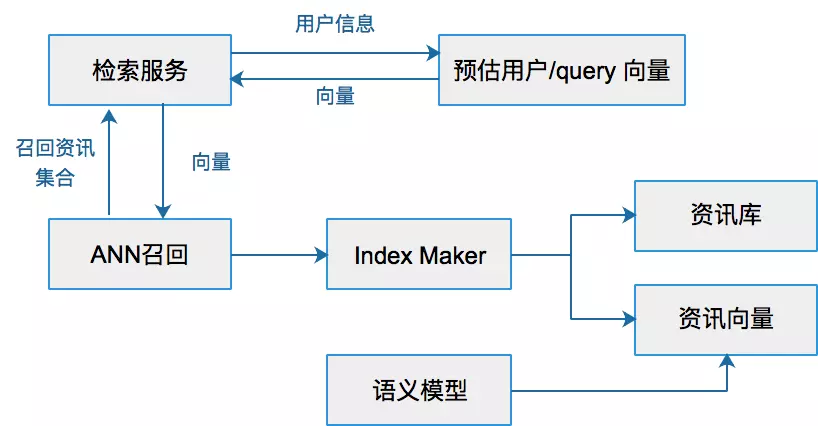
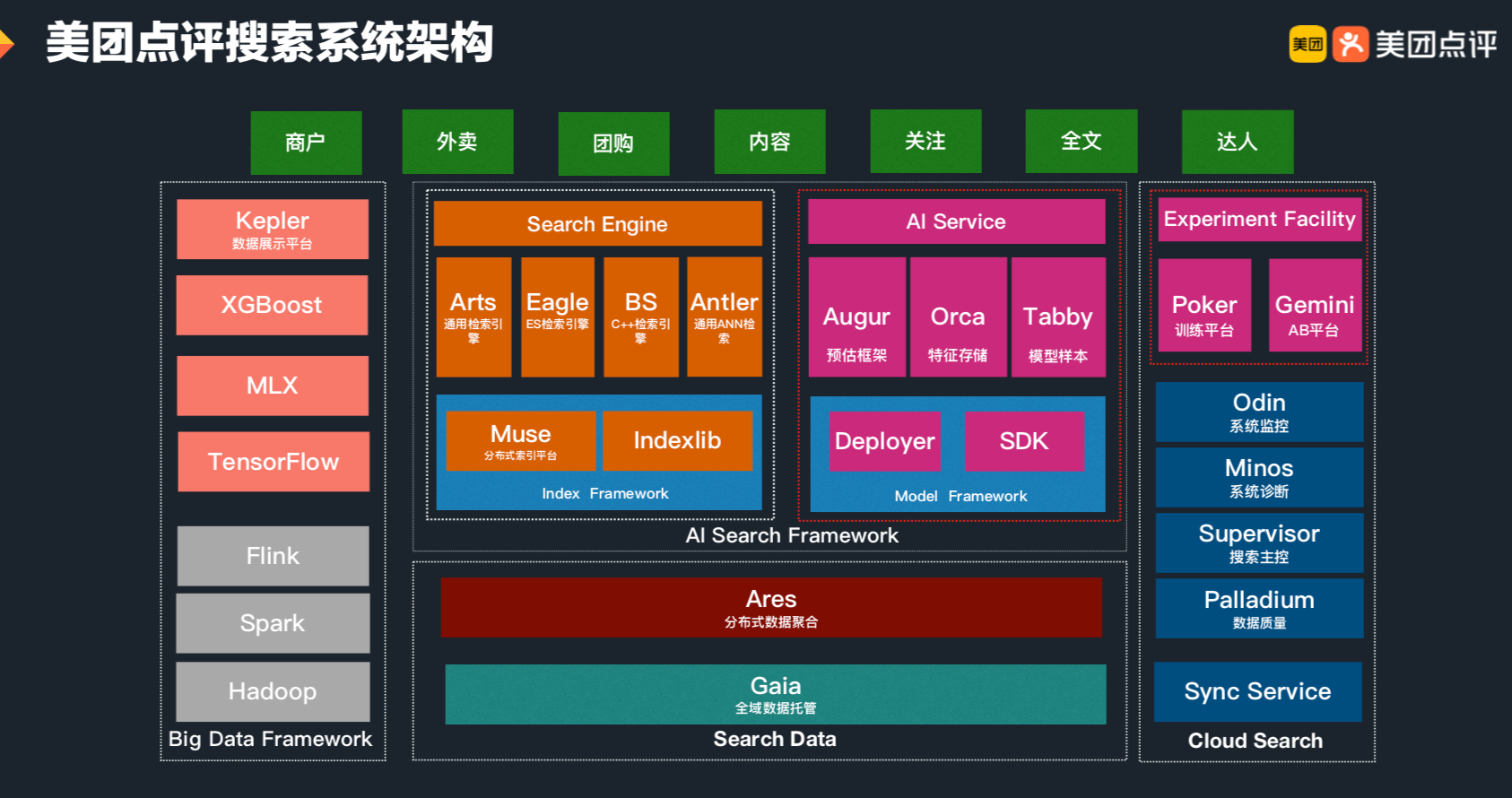
Python
2026-01-11
通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”,继承的过程,就是从一般到特殊的过程。在某些 OOP 语言中,一个子类可以继承多个基类。但是一般情况下,一个子类只能有一个基类,要实现多重继承,可以通过多级继承来实现 python2中经典类和新式类的继承方式不同,经典类采用深度优先搜索的继承,新式类采用的是广度优先搜索的继承方式 python3中经典类和新式类的继承方式都采用的是都采用广度优先搜索的继承方式 [代码] [代码] 举个例子来说明:现有4个类,A,B,C,D类,D类继承于B类和C类,B类与C类继承于A类。class D(B,C) 实例化D类 深度优先 现在构造函数的继承情况为: 若D类有构造函数,则重写所有父类的继承 若D类没有构造函数,B类有...