
236. 二叉树的最近公共祖先 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百 度百科中最近公共祖先的定义为:“对于有根树 \(T\) 的两个节点 \(p\) 、 \(q\) ,最近公共祖先表示为一个节点 \(x\) ,满足 \(x\) 是 \(p\) 、 \(q \) 的祖先且 \(x\) 的深度尽可能大( 一个节点也可以是它自己的祖先 )。” 示例 1: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。 示例 2: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。 示例 3: 输入:root = [1,2], p = 1, q = 2
输出:1 提示: 树中节点数目在范围 [2, 10 5 ] 内。 -10 9 <= Node.val <= 10 9 所有 Node.val...
Algorithm
2026-02-25
实现 方式一:使用 heapq 标准库 这是 Python 最快、最节省内存的方式,因为 heapq 底层是用 C 语言实现的。 小顶堆 (Min Heap) Python 的 heapq 默认就是小顶堆。 import heapq
# 初始化
min_heap = []
# 添加元素 O(log N)
heapq.heappush(min_heap, 5)
heapq.heappush(min_heap, 2)
heapq.heappush(min_heap, 8)
# 查看堆顶 O(1)
print(min_heap[0]) # 输出: 2
# 弹出堆顶 O(log N)
pop_val = heapq.heappop(min_heap)
print(pop_val) # 输出: 2
print(min_heap) # 输出: [5, 8] (注意:堆内部不一定有序,但堆顶一定是最小的)
# 将已有的列表转化为堆 O(N)
nums = [5, 7, 1, 3]
heapq.heapify(nums)
print(nums) #...
堆和优先队列的关系 这是一个非常经典且核心的计算机科学概念问题。一言以蔽之: 优先队列(Priority Queue)是逻辑接口(ADT),而堆(Heap)是实现这个接口最高效的物理数据结构。 它们的关系可以类比为 “接口(Interface)” 与 “实现类(Implementation)” 的关系,或者 “汽车(功能)”与 “发动机(核心组件)” 的关系。 优先队列 (Priority Queue) —— 逻辑层 (ADT) 定义 :它是一种 抽象数据类型 (Abstract Data Type, ADT) 。它定义了数据的 行为 ,而不是数据的存储方式。 规则 :普通的队列是“先进先出”(FIFO),而优先队列是 “优先级最高的先出” 。 核心操作 : insert(item, priority) : 插入一个带优先级的元素。 deleteMax() 或 deleteMin() : 取出并删除优先级最高(或最低)的元素。 peek() : 查看优先级最高的元素。 堆 (Heap) —— 物理层 (Data Structure) 定义 :它是一种具体的 数据结构 。通常指 二叉堆...
引入 在具体讲何为「背包 dp」前,先来看如下的例题: 题意概要:有 \( 𝑛\) 个物品和一个容量为 \( 𝑊\) 的背包,每个物品有重量 \(𝑤_𝑖\) 和价值 \(𝑣_𝑖\) 两种属性,要求选若干物品放入背包使背包中物品的总价值最大且背包中物品的总重量不超过背包的容量. 在上述例题中,由于每个物体只有两种可能的状态(取与不取),对应二进制中的 0 和 1,这类问题便被称为「0-1 背包问题」. 0-1背包 解释 例题中已知条件有第 \(𝑖\) 个物品的重量 \(𝑤_𝑖\) ,价值 \(𝑣_𝑖\) ,以及背包的总容量 \(𝑊\) . 设 DP 状态 \(𝑓_{𝑖,𝑗} \) 为在只能放前 \(𝑖\) 个物品的情况下,容量为 \(𝑗\) 的背包所能达到的最大总价值. 考虑转移.假设当前已经处理好了前 \(𝑖 −1 \) 个物品的所有状态,那么对于第 \(𝑖\) 个物品,当其不放入背包时,背包的剩余容量不变,背包中物品的总价值也不变,故这种情况的最大价值为 \(𝑓_{𝑖−1,𝑗}\) ;当其放入背包时,背包的剩余容量会减小 \(𝑤_𝑖\) ,背包中物品的总价值会增大 \(𝑣_𝑖\)...

简介 生成树(spanning tree) 在图论中,无向图 \(G=(V,E)\) 的生成树(spanning tree)是具有 \(G\) 的全部顶点,但边数最少的联通子图。假设 \(G\) 中一共有 \(n\) 个顶点,一颗生成树满足下列条件 \(n\) 个顶点; \(n-1\) 条边; \(n\) 个顶点联通; 一个图的生成树可能有多个。 最小生成树(minimum spanning tree, MST)/最小生成森林 :联通加权无向图中边缘权重加和最小的生成树。给定无向图 \(G=(V,E)\) , \((u,v)\) 代表顶点 \(u\) 与顶点 \(v\) 的边, \(w(u,v)\) 代表此边的权重,若存在生成树T使得: \[w(T) = \sum_{(u,v)\in T}w(w,v)\] 最小,则 \(T\) 为 \(G\) 的最小生成树。对于非连通无向图来说,它的每一 连通分量 同样有最小生成树,它们的并被称为 最小生成森林 。最小生成树除了继承生成树的性质之外,还存在下面两个特点: 当图的每一条边的权值都相同时,该图的所有生成树都是最小生成树;...

160. 相交链表 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交 : 题目数据 保证 整个链式结构中不存在环。 注意 ,函数返回结果后,链表必须 保持其原始结构 。 自定义评测: 评测系统 的输入如下(你设计的程序 不适用 此输入): intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0 listA - 第一个链表 listB - 第二个链表 skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数 skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数 评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。 示例 1: 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2,...
Large Model
2026-01-26
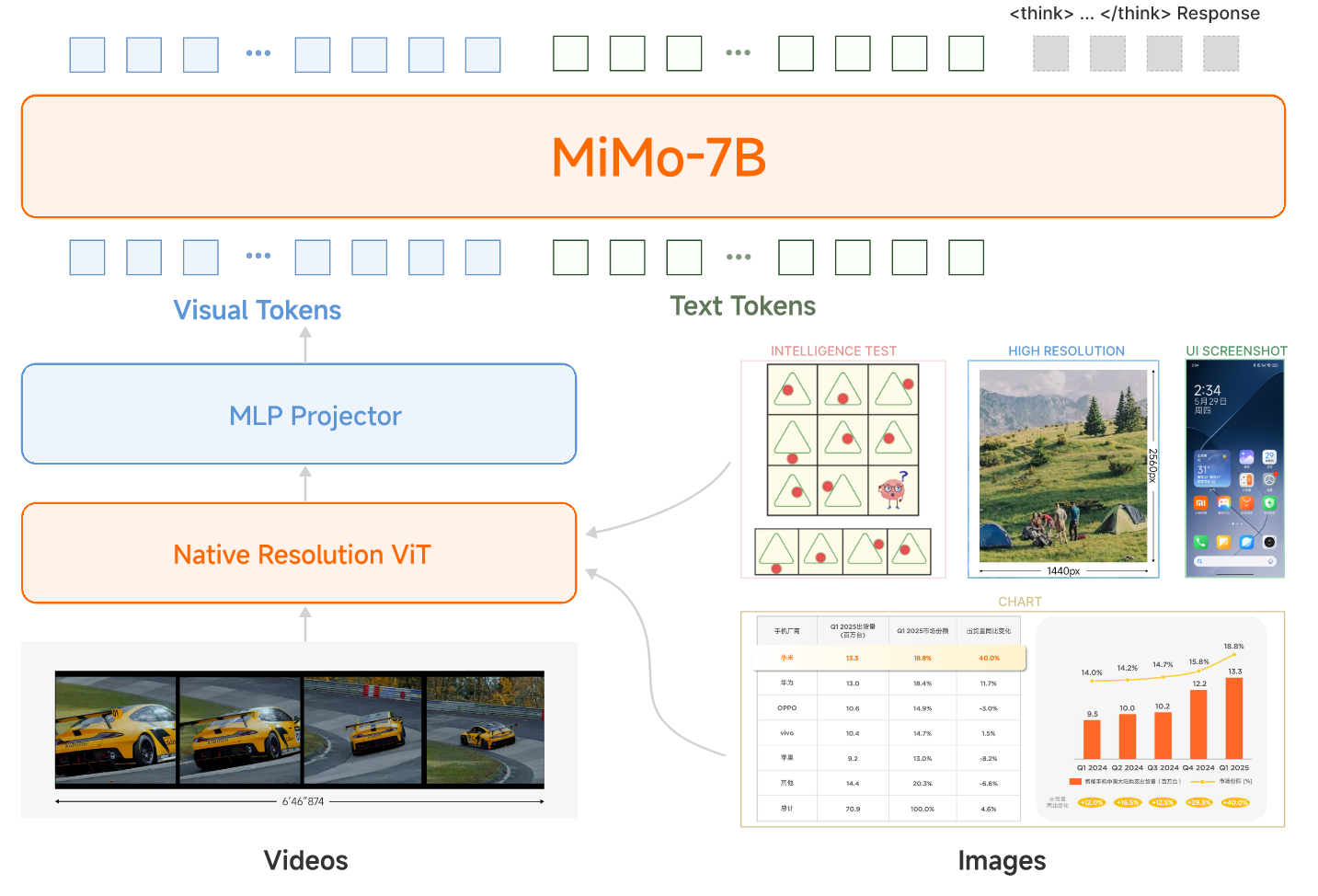
概述 小米团队近日发布了MIMO-VL-7B-SFT和MIMO-VL-7B-RL,这是两个强大的视觉语言模型,MIMO-VL-7B-RL在40个评估任务中的35个上优于QWEN2.5-VL-7B,对于GUI Grounding任务,它在OSWorld-G上设置了一个新标准,甚至超过了UI-TARS等专业模型。模型通过四个阶段的预训练(2.4T Token)与Mixed On-policy 强化(MORL)整合了多样化的奖励信号。 在文章中,作者提到了两个重要的发现: 从Pre-Traing 训练阶段中加入高质量且覆盖广的推理数据对于强化模型性能至关重要。 Mixed On-policy 强化学习进一步增强了模型的性能,同时实现了稳定的同时改进仍然在性能方面具有挑战性。 Pre-Training 模型结构 整个模型还是采用了VIT-MLP-LLM的结构,具体来说,视觉模型采用了Qwen2.5-VL中的视觉encoder,LLM采用了自家的语言模型MiMo-7B-Base。 整个Pretraining采用了四个阶段的训练,每个阶段采用的数据,模型训练参数和模型参数如下面两表所示...
Large Model
2026-01-26

简介 该工作建立了一个 GCG(Grounded Conversation Generation ) 的数据集和对应多模态大模型,与之前的工作主要的区别在于针对输入图像,可以生成grounding pixel-level理解的语言对话,如下图示例所示: Model Automated Dataset Annotation Pipeline level 1: Object locatlization and attributes 1. Landmark Categorization 基于 LLaVA 模型对图像做场景的分类, 包含主要场景和细粒度场景。 就是对数据集整体做一个大的类别标签和子类别标签,做场景的划分 def get_main_prompt(model, conv_mode="llava_v1"):
options = ["Indoor scene", "Outdoor scene", "Transportation scene", "Sports and recreation scene"]
qs = (f"Categorize the image...
Large Model
2026-01-26
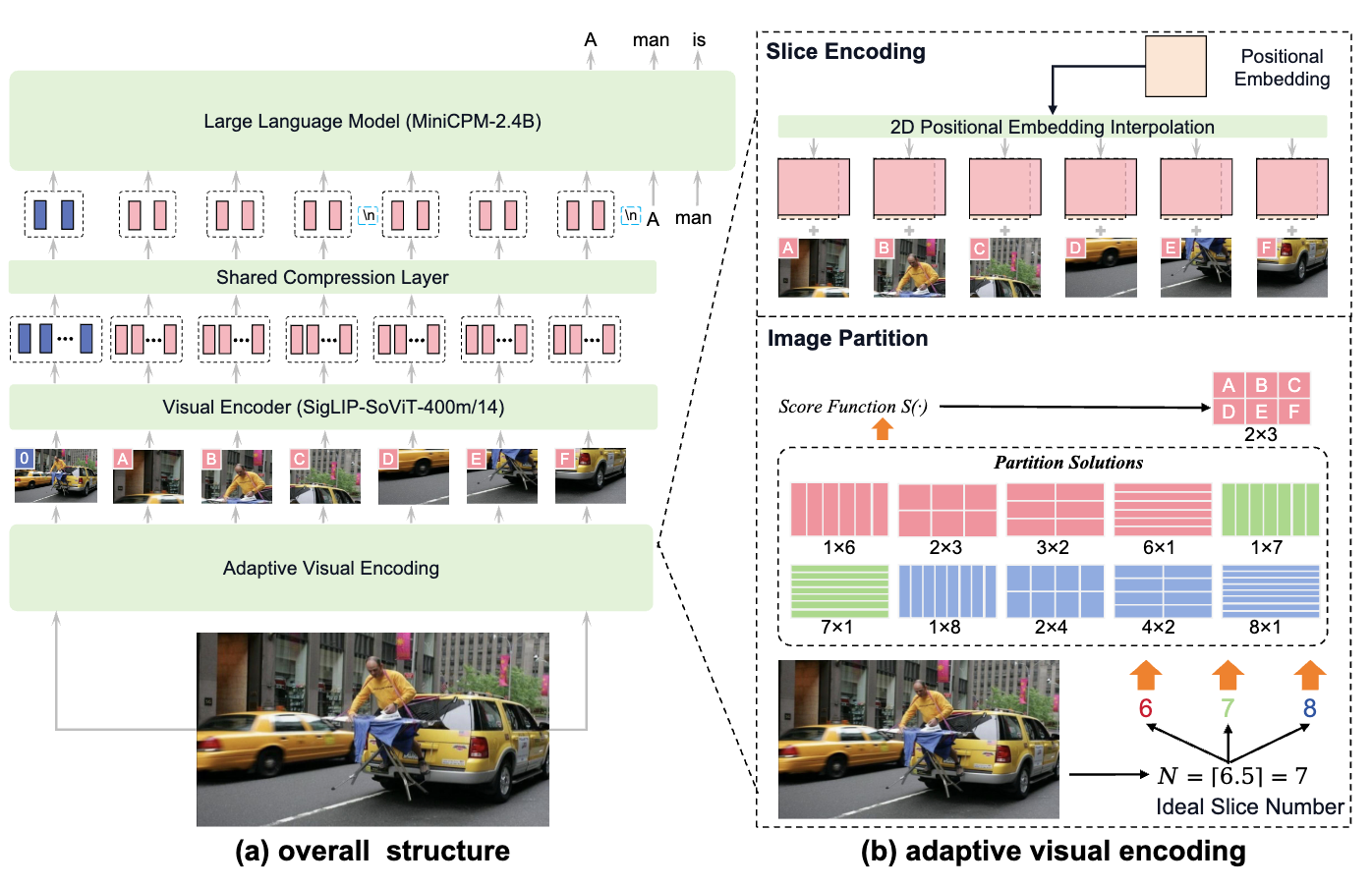
MiniCPM-V系列是面壁智能推出的小参数量的开源多模态大模型,没有超过9B的版本。主打小而强。 MiniCPM-Llama3-V 2.5 这版有论文了,详细写。应该也是2.6的基础。 这一版在 OpenCompass 评估中优于强大的 GPT-4V-1106、Gemini Pro 和 Claude 3。 能力 支持最高1.8M像素的高分辨率图像输入(例如1344*1344),支持任意长宽比图像 强大的OCR,OCRBench 上优于 GPT-4V、Gemini Pro 和 Qwen-VL-Max,支持table-to-markdown 可信,基于RLAIF-V技术做了对齐,减少幻觉,更符合人类喜好 多语言,基于VisCPM技术,支持30多种语言 系统地集成了一套端侧部署优化技术 模型架构 基本架构 三部分:visual encoder, 压缩层, LLM visual encoder:SigLIP SoViT-400m/14 压缩层:单层交叉注意力 LLM:每一代都不同 Adaptive Visual Encoding...
Large Model
2026-01-26
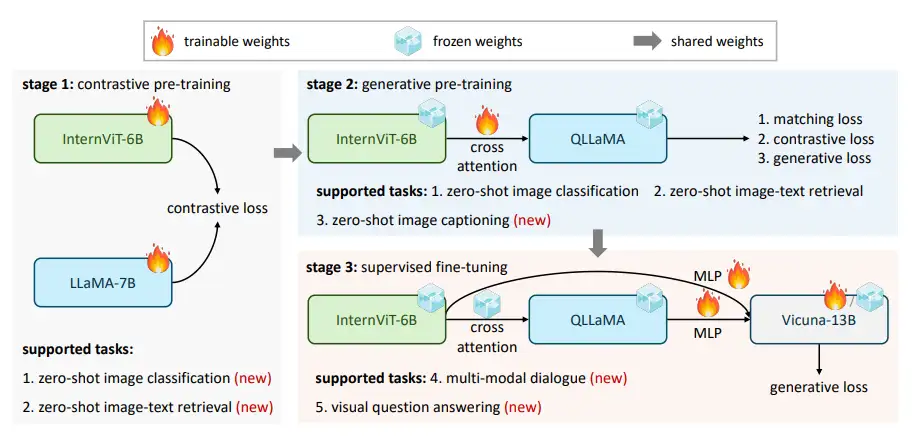
InternVL Blog: https://internvl.github.io/blog/ Github: https://github.com/OpenGVLab/InternVL InternVL 1.0 对齐策略 语言模型和视觉模型各自发展,各有突破,但如何让语言模型会看图,或者让视觉模型会说话?为了将视觉模型与语言模型进行连接,对齐如同“胶水”,将两种模型链接在一起,如使用QFormer或线性投影这样的轻量级“胶水”层,来形成视觉-语言模型,如InstructBLIP和LLaVA,但均存在局限性。 现有对齐策略的局限性 参数规模的不一致: LLM的参数规模已经达到1000亿,而广泛使用的VLLM的视觉编码器仍在10亿参数左右。这种差距可能导致LLM的能力无法被充分利用。 特征表示的不一致: 在纯视觉数据上训练的视觉模型或与BERT系列对齐的模型往往与LLM存在表示上的不一致。 连接效率低下: “胶水”层通常是轻量的、随机初始化的,可能无法捕捉到多模态理解和生成所需的丰富的跨模态交互和依赖关系。 InternVL引入全新的对齐策略...
NLP
2026-01-24

旋转式位置编码(ROPE) 原始的Sinusoidal位置编码总的感觉是一种“想要成为相对位置编码的绝对位置编码”。一般来说,绝对位置编码具有实现简单、计算速度快等优点,而相对位置编码则直接地体现了相对位置信号,跟我们的直观理解吻合,实际性能往往也更好。由此可见,如果可以通过绝对位置编码的方式实现相对位置编码,那么就是“集各家之所长”、“鱼与熊掌兼得”了。Sinusoidal位置编码隐约做到了这一点,但并不够好。 本文将会介绍我们自研的Rotary Transformer(RoFormer)模型,它的主要改动是应用了笔者构思的“旋转式位置编码(Rotary Position Embedding,RoPE)”,这是一种配合Attention机制能达到“绝对位置编码的方式实现相对位置编码”的设计。而也正因为这种设计,它还是目前唯一一种可用于线性Attention的相对位置编码。 RoFormer:https://github.com/ZhuiyiTechnology/roformer 基本思路 这里简要介绍过RoPE: Transformer位置编码...
Large Model
2026-01-23

总览 由于是“图文多模态”,还是要从“图”和“文”的表征方法讲起,然后讲清楚图文表征的融合方法。这里只讲两件事情: 视觉表征 :分为两个部分问题,一是如何合理建模视觉输入特征,二是如何通过预训练手段进行充分学习表征,这两点是基于视觉完成具体算法任务的基础; 视觉与自然语言的对齐(Visul Language Alignment)或融合 :目的是将视觉和自然语言建模到同一表征空间并进行融合,实现自然语言和视觉语义的互通,这点同样离不开预训练这一过程。模态对齐是处理多模态问题的基础,也是现在流行的多模态大模型技术前提。 对于视觉表征,从发展上可以分为卷积神经网络(CNN)和Vision Transformer(VIT)两大脉络,二者分别都有各自的表征、预训练以及多模态对齐的发展过程。而对于VIT线,另有多模态大模型如火如荼的发展,可谓日新月异。 CNN:视觉理解的一代先驱 点击展开 卷积视觉表征模型和预训练...