿态估计方法,通常有2个思路(BottomUp Approaches和TopDown ...
Computer Vision
2026-01-11

Motivation 我们知道object detection的算法主要可以分为两大类:twostage detector和onestage detector。前者是指类似Faster RCNN,RFCN这样需要region proposal的检测算法,这类算法可以达到很高的准确率,但是速度较慢。虽然可以通过减少proposal的数量或降低输入图像的分辨率等方式达到提速,但是速度并没有质的提升。后者是指类似YOLO,SSD这样不需要region proposal,直接回归的检测算法,这类算法速度很快,但是准确率不如前者。作者提出focal loss的出发点也是希望onestage detector可以达到twostage detector的准确率,同时不影响原有的速度。 既然有了出发点,那么...
Computer Vision
2026-01-11
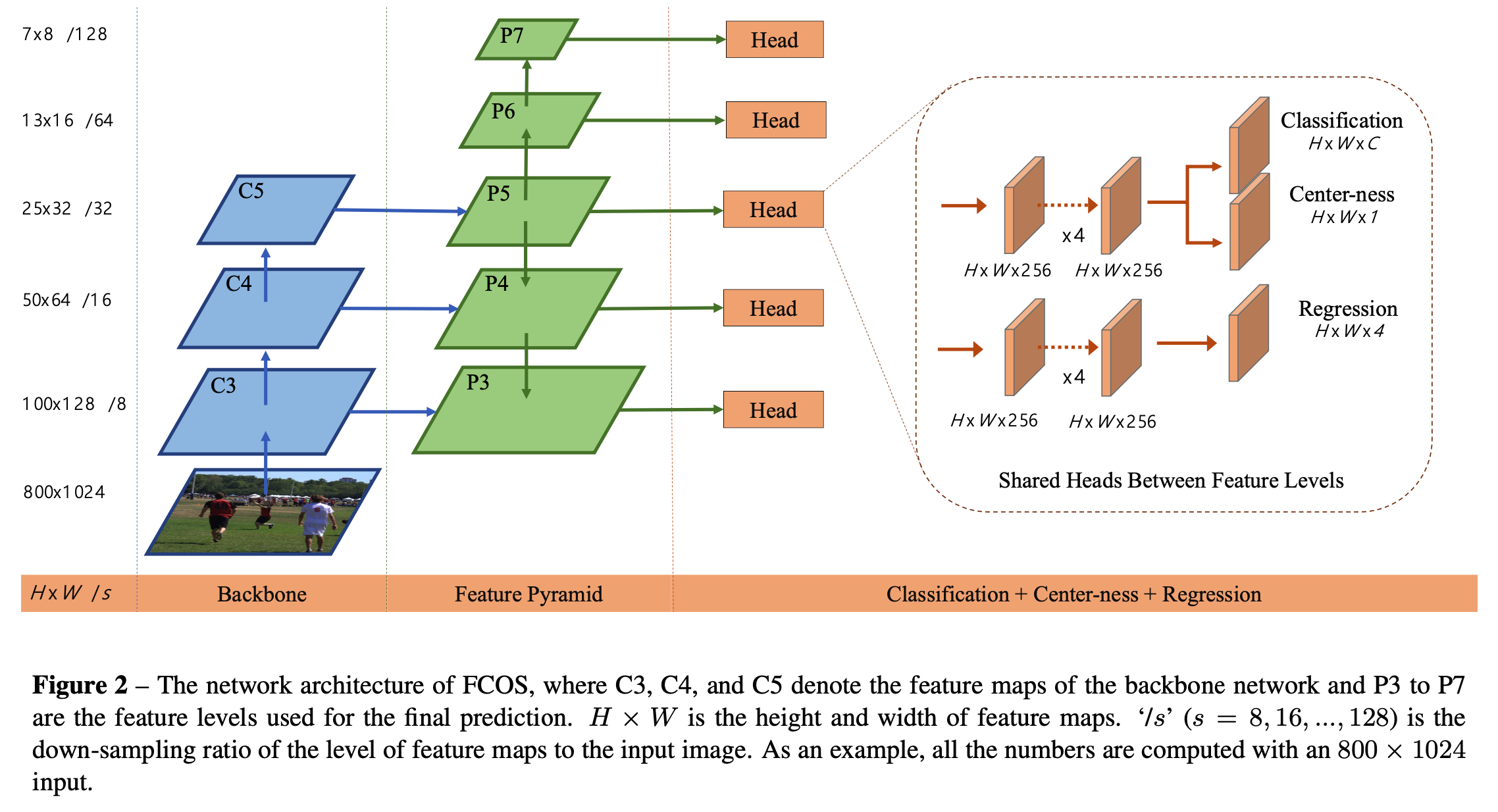
先要明确的知道,FCOS是一个基于FCN(全卷积网络用于目标检测)、一阶段(one stage)、anchor free、proposal free、参考语义分割思想 实现的逐像素目标检测的模型。 简要介绍下FCOS几个核心点: (1)FCOS方法借鉴了FCN的思想,对 feature map 上每个特征点做回归操作,预测四个值 , 分别代表特征点到Ground Truth Bounding box上、下、左、右边界的距离。 (2)特征点映射会原图后对应多个GT Bounding box,无法准确判断原图像素所属类别,因此模型引入 FPN 结构,利用不同的层来处理不同尺寸的目标框。 (3)远离目标中心点可能会产生劣质预测结果,为了增强中心点选取的准确性,模型引入了Centerness lay...
Computer Vision
2026-01-11
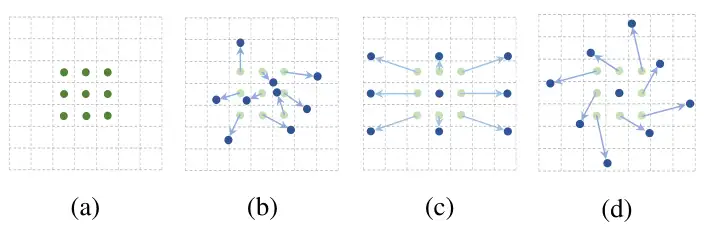
Deformable Convolution 在正式介绍这个工作之前很有必要先了解什么是 Deformable Convolution 。 Deformable Convolution 是MSRA的代季峰老师以及实习生在2017年提出的一种全新的卷积结构。这种方法将固定形状的卷积过程改造成了能适应物体形状的可变的卷积过程,从而使结构适应物体形变的能力更强。 传统的CNN只能靠一些简单的方法(比如max pooling)来适应物体的形变,如果形变的太厉害就无能为力了。因为CNN的卷积核的geometric structure是fixed的,也就是固定住的。卷积核总是在固定位置对输入特征特征进行采样。 为了改变这种情况专家们想了很多方法,最常见的有两种: 1. 使用大量的数据进行训练。比如用Im...