Search&Rec
2026-01-11

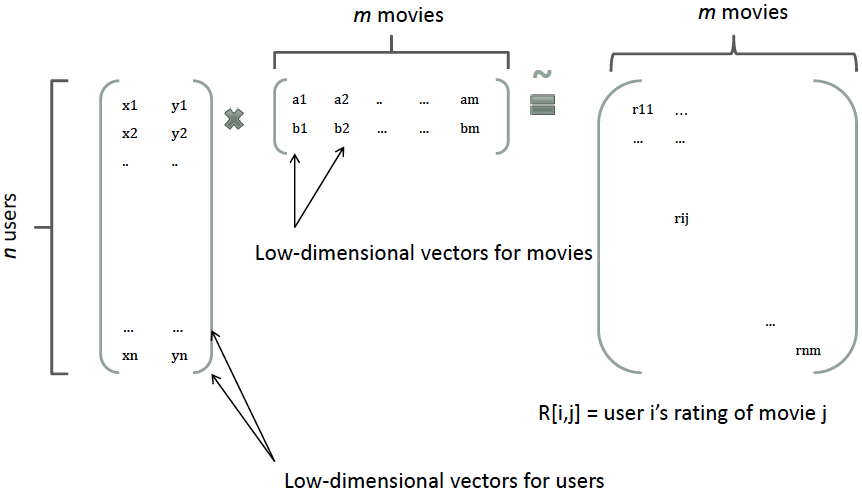
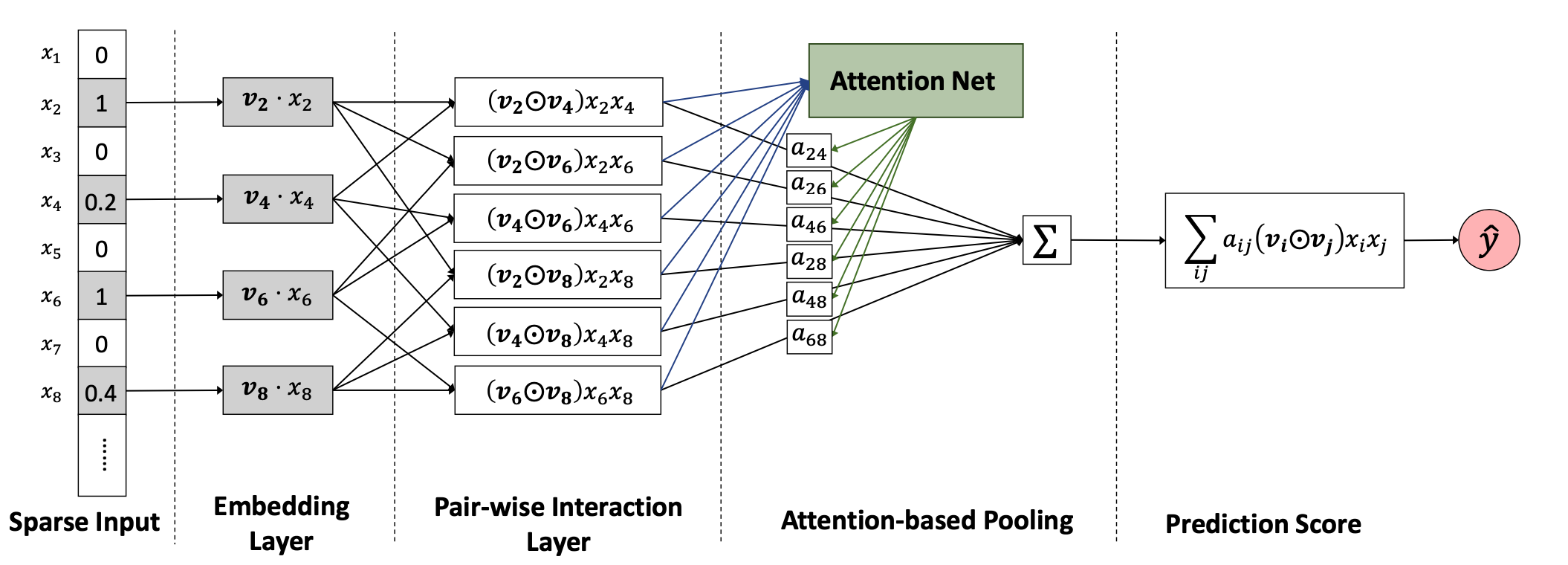
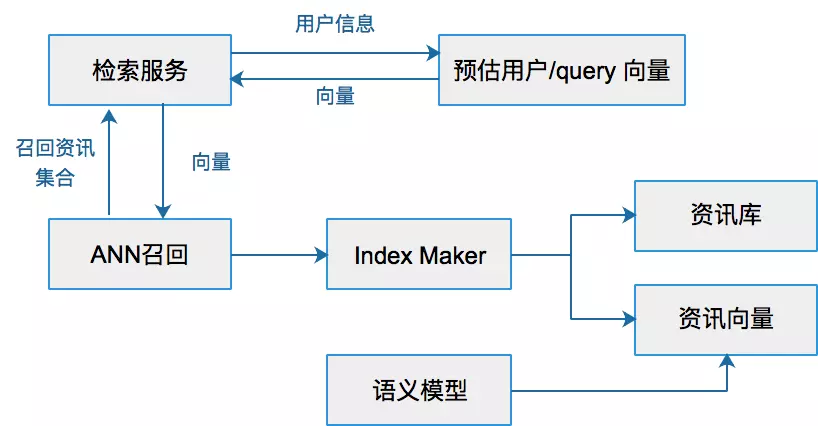
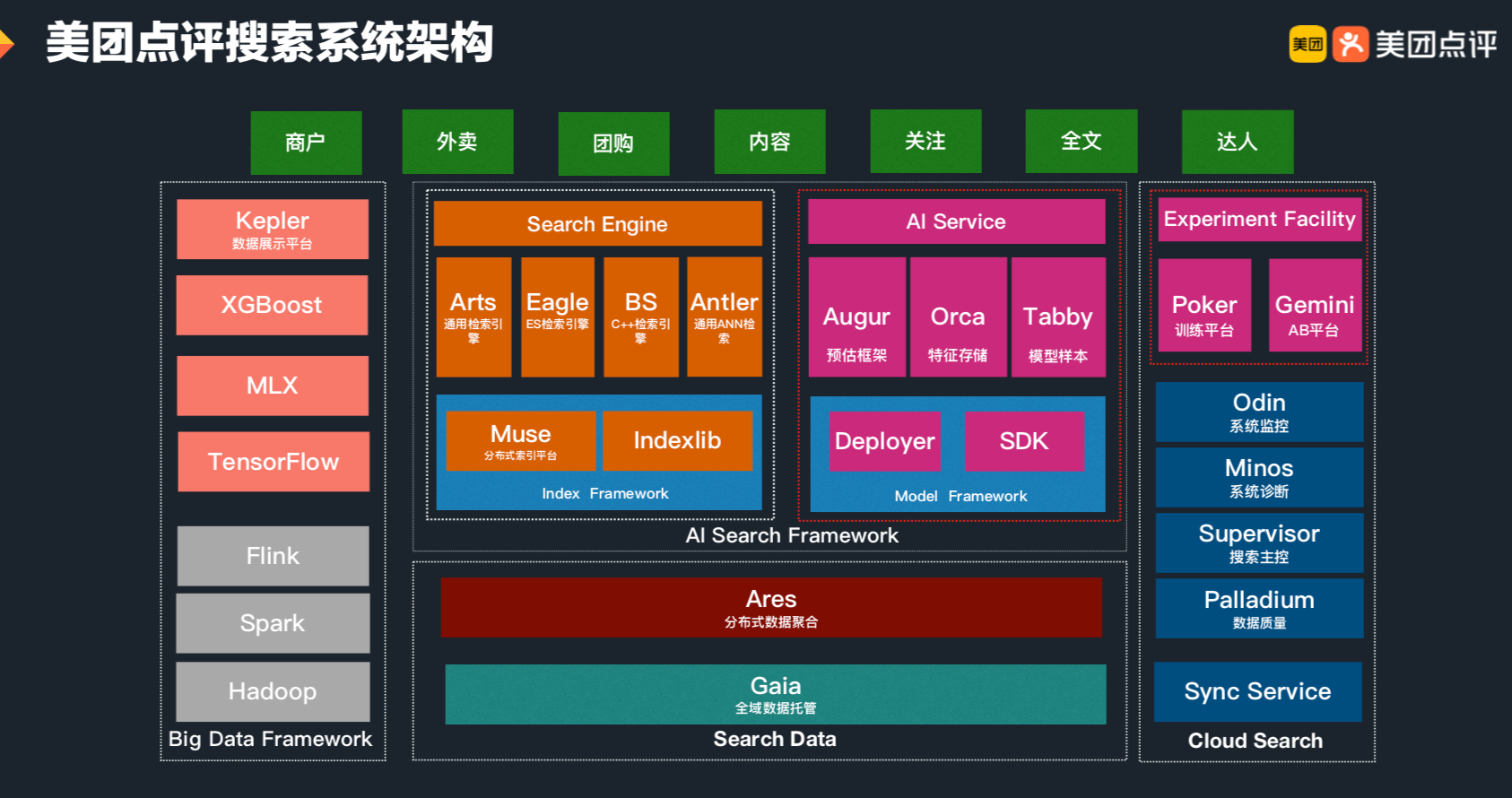
精排是用pointwise方式对商品的CTR/CVR进行预估,旨在建模s=f(user, query, item, context) ,对候选商品进行打分。但有些情况下仅有精排还存在不足之处,如: 1、即使对单个商品进行打分,资源效率限制下,上千候选的精排有时也无法落地更加复杂的模型; 2、pointwise模式的打分无法从候选列表整体或上下文实时反馈角度出发进行排序; 3、直接使用精排分排序无法满足特殊整体性排序需求,如常见的搜索结果的多样性(如价格、地域、品牌、风格等属性的打散)、发现性、异质内容的混排调控(如商品、内容、广告等物料的混排)、流量调控等。 相应地,从以上三点出发,本文从“更加精准打分”、“关注序和上下文”、“特殊需求重排”三方面梳理重排的一般方法: 更加精准打分 重排的第...