
Hough Voting 本文的标题是Deep Hough Voting,先来说一下Hough Voting。 用Hough变换检测直线大家想必都听过:对于一条直线,可以使用 \((r,θ)\) 两个参数进行描述,那么对于图像中的一点,过这个点的直线有很多条,可以生成一系列的 \((r,θ)\) ,在参数平面内就是一条曲线,也就是说,一个点对应着参数平面内的一个曲线。那如果有很多个点,则会在参数平面内生成很多曲线。那么,如果这些点是能构成一条直线的,那么这条直线的参数 \((r,θ)\) 就在每条曲线中都存在,所以看起来就像是多条曲线相交在 \((r,θ)\) 。可以用多条曲线投票的方式来看,其他点都是很少的票数,而 \((r,θ)\) 则票数很多,所以直线的参数就是 \((r,θ)\) 。 所以Hough变换的思想就是在于,在参数空间内进行投票,投票得数高的就是要得到的值。 文中提到的Hough Voting如下: A traditional Hough voting 2D detector comprises an offline and an online step....
3D Model
2026-02-12

三维深度学习简介 多视角(multi-view):通过多视角二维图片组合为三维物体,此方法将传统CNN应用于多张二维视角的图片,特征被view pooling procedure聚合起来形成三维物体; 体素(volumetric):通过将物体表现为空间中的体素进行类似于二维的三维卷积(例如,卷积核大小为5x5x5),是规律化的并且易于类比二维的,但同时因为多了一个维度出来,时间和空间复杂度都非常高,目前已经不是主流的方法了; 点云(point clouds):直接将三维点云抛入网络进行训练,数据量小。主要任务有分类、分割以及大场景下语义分割; 非欧式(manifold,graph):在流形或图的结构上进行卷积,三维点云可以表现为mesh结构,可以通过点对之间临接关系表现为图的结构。 点云的特性 无序性...

概括 这篇文章将卷积比较自然地拓展到点云的情形,思路很赞! 文章的主要创新点:“weight function”和“density function”,并能实现translation-invariance和permutation-invariance,可以实现层级化特征提取,而且能自然推广到其deconvolution的情形实现分割,在二维CIFAR-10图像分类任务中精度堪比CNN(表明能够充分近似卷积网络),达到了SOTA的性能。 缺点:每个kernel都需要由“kernel function”生成,而“kernel function”实质上是一个CNN网络,计算量比较大。 思想 察觉到:二维卷积中pixel的相对centroid位置与kernel vector的生成方式有关。 以二维卷积为例说明一下如何将卷积拓展到点云。这里只考虑使用一个kernel在一个location的一次卷积操作。 对于二维图像,我们可以将图像的pixels看作是一个点,那么图像就是整齐排列的点阵。每个point都有维度为 \(C_{in}\)...
3D Model
2026-01-30

三维空间中的旋转有很多种表示方式,欧拉角,旋转矩阵,旋转向量,四元数。由于在slam与机器人中会大量用到这方面的知识,所以在这里将此方面的知识总结一下,方便以后查阅。 欧拉角(Euler Angle) 欧拉角可以使用滑翔翼飞行器控制来理解,比如对于下面这张图,一般假设红色轴为z轴,则z轴表示空间的第三维,则去掉这一维度表示飞行器在一个二维平面上;蓝色轴为x轴,也是飞行器的朝向,因此绕此轴转动就像是飞行器在做翻滚动作,因此叫翻滚角(roll);绿色轴为y轴,绕这个轴转动其实就是飞机开始准备向上飞或者向下飞了,因此叫俯仰角(pitch);同理,绕红色轴也就是z轴转动代表飞机开始调整自身在二维平面上的朝向了,因此叫偏航角(yaw)。 在欧拉角的表示中,yaw、pitch、roll的顺序对旋转结果是有影响的。即 给定一组欧拉角角度值,比如yaw=45度,pitch=30度,roll=60度,按照yaw-pitch-roll的顺序旋转和按照yaw-roll-pitch的顺序旋转,最终刚体的朝向是不同的! 换言之,若刚体需要按照两种不同的旋转顺序旋转到相同的朝向,所需要的欧拉角角度值则是不同的!...
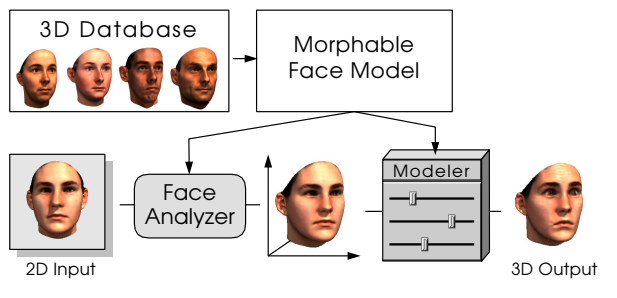
3D Morphable models(简称3DMM),其相关的传统方法和深度学习方法都有较多的研究。 基本思想 3DMM,即三维可变形人脸模型,是一个通用的三维人脸模型,用固定的点数来表示人脸。 它的核心思想就是人脸可以在三维空间中进行一一匹配,并且可以由其他许多幅人脸正交基加权线性相加而来。 我们所处的三维空间,每一点 \((x,y,z)\) ,实际上都是由三维空间三个方向的基量, \((1,0,0)\) , \((0,1,0)\) , \((0,0,1)\) 加权相加所得,只是权重分别为 \(x,y,z\) 。 转换到三维空间,道理也一样。每一个三维的人脸,可以由一个数据库中的所有人脸组成的基向量空间中进行表示,而求解任意三维人脸的模型,实际上等价于求解各个基向量的系数的问题。 人脸的基本属性包括 形状和纹理 ,每一张人脸可以表示为形状向量和纹理向量的线性叠加。 形状向量Shape Vector: \(S=(X1,Y1,Z1,X2,Y2,Z2,...,Yn,Zn)\) ,示意图如下: 纹理向量Texture Vector:...
3D Model
2026-01-30

本文主要介绍球谐(Spherical Harmonic,简称SH)函数在光照中的一些计算实现,其内容来自于GDC2003的演讲: Spherical Harmonic Lighting: The Gritty Details 学习总结 球谐函数是一组正交基函数,两两相乘的积分结果是0,而自身相乘的积分结果为1,任意信号都可以通过与球谐函数相乘积分算出其在对应球谐函数上的系数,这个过程可以看成是信号在球谐函数上的投影, 通过多个球谐函数按照对应系数累加可以得到原始信号的模拟,参与模拟的球谐函数阶数越高,模拟精度也就越高。 球面坐标系( \(\theta, \phi\) )下面的球谐函数可以表示任意点到球心的距离,而这个距离也可以解读成强度,从而可以用于实现某点处各个方向上的输入光强。 同时,每个点处的输入光强与输出光强的转换关系(BRDF之类)也可以使用球谐函数来表示,实际光照就是上述两个球谐函数相乘的积分输出 ,而在实际计算中,如果在离线的时候完成两个球谐函数的系数的求取,在运行时只需要一个系数向量点乘即可完成,大大简化了计算量,提升了计算速度。 背景简介 球谐光照(SH...
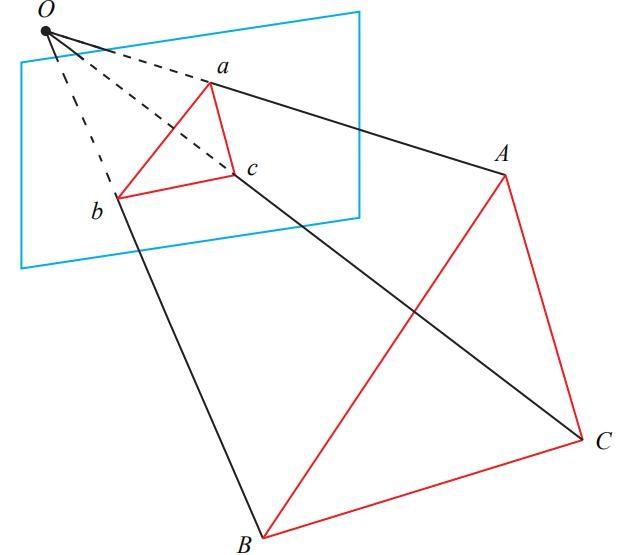
简介 PnP(Perspective-n-Point)是求解3D到2D点对运动的方法,目的是求解相机坐标系相对世界坐标系的位姿。 它描述了已知 \(n\) 个3D点的坐标(相对世界坐标系)以及这些点的像素坐标时,如何估计相机的位姿(即求解世界坐标系到相机坐标系的旋转矩阵 \(R\) 和平移向量 \(t\) )。 用数学公式描述如下: 基本公式: \[\omega \boldsymbol{p}=KP^C=K(R_{CW}\times P^W+t^C_{CW})\] 其中, \(\boldsymbol{p}\) 为点在像素坐标系下的坐标, \(P^C\) 为点在相机坐标系下的坐标, \(P^W\) 为点在世界坐标系下的坐标, \(\omega\) 为点的深度, \(K\) 为相机的内参矩阵, \(R_{CW}\) 和 \(t^C_{CW}\) 为从世界坐标系到相机坐标系的位姿转换。 已知 : \(n\) 个点在 世界坐标系 下的坐标 \(P_1^W,P_2^W,...,P_n^W\) ,这些点相应在 像素坐标系 下的坐标...
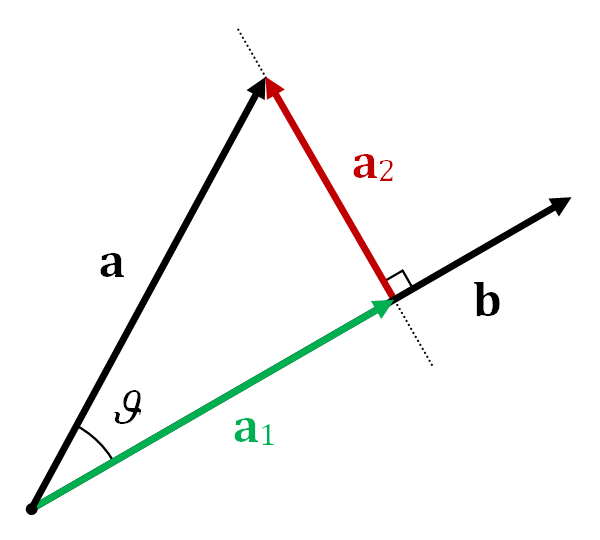
对于向量的三维旋转问题,给定旋转轴和旋转角度,用罗德里格斯(Rodrigues)旋转公式可以得出旋转后的向量。另外,罗德里格斯旋转公式可以用旋转矩阵表示,即将三维旋转的轴-角(axis-angle)表示转变为旋转矩阵表示。 向量投影(Vector projection) 向量 \(a\) 在非零向量 \(b\) 上的向量投影指的是 \(a\) 在平行于向量 \(b\) 的直线上的正交投影。结果是一个平行于 \(b\) 的向量,定义为 \(\mathbf{a}_1=a_1\hat{\mathbf{b}}\) ,其中, \(\mathbf{a}_1\) 是一个标量,称为 \(a\) 在 \(b\) 上的标量投影, \(\hat{\mathbf{b}}\) 是与 \(b \) 同向的单位向量。 \(a_1=\left\Vert\mathbf{a}\right\Vert\cos\theta=\mathbf{a}\cdot \hat{\mathbf{b}}=\mathbf{a}\cdot\frac{\mathbf{b}}{\left\Vert\mathbf{b}\right\Vert}\)...
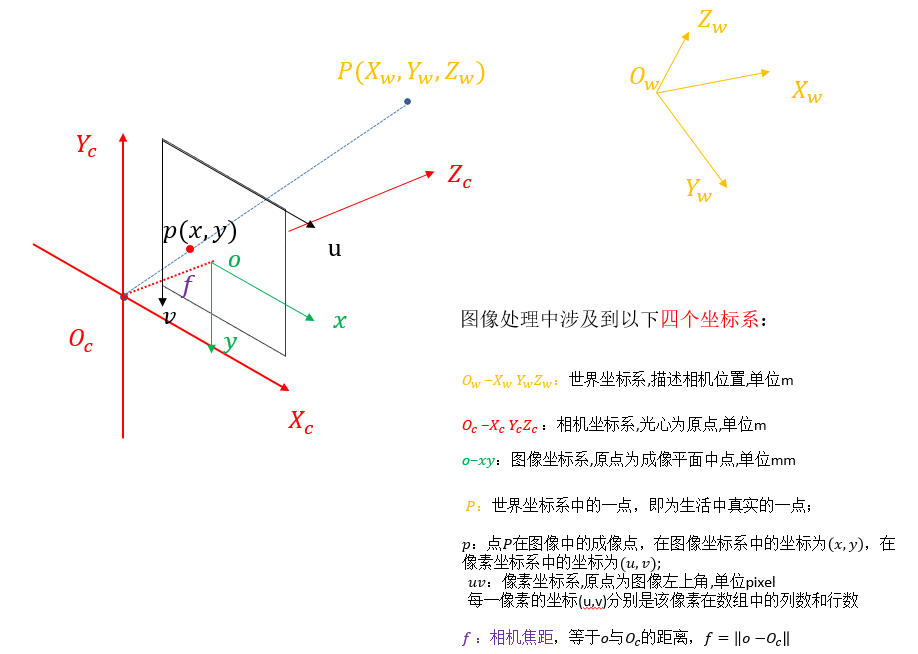
为什么要进行相机标定? 先说结论: 建立相机成像几何模型并矫正透镜畸变 。 建立相机成像几何模型 :计算机视觉的首要任务就是要通过拍摄到的图像信息获取到物体在真实三维世界里相对应的信息,于是,建立物体从三维世界映射到相机成像平面这一过程中的几何模型就显得尤为重要,而这一过程最关键的部分就是要得到相机的 内参和外参 (后文有具体解释)。 矫正透镜畸变 :我们最开始接触到的成像方面的知识应该是有关小孔成像的,但是由于这种成像方式只有小孔部分能透过光线就会导致物体的成像亮度很低,于是聪明的人类发明了透镜。虽然亮度问题解决了,但是新的问题又来了:由于透镜的制造工艺,会使成像产生多种形式的 畸变, 于是为了去除畸变(使成像后的图像与真实世界的景象保持一致),人们计算并利用 畸变系数 来矫正这种像差。(虽然理论上可以设计出不产生畸变的透镜,但其制造工艺相对于球面透镜会复杂很多,so相对于复杂且高成本的制造工艺,人们更喜欢用脑子来解决……) 相机标定的原理...

问题:两条平行线可以相交于一点 在欧氏几何空间,同一平面的两条平行线不能相交,这是我们都熟悉的一种场景。 然而,在透视空间里面,两条平行线可以相交,例如:火车轨道随着我们的视线越来越窄,最后两条平行线在无穷远处交于一点。 欧氏空间(或者笛卡尔空间)描述2D/3D几何非常适合,但是这种方法却不适合处理透视空间的问题(实际上,欧氏几何是透视几何的一个子集合),2维笛卡尔坐标可以表示为 \((x,y)\) 。 如果一个点在无穷远处,这个点的坐标将会 \((∞,∞)\) ,在欧氏空间,这变得没有意义。 平行线在透视空间的无穷远处交于一点,但是在欧氏空间却不能,数学家发现了一种方式来解决这个问题。 方法:齐次坐标 简而言之,齐次坐标就是用 \(N+1\) 维来代表 \(N\) 维坐标 我们可以在一个2D笛卡尔坐标末尾加上一个额外的变量 \(w\) 来形成2D齐次坐标,因此,一个点 \((X,Y)\) 在齐次坐标里面变成了 \((x,y,w)\) ,并且有 \[X = \frac{x}{w} \qquad Y = \frac{y}{w}\] 例如,笛卡尔坐标系下 \((1,2)\)...
Self-Supervised
2026-01-23

如果把 近几年对比学习在视觉领域有代表性的工作做一下总结,那么对比学习的发展历程大概可以分为四个阶段: 百花齐放 这个阶段代表性工作有InstDisc(instance discrimination,)、CPC、CMC等。在这个阶段中,方法、模型、目标函数、代理任务都还没有统一,所以说是一个百花齐放的时代 CV双雄 代表作有MoCo v1、SimCLR v1、MoCo v2、SimCLR v2;CPC、CMC的延伸工作、SwAV等。这个阶段发展非常迅速,有的工作间隔甚至不到一个月,ImageNet上的成绩基本上每个月都在被刷新。 不用负样本 BYOL及其改进工作、SimSiam(CNN在对比学习中的总结性工作) transformer MoCo v3、DINO。这个阶段,无论是对比学习还是最新的掩码学习,都是用Vision Transformer做的。 第一阶段:百花齐放(2018-2019Mid) InstDisc(instance discrimination) 这篇文章提出了个体判别任务(代理任务)以及 memory bank ,非常经典,后人给它的方法起名为InstDisc。...
Self-Supervised
2026-01-23
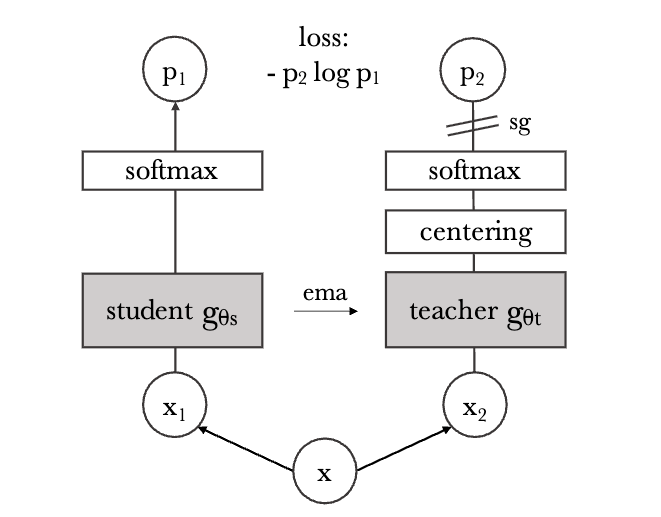
DINO Emerging Properties in Self-Supervised Vision Transformers 论文地址: arxiv.org/pdf/2104.14294 DINO摇摆到了动量式更新,果然【加动量】还是比【只用梯度停止】香。DINO的名字来自于Self- di stillation with no labels中的蒸馏和No标签。 DINO的训练步骤 其实以前的对比学习方案也可以理解为知识蒸馏,DINO里更具体得描述了知识蒸馏的含义。 下图展示了一个样本通过数据增强得到一对views \((x_1,x_2)\) 。注意DINO后面还会使用更复杂的裁剪和对比方案,但这里简单起见先不考虑那些。模型将输入图像的两种不同的随机变换 \(x_1\) 和 \(x_2\) 分别传递给学生和教师网络。 这两个网络具有相同的架构,但参数不同 。教师网络的输出以batch内计算的平均值,进行中心化(减去均值)。每个网络输出一个 \(K\)...