
236. 二叉树的最近公共祖先 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百 度百科中最近公共祖先的定义为:“对于有根树 \(T\) 的两个节点 \(p\) 、 \(q\) ,最近公共祖先表示为一个节点 \(x\) ,满足 \(x\) 是 \(p\) 、 \(q \) 的祖先且 \(x\) 的深度尽可能大( 一个节点也可以是它自己的祖先 )。” 示例 1: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
解释:节点 5 和节点 1 的最近公共祖先是节点 3 。 示例 2: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。 示例 3: 输入:root = [1,2], p = 1, q = 2
输出:1 提示: 树中节点数目在范围 [2, 10 5 ] 内。 -10 9 <= Node.val <= 10 9 所有 Node.val...
Algorithm
2026-02-25
实现 方式一:使用 heapq 标准库 这是 Python 最快、最节省内存的方式,因为 heapq 底层是用 C 语言实现的。 小顶堆 (Min Heap) Python 的 heapq 默认就是小顶堆。 import heapq
# 初始化
min_heap = []
# 添加元素 O(log N)
heapq.heappush(min_heap, 5)
heapq.heappush(min_heap, 2)
heapq.heappush(min_heap, 8)
# 查看堆顶 O(1)
print(min_heap[0]) # 输出: 2
# 弹出堆顶 O(log N)
pop_val = heapq.heappop(min_heap)
print(pop_val) # 输出: 2
print(min_heap) # 输出: [5, 8] (注意:堆内部不一定有序,但堆顶一定是最小的)
# 将已有的列表转化为堆 O(N)
nums = [5, 7, 1, 3]
heapq.heapify(nums)
print(nums) #...
堆和优先队列的关系 这是一个非常经典且核心的计算机科学概念问题。一言以蔽之: 优先队列(Priority Queue)是逻辑接口(ADT),而堆(Heap)是实现这个接口最高效的物理数据结构。 它们的关系可以类比为 “接口(Interface)” 与 “实现类(Implementation)” 的关系,或者 “汽车(功能)”与 “发动机(核心组件)” 的关系。 优先队列 (Priority Queue) —— 逻辑层 (ADT) 定义 :它是一种 抽象数据类型 (Abstract Data Type, ADT) 。它定义了数据的 行为 ,而不是数据的存储方式。 规则 :普通的队列是“先进先出”(FIFO),而优先队列是 “优先级最高的先出” 。 核心操作 : insert(item, priority) : 插入一个带优先级的元素。 deleteMax() 或 deleteMin() : 取出并删除优先级最高(或最低)的元素。 peek() : 查看优先级最高的元素。 堆 (Heap) —— 物理层 (Data Structure) 定义 :它是一种具体的 数据结构 。通常指 二叉堆...
引入 在具体讲何为「背包 dp」前,先来看如下的例题: 题意概要:有 \( 𝑛\) 个物品和一个容量为 \( 𝑊\) 的背包,每个物品有重量 \(𝑤_𝑖\) 和价值 \(𝑣_𝑖\) 两种属性,要求选若干物品放入背包使背包中物品的总价值最大且背包中物品的总重量不超过背包的容量. 在上述例题中,由于每个物体只有两种可能的状态(取与不取),对应二进制中的 0 和 1,这类问题便被称为「0-1 背包问题」. 0-1背包 解释 例题中已知条件有第 \(𝑖\) 个物品的重量 \(𝑤_𝑖\) ,价值 \(𝑣_𝑖\) ,以及背包的总容量 \(𝑊\) . 设 DP 状态 \(𝑓_{𝑖,𝑗} \) 为在只能放前 \(𝑖\) 个物品的情况下,容量为 \(𝑗\) 的背包所能达到的最大总价值. 考虑转移.假设当前已经处理好了前 \(𝑖 −1 \) 个物品的所有状态,那么对于第 \(𝑖\) 个物品,当其不放入背包时,背包的剩余容量不变,背包中物品的总价值也不变,故这种情况的最大价值为 \(𝑓_{𝑖−1,𝑗}\) ;当其放入背包时,背包的剩余容量会减小 \(𝑤_𝑖\) ,背包中物品的总价值会增大 \(𝑣_𝑖\)...

简介 生成树(spanning tree) 在图论中,无向图 \(G=(V,E)\) 的生成树(spanning tree)是具有 \(G\) 的全部顶点,但边数最少的联通子图。假设 \(G\) 中一共有 \(n\) 个顶点,一颗生成树满足下列条件 \(n\) 个顶点; \(n-1\) 条边; \(n\) 个顶点联通; 一个图的生成树可能有多个。 最小生成树(minimum spanning tree, MST)/最小生成森林 :联通加权无向图中边缘权重加和最小的生成树。给定无向图 \(G=(V,E)\) , \((u,v)\) 代表顶点 \(u\) 与顶点 \(v\) 的边, \(w(u,v)\) 代表此边的权重,若存在生成树T使得: \[w(T) = \sum_{(u,v)\in T}w(w,v)\] 最小,则 \(T\) 为 \(G\) 的最小生成树。对于非连通无向图来说,它的每一 连通分量 同样有最小生成树,它们的并被称为 最小生成森林 。最小生成树除了继承生成树的性质之外,还存在下面两个特点: 当图的每一条边的权值都相同时,该图的所有生成树都是最小生成树;...

160. 相交链表 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交 : 题目数据 保证 整个链式结构中不存在环。 注意 ,函数返回结果后,链表必须 保持其原始结构 。 自定义评测: 评测系统 的输入如下(你设计的程序 不适用 此输入): intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0 listA - 第一个链表 listB - 第二个链表 skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数 skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数 评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。 示例 1: 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2,...
Large Model
2026-01-20
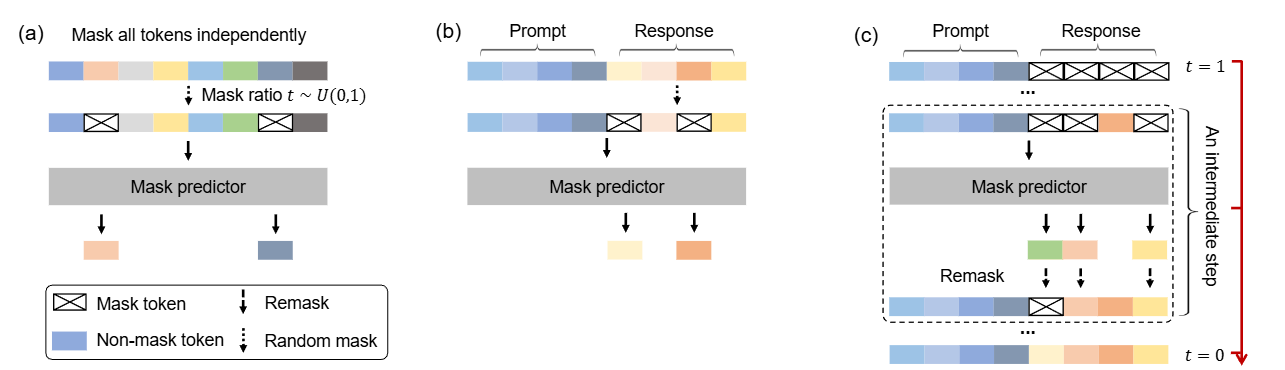
这是一篇尝试改变LLM「范式」的文章:当前主流的LLM架构都是「自回归」的,通俗地理解就是必须「从左到右依次生成」。这篇文章挑战了这一范式,探索扩散模型在 LLMs 上的可行性,通过 随机掩码 - 预测 的逆向思维,让模型学会「全局思考」。 论文: [2502.09992] Large Language Diffusion Models 背景 主流大语言模型架构:自回归模型 (Autoregressive LLMs) 过去几年, 自回归模型(Autoregressive Models, ARMs)一直是大语言模型(LLM)的主流架构。典型的自回归语言模型以Transformer解码器为基础,按照从左到右 的顺序依次预测下一个词元(token)。 形式化地,自回归模型将一个长度为 \(N\) 的文本序列 \(X=(x_1, x_2, ..., x_N)\) 的概率分解为各位置的条件概率连乘积: \[P_{\theta}(x_1, x_2, \dots, x_N) = \prod_{i=1}^{N} P_{\theta}(x_i \mid x_1, x_2, \dots,...
Large Model
2026-01-20

引言 Diffusion模型近年来在图像生成这一连续域任务中取得了显著成果,展现出强大的生成能力。然而,在文本生成这一离散域任务中整体效果仍不尽如人意,未能在该领域引起广泛关注。 去年,一篇研究离散扩散模型在文本生成的文章《Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution》获得ICML 2024的Best Paper,引发了学术界的广泛兴趣,也激发了新一轮的研究热潮。随后在2025年,越来越多高校和企业也开始积极探索基于Diffusion的文本生成方法。其中,近期备受关注的Block Diffusion也成功入选ICLR oral,进一步推动了该方向的发展。...
Generative Model
2026-01-19

💡 扩散模型:通过加噪的方式去学习原始数据的分布, 从学到的分布中去生成样本 DDPM 关键点: 1. 正向加噪是离散时间马尔可夫链:从 \(x_0\) 逐步加噪得到 \(x_1,x_2,...,x_T\) ;在合适的噪声调度与足够大的 \(T\) 下, \(x_T\) 近似服从 \( N(0,I) \) 的各向同性高斯。 2. 每一步噪声方差 \(β_t\) 满足 \(0<β_t<1\) ,通常随 \(t\) 增大;因此 \(q(x_t|x_{t-1}) \) 的均值缩放系数 \(\sqrt{1-β_t} \) 逐渐减小。 3. 训练通过最大化对数似然的变分下界(ELBO)来学习反向过程 \( p_θ(x_{t-1}|x_t)\) ,并将其参数化为高斯分布(神经网络预测均值/噪声或 score)。 4. 将目标写成 score/DSM 形式时,loss 的权重与对应噪声层的方差尺度(如 \(1-\bar{α}_t\) 或相关量)有关;采样通常是按学习到的反向转移逐步生成(祖先采样),与经典 Langevin MCMC 更新形式不同,但可在 SDE 视角下统一理解。...

进程 一个在内存中运行的应用程序。每个进程都有自己独立的一块内存空间,一个进程可以有多个线程,比如在Windows系统中,一个运行的xx.exe就是一个进程。 线程 进程中的一个执行任务(控制单元),负责当前进程中程序的执行。一个进程至少有一个线程,一个进程可以运行多个线程,多个线程可共享数据。 与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。 Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。 [代码] 上述程序输出如下(输出内容可能不同,不用太纠结下面每个线...
Generative Model
2026-01-11

ControlNet应该算是2023年文生图领域最重要的工作,它让文生图模型Stable Diffusion实现了文本之外的可控生成,让AI绘画实现了质的飞跃。这篇文章我们将简单总结一下ControlNet技术细节。 模型设计 ControlNet的模型结构如下所示,这里是直接复制一份SD的上半部分:Encoder和中间的Middle Block。 ControlNet的输入和原始的SD一样,包括noisy latents、time embedding以及text embedding。除此之外,ControlNet还需要引入额外的condition,这个condition是和原图一样大小的图像,比如canny边界图或者人体骨架图。这里并没有像SD那样采用VAE对condition进行编码,而...
杂七杂八
2026-01-11

分布式深度学习里的通信严重依赖于规则的集群通信,诸如 allreduce, reducescatter, allgather 等,因此,实现高度优化的集群通信,以及根据任务特点和通信拓扑选择合适的集群通信算法至关重要。 本文以数据并行经常使用的 allreduce 为例来展示集群通信操作的数学性质。 Allreduce 在干什么? 如图 1 所示,一共 4个设备,每个设备上有一个矩阵(为简单起见,我们特意让每一行就一个元素),allreduce 操作的目的是,让每个设备上的矩阵里的每一个位置的数值都是所有设备上对应位置的数值之和。 如图 2 所示, allreduce 可以通过 reducescatter 和 allgather 这两个更基本的集群通信操作来实现。基于 ring 状通信可以高...