最优策略(Optimal Policy ) 之前在 贝尔曼方程中说过,状态值可以用来评估一个策略是好是坏,这里给出正式的概念: [公式] 那么此时 [Math] 比 [Math] ”更好“ 最优状态值(Optimal State Value): 最优策略(Optimal Policy): 性质: 为了说明上述性质, 我们研究贝尔曼最优方程 Bellman optimality equation(BOE) 贝尔曼最优方程(BOE) 定义 分析最优策略和最优状态值的工具是贝尔曼最优方程(BOE)。通过求解此方程,我们可以获得最优策略和最优状态值。 对于每个 s∈S ,BOE 的elementwise表达式为: [公式] 其中, v(s) 和 [Math] 是待求解的未知变量, π(s) 表示状态...
Reinforcement Learning
2026-01-11

概述与理论背景 ActorCritic方法是强化学习中的一类重要算法,它巧妙地结合了基于策略(policybased)和基于价值(valuebased)的方法。在这种结构中,"Actor"指策略更新步骤,负责根据策略执行动作;而"Critic"指价值更新步骤,负责评估Actor的表现。从另一个角度看,ActorCritic方法本质上仍是策略梯度算法,可以通过扩展策略梯度算法获得。 ActorCritic方法在强化学习中的位置非常重要,它既保留了策略梯度方法直接优化策略的优势,又利用了值函数方法的效率。这种结合使得ActorCritic方法成为解决复杂强化学习问题的强大工具。 最简单的ActorCritic算法(QAC) QAC算法通过扩展策略梯度方法得到。策略梯度方法的核心思想是通过最大化标...
Reinforcement Learning
2026-01-11
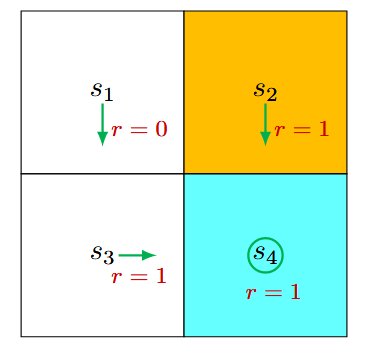
状态价值(State values) 定义 状态价值是强化学习中的核心概念,用于衡量Agent从某个状态出发、遵循特定策略后所能获得的期望回报。 数学表达为: [公式] 其中: [Math] :状态 s 的状态价值函数(statevalue function) 或者简称为 状态价值(state value); [Math] :智能体遵循的策略; [Math] :从当前时间步 t 开始的折扣回报; [Math] :折扣因子,用于平衡即时奖励和未来奖励。 状态价值的特点 依赖于状态 s :状态价值是条件期望,条件是智能体从状态 s 开始。 依赖于策略 [Math] :不同策略会生成不同的轨迹,从而影响状态价值。 与时间步无关:状态价值是一个固定值,与当前时间步 t 无关。 代表一个状态的价值。如...
Computer Vision
2026-01-11

💡 轻量级网络系列 Introduction Inception 在最初的版本 Inception/GoogleNet,其核心思想是利用多尺寸卷积核去观察输入数据。举个栗子,我们看某个景象由于远近不同,同一个物体的大小也会有所不同,那么不同尺度的卷积核观察的特征就会有这样的效果。于是就有了如下的网络结构图: 于是我们的网络就变胖了,通过增加网络的宽度,提高了对于不同尺度的适应程度。但这样的话,计算量有点大了。 Pointwise Conv 为了减少在上面结构的参数量并降低计算量,于是在 Inception V1 的基础版本上加上了 1x1 卷积核,这就形成了 Inception V1 的最终网络结构,如下图。 这个 1x1 卷积就是 Pointwise Convolution,简称 PW。利...
Algorithm
2026-01-11
题目 给定一个无序的数组,找出数组在排序之后,相邻元素之间最大的差值。 如果数组元素个数小于 2,则返回 0。 Example 1: [代码] 解题思路:如果进行排序,这里会超时。采用桶排序 排序算法 的思想,可以在线性时间解决。 1. 首先建立桶,每个桶中只需要存放这个桶中元素的最大值和最小值。 1. 我们期望将数组中的各个数等距离分配,也就是每个桶的长度相同,也就是对于所有桶来说,桶内最大值减去桶内最小值都是一样的。可以当成公式来记。 1. 确定桶的数量,最后的加一保证了数组的最大值也能分到一个桶。为什么需要这样规定桶的尺寸呢?因为这样可以让最大的间距的两个元素在两个不同的桶中。可以证明一下,因为我们用元素范围之差除以元素个数,所以桶的尺寸就是平均的元素间距,显然最大间距的两个元素不可能...
Algorithm
2026-01-11

1. 可以重复选取 给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。 candidates 中的数字可以无限制重复被选取。 画出树状搜索图如下, 为了去除重复的情况, 我们需要按照某种顺序搜索,具体做法是:每一次搜索的时候,设置下一轮搜索的起点 [代码] 2. 不能被重复选取 与上面的区别在于 1. index每次不要重复搜索,而是去寻找下一个 1. 排除重复的元素 [代码]
Large Model
2026-01-11

概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 D = \{(x_i, y^_i)\}_{i=1}^n ,其中包含问题 x_i 和对应的真实答案 y^_i ,目标是训练一个策略模型 [Math] 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 z = (z_1, z_2, ..., z_m) 来连接问题 x 和答案 y ,每个 z_i 是解决问题的重要中间步骤。 当解决问题 x 时,思维 [Math] 被自回归采样,最终答案 [Math] 。 强化学习目标 基于真实答案 y^ ,分配一个值 [Math] , Ki...
Computer Vision
2026-01-11

网络整体介绍 ThunderNet的整体架构如下图所示。 ThunderNet使用320×320像素作为网络的输入分辨率。整体的网络结构分为两部分:Backbone部分和Detection部分。网络的骨干部分为SNet,SNet是基于ShuffleNetV2进行修改得到的。 网络的检测部分,利用了压缩的RPN网络,修改自LightHead RCNN网络用以提高效率。 并提出Context Enhancement Module整合局部和全局特征增强网络特征表达能力。 并提出Spatial Attention Module空间注意模块,引入来自RPN的前后景信息用以优化特征分布。 backbone 部分 1.输入分辨率 为了加快推理(前向操作)速度,作者使用320320大小的输入图像。需要注意的...

💡 引言 Trust Region Policy Optimization (TRPO) 是2015年的ICML会议上提出的一种强大的基于策略的强化学习算法。TRPO 解决了传统策略梯度方法中的一些关键问题,特别是训练不稳定和步长选择困难的问题。与传统策略梯度算法相比,TRPO 具有更高的稳健性和样本效率,能够在复杂环境中取得更好的性能。 优化基础 在深入了解 TRPO 之前,我们需要先简单回顾一些优化方法的基础知识。 梯度上升法 梯度上升法是一种迭代优化算法,用于寻找函数的局部最大值。 目标:找到使目标函数 [Math] 最大化的参数 [Math] : [公式] 梯度上升迭代过程: 1. 在当前参数 [Math] 处计算梯度: [Math] 1. 更新参数: 梯度上升法的主要问题是学习率的...
Reinforcement Learning
2026-01-11

引言 时序差分(TemporalDifference,TD)方法是强化学习中的一类核心算法,它结合了动态规划与蒙特卡洛方法的优点。TD方法是无模型(modelfree)学习方法,不需要环境模型即可学习价值函数和最优策略。 TD方法的核心特点是通过比较不同时间步骤的估计值之间的差异来更新价值函数,这种差异被称为"时序差分误差"(TD error)。TD方法可以被视为解决贝尔曼方程或贝尔曼最优方程的特殊随机逼近算法。 基础TD算法:状态值函数学习 给定策略 [Math] ,基础TD算法用于估计状态值函数 [Math] 。假设我们有一些按照策略 [Math] 生成的经验样本 (s_0, r_1, s_1, ..., s_t, r_{t+1}, s_{t+1}, ...) ,TD算法的更新规则为: ...
Reinforcement Learning
2026-01-11

引言 强化学习中,找到最优策略是核心目标。本文详细介绍三种能够找到最优策略的基础算法:价值迭代、策略迭代和截断策略迭代。这些算法属于动态规划范畴,需要系统模型,是后续无模型强化学习算法的重要基础。 在强化学习的发展路线中,这些算法处于"基础工具"到"算法/方法"的过渡阶段,是从"有模型"到"无模型"学习的重要桥梁。 价值迭代(Value iteration) 价值迭代算法基于收缩映射定理求解贝尔曼最优方程。其核心迭代公式为: [公式] 根据收缩映射定理,当 [Math] 时, v_k 和 [Math] 分别收敛到最优状态值和最优策略。 每次迭代包含两个步骤: 1. 策略更新步骤 (policy update step):找到能解决以下优化问题的策略 1. 价值更新步骤(value updat...
01背包 描述 有N件物品和一个容量为V的背包。 第i件物品的体积是vi,价值是wi。 求解将哪些物品装入背包,可使这些物品的总体积不超过背包流量,且总价值最大。 二维动态规划 f[i][j] 表示只看前i个物品,总体积是j的情况下,总价值最大是多少。 result = max(f[n][0V]) f[i][j]: 不选第i个物品:f[i][j] = f[i1][j]; 选第i个物品:f[i][j] = f[i1][jv[i]] + w[i](v[i]是第i个物品的体积) 两者之间取最大。 初始化:f[0][0] = 0 代码如下: [代码] 一维动态优化 从上面二维的情况来看,f[i] 只与f[i1]相关,因此只用使用一个一维数组[0v]来存储前一个状态。那么如何来实现呢? 第一个问题:状...