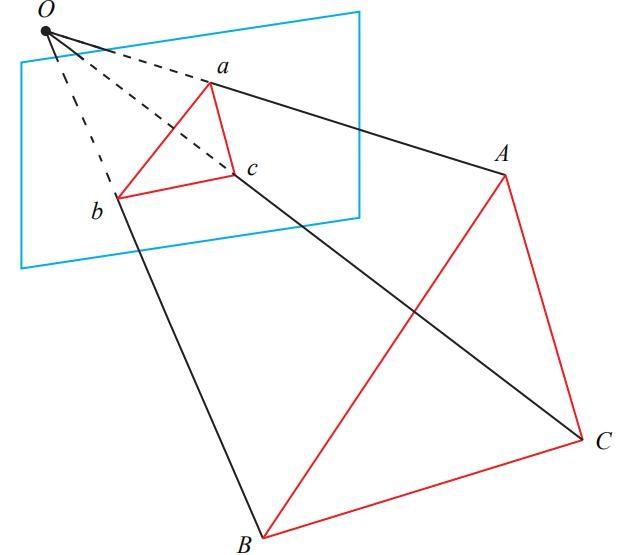
简介 PnP(Perspective-n-Point)是求解3D到2D点对运动的方法,目的是求解相机坐标系相对世界坐标系的位姿。 它描述了已知 \(n\) 个3D点的坐标(相对世界坐标系)以及这些点的像素坐标时,如何估计相机的位姿(即求解世界坐标系到相机坐标系的旋转矩阵 \(R\) 和平移向量 \(t\) )。 用数学公式描述如下: 基本公式: \[\omega \boldsymbol{p}=KP^C=K(R_{CW}\times P^W+t^C_{CW})\] 其中, \(\boldsymbol{p}\) 为点在像素坐标系下的坐标, \(P^C\) 为点在相机坐标系下的坐标, \(P^W\) 为点在世界坐标系下的坐标, \(\omega\) 为点的深度, \(K\) 为相机的内参矩阵, \(R_{CW}\) 和 \(t^C_{CW}\) 为从世界坐标系到相机坐标系的位姿转换。 已知 : \(n\) 个点在 世界坐标系 下的坐标 \(P_1^W,P_2^W,...,P_n^W\) ,这些点相应在 像素坐标系 下的坐标...
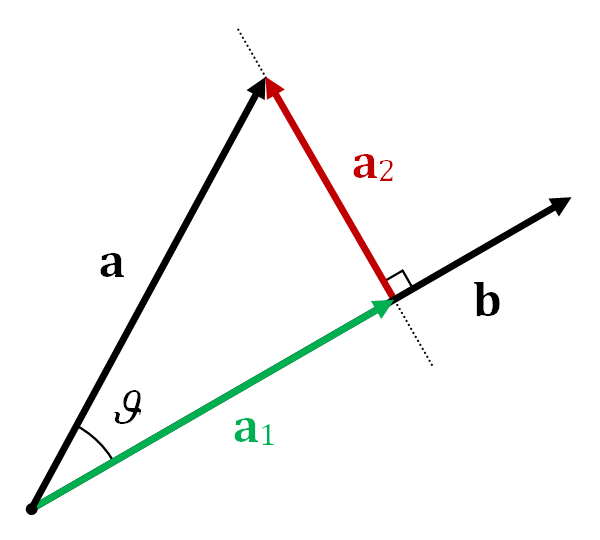
对于向量的三维旋转问题,给定旋转轴和旋转角度,用罗德里格斯(Rodrigues)旋转公式可以得出旋转后的向量。另外,罗德里格斯旋转公式可以用旋转矩阵表示,即将三维旋转的轴-角(axis-angle)表示转变为旋转矩阵表示。 向量投影(Vector projection) 向量 \(a\) 在非零向量 \(b\) 上的向量投影指的是 \(a\) 在平行于向量 \(b\) 的直线上的正交投影。结果是一个平行于 \(b\) 的向量,定义为 \(\mathbf{a}_1=a_1\hat{\mathbf{b}}\) ,其中, \(\mathbf{a}_1\) 是一个标量,称为 \(a\) 在 \(b\) 上的标量投影, \(\hat{\mathbf{b}}\) 是与 \(b \) 同向的单位向量。 \(a_1=\left\Vert\mathbf{a}\right\Vert\cos\theta=\mathbf{a}\cdot \hat{\mathbf{b}}=\mathbf{a}\cdot\frac{\mathbf{b}}{\left\Vert\mathbf{b}\right\Vert}\)...
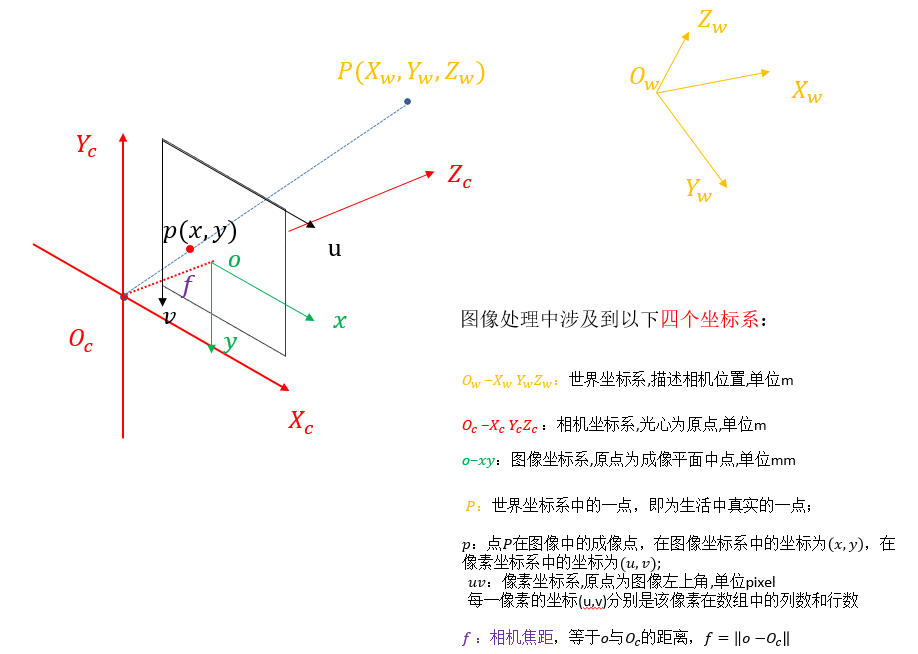
为什么要进行相机标定? 先说结论: 建立相机成像几何模型并矫正透镜畸变 。 建立相机成像几何模型 :计算机视觉的首要任务就是要通过拍摄到的图像信息获取到物体在真实三维世界里相对应的信息,于是,建立物体从三维世界映射到相机成像平面这一过程中的几何模型就显得尤为重要,而这一过程最关键的部分就是要得到相机的 内参和外参 (后文有具体解释)。 矫正透镜畸变 :我们最开始接触到的成像方面的知识应该是有关小孔成像的,但是由于这种成像方式只有小孔部分能透过光线就会导致物体的成像亮度很低,于是聪明的人类发明了透镜。虽然亮度问题解决了,但是新的问题又来了:由于透镜的制造工艺,会使成像产生多种形式的 畸变, 于是为了去除畸变(使成像后的图像与真实世界的景象保持一致),人们计算并利用 畸变系数 来矫正这种像差。(虽然理论上可以设计出不产生畸变的透镜,但其制造工艺相对于球面透镜会复杂很多,so相对于复杂且高成本的制造工艺,人们更喜欢用脑子来解决……) 相机标定的原理...

问题:两条平行线可以相交于一点 在欧氏几何空间,同一平面的两条平行线不能相交,这是我们都熟悉的一种场景。 然而,在透视空间里面,两条平行线可以相交,例如:火车轨道随着我们的视线越来越窄,最后两条平行线在无穷远处交于一点。 欧氏空间(或者笛卡尔空间)描述2D/3D几何非常适合,但是这种方法却不适合处理透视空间的问题(实际上,欧氏几何是透视几何的一个子集合),2维笛卡尔坐标可以表示为 \((x,y)\) 。 如果一个点在无穷远处,这个点的坐标将会 \((∞,∞)\) ,在欧氏空间,这变得没有意义。 平行线在透视空间的无穷远处交于一点,但是在欧氏空间却不能,数学家发现了一种方式来解决这个问题。 方法:齐次坐标 简而言之,齐次坐标就是用 \(N+1\) 维来代表 \(N\) 维坐标 我们可以在一个2D笛卡尔坐标末尾加上一个额外的变量 \(w\) 来形成2D齐次坐标,因此,一个点 \((X,Y)\) 在齐次坐标里面变成了 \((x,y,w)\) ,并且有 \[X = \frac{x}{w} \qquad Y = \frac{y}{w}\] 例如,笛卡尔坐标系下 \((1,2)\)...

160. 相交链表 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交 : 题目数据 保证 整个链式结构中不存在环。 注意 ,函数返回结果后,链表必须 保持其原始结构 。 自定义评测: 评测系统 的输入如下(你设计的程序 不适用 此输入): intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0 listA - 第一个链表 listB - 第二个链表 skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数 skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数 评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。 示例 1: 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2,...
Large Model
2026-01-23

SigLIP 概述 CLIP自提出以来在zero-shot分类、跨模态搜索、多模态对齐等多个领域得到广泛应用。得益于其令人惊叹的能力,激起了研究者广泛的关注和优化。 目前对CLIP的优化主要可以分为两大类: 其一是如何降低CLIP的训练成本; 其二是如何提升CLIP的performance。 对于第一类优化任务的常见思路有3种。 优化训练架构,如 LiT 通过freezen image encoder,单独训练text encoder来进行text 和image的对齐来加速训练; 减少训练token,如 FLIP 通过引入视觉mask,通过只计算非mask区域的视觉表征来实现加速(MAE中的思路) 优化目标函数,如 CatLIP 将caption转为class label,用分类任务来代替对比学习任务来实现加速。 对于第二类提升CLIP的performance最常用和有效的手段就是数据治理,即构建高质量、大规模、高多样性的图文数据,典型的工作如:DFN。 SigLIP这篇paper 提出用sigmoid...
Large Model
2026-01-22

BLIP 论文名称 :BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (ICML 2022) 论文地址: https://arxiv.org/pdf/2201.12086.pdf 代码地址: https://github.com/salesforce/BLIP 官方解读博客: https://blog.salesforceairesearch.com/blip-bootstrapping-language-image-pretraining/ 背景和动机 视觉语言训练 (Vision-Language Pre-training, VLP) 最近在各种多模态下游任务上取得了巨大的成功。然而,现有方法有两个主要限制: 模型层面: 大多数现有的预训练模型仅在基于理解的任务或者基于生成的任务方面表现出色,很少有可以兼顾的模型。比如,基于编码器的模型,像 CLIP,ALBEF 不能直接转移到文本生成任务...
Large Model
2026-01-22

CLIP算法原理 CLIP 不预先定义图像和文本标签类别,直接利用从互联网爬取的 400 million 个image-text pair 进行图文匹配任务的训练,并将其成功迁移应用于30个现存的计算机视觉分类。简单的说,CLIP 无需利用 ImageNet 的数据和标签进行训练,就可以达到 ResNet50 在 ImageNet数据集上有监督训练的结果,所以叫做 Zero-shot。 CLIP(contrastive language-image pre-training)主要的贡献就是 利用无监督的文本信息,作为监督信号来学习视觉特征 。 CLIP 作者先是回顾了并总结了和上述相关的两条表征学习路线: 构建image和text的联系,比如利用已有的image-text pair数据集,从text中学习image的表征; 获取更多的数据(不要求高质量,也不要求full...