
Pycharm 的图形化界面虽然好用,但是在某些场景中,是无法使用的。而 Python 本身已经给我们提供了一个调试神器 pdb. 准备文件 在调试之前先将这两个文件准备好(做为演示用),并放在同级目录中。 utils.py [代码] pdb_demo.py [代码] 进入调试模式 主要有两种方法 做为脚本调用,方法很简单,就像正常执行python脚本一样,只是多加了m pdb [代码] 使用这个方式进入调试模式,会在脚本的第一行开始单步调试。 对于单文件的脚本并没有什么问题,如果是一个大型的项目,项目里有很多的文件,使用这种方式只能大大降低我们的效率。 一般情况下,都会直接在你需要的地方打一个断点,那如何打呢? 只需在你想要打断点的地方加上这两行。 [代码] 然后执行时,也不需要再指定m ...
Python
2026-01-11
通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”,继承的过程,就是从一般到特殊的过程。在某些 OOP 语言中,一个子类可以继承多个基类。但是一般情况下,一个子类只能有一个基类,要实现多重继承,可以通过多级继承来实现 python2中经典类和新式类的继承方式不同,经典类采用深度优先搜索的继承,新式类采用的是广度优先搜索的继承方式 python3中经典类和新式类的继承方式都采用的是都采用广度优先搜索的继承方式 [代码] [代码] 举个例子来说明:现有4个类,A,B,C,D类,D类继承于B类和C类,B类与C类继承于A类。class D(B,C) 实例化D类 深度优先 现在构造函数的继承情况为: 若D类有构造函数,则重写所有父类的继承 若D类没有构造函数,B类有...
Python
2026-01-11
Python程序中存储的所有数据都是对象,每一个对象有一个身份,一个类型和一个值。 看变量的实际作用,执行a = 8 这行代码时,就会创建一个值为8的int对象。 变量名是对这个"一个值为8的int对象"的引用。(也可以简称a绑定到8这个对象) 1、可以通过id()来取得对象的身份 这个内置函数,它的参数是a这个变量名,这个函数返回的值 是这个变量a引用的那个"一个值为8的int对象"的内存地址。 [代码] 2、可以通过type()来取得a引用对象的数据类型 [代码] 3、对象的值 当变量出现在表达式中,它会被它引用的对象的值替代。 总结:类型是属于对象,而不是变量。变量只是对对象的一个引用。 对象有可变对象和不可变对象之分。 Python函数传递参数到底是传值还是引用? 传值、引用这个是c...
DFS
计算几何(Computational Geometry),是一系列使用计算机解决几何问题的算法。与解析几何相比,计算几何更适合计算机运算,精度较高,运算速度较快,并且易于编写。 浮点误差 程序设计中,考虑到浮点数 double 有精度误差,在比较时,通常允许一定的误差,即对于两个数 a 、 b ,如果 [Math] ,则认为 a=b 。一般根据题目要求, d (代码中命名为 EPS)取一个较小值,如 10^{8} 。 [代码] 向量 向量(vector)是一个有大小和方向的量,在几何中,它被表示为带箭头的线段。向量可以用起点和终点的坐标来表示 —— 从点 A到点B 的向量表示为 [Math] 。 向量的书写,两个大写字母上加一个箭头(表示方向) [Math] 向量没有位置,即向量可以在平面内...
杂七杂八
2026-01-11

分布式深度学习里的通信严重依赖于规则的集群通信,诸如 allreduce, reducescatter, allgather 等,因此,实现高度优化的集群通信,以及根据任务特点和通信拓扑选择合适的集群通信算法至关重要。 本文以数据并行经常使用的 allreduce 为例来展示集群通信操作的数学性质。 Allreduce 在干什么? 如图 1 所示,一共 4个设备,每个设备上有一个矩阵(为简单起见,我们特意让每一行就一个元素),allreduce 操作的目的是,让每个设备上的矩阵里的每一个位置的数值都是所有设备上对应位置的数值之和。 如图 2 所示, allreduce 可以通过 reducescatter 和 allgather 这两个更基本的集群通信操作来实现。基于 ring 状通信可以高...
Algorithm
2026-01-11
题目 给定一个无序的数组,找出数组在排序之后,相邻元素之间最大的差值。 如果数组元素个数小于 2,则返回 0。 Example 1: [代码] 解题思路:如果进行排序,这里会超时。采用桶排序 排序算法 的思想,可以在线性时间解决。 1. 首先建立桶,每个桶中只需要存放这个桶中元素的最大值和最小值。 1. 我们期望将数组中的各个数等距离分配,也就是每个桶的长度相同,也就是对于所有桶来说,桶内最大值减去桶内最小值都是一样的。可以当成公式来记。 1. 确定桶的数量,最后的加一保证了数组的最大值也能分到一个桶。为什么需要这样规定桶的尺寸呢?因为这样可以让最大的间距的两个元素在两个不同的桶中。可以证明一下,因为我们用元素范围之差除以元素个数,所以桶的尺寸就是平均的元素间距,显然最大间距的两个元素不可能...
Algorithm
2026-01-11

1. 可以重复选取 给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。 candidates 中的数字可以无限制重复被选取。 画出树状搜索图如下, 为了去除重复的情况, 我们需要按照某种顺序搜索,具体做法是:每一次搜索的时候,设置下一轮搜索的起点 [代码] 2. 不能被重复选取 与上面的区别在于 1. index每次不要重复搜索,而是去寻找下一个 1. 排除重复的元素 [代码]
01背包 描述 有N件物品和一个容量为V的背包。 第i件物品的体积是vi,价值是wi。 求解将哪些物品装入背包,可使这些物品的总体积不超过背包流量,且总价值最大。 二维动态规划 f[i][j] 表示只看前i个物品,总体积是j的情况下,总价值最大是多少。 result = max(f[n][0V]) f[i][j]: 不选第i个物品:f[i][j] = f[i1][j]; 选第i个物品:f[i][j] = f[i1][jv[i]] + w[i](v[i]是第i个物品的体积) 两者之间取最大。 初始化:f[0][0] = 0 代码如下: [代码] 一维动态优化 从上面二维的情况来看,f[i] 只与f[i1]相关,因此只用使用一个一维数组[0v]来存储前一个状态。那么如何来实现呢? 第一个问题:状...
Algorithm
2026-01-11
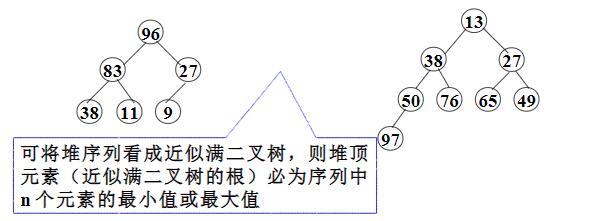
起步 heapq 模块实现了适用于Python列表的最小堆排序算法。 堆是一个树状的数据结构,其中的子节点都与父母排序顺序关系。因为堆排序中的树是满二叉树,因此可以用列表来表示树的结构,使得元素 N 的子元素位于 2N + 1 和 2N + 2 的位置(对于从零开始的索引)。 本文内容将分为三个部分,第一个部分简单介绍 heapq 模块的使用;第二部分回顾堆排序算法;第三部分分析heapq中的实现。 heapq 的使用 创建堆有两个基本的方法:heappush() 和 heapify(),取出堆顶元素用 heappop()。 heappush() 是用来向已有的堆中添加元素,一般从空列表开始构建: [代码] 如果数据已经在列表中,则使用 heapify() 进行重排: [代码] 回顾堆排序算...
计数排序、基数排序、桶排序则属于非比较排序,算法时间复杂度O(n),优于比较排序。但是也有弊端,会多占用一些空间,相当于是用空间换时间。 1. 计数排序: 计数排序的基本思想是:对每一个输入的元素a[i],确定小于 a[i] 的元素个数。所以可以直接把 a[i] 放到它输出数组中的位置上。假设有5个数小于 a[i],所以 a[i] 应该放在数组的第6个位置上。 实现代码如下: [代码] 2. 桶排序: 桶排序的基本思想是:把数组a划分为n个大小相同子区间(桶),每个子区间各自排序,最后合并。桶排序要求数据的分布必须均匀,不然可能会失效。计数排序是桶排序的一种特殊情况,可以把计数排序当成每个桶里只有一个元素的情况。 [代码] 算法实现步骤 1. 根据待排序集合中最大元素和最小元素的差值范围和映...
Algorithm
2026-01-11
题目说明 在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。 示例 1: 输入: [3,2,1,5,6,4] 和 k = 2 输出: 5 示例 2: 输入: [3,2,3,1,2,4,5,5,6] 和 k = 4 输出: 4 题解 使用快排的思想 [代码]