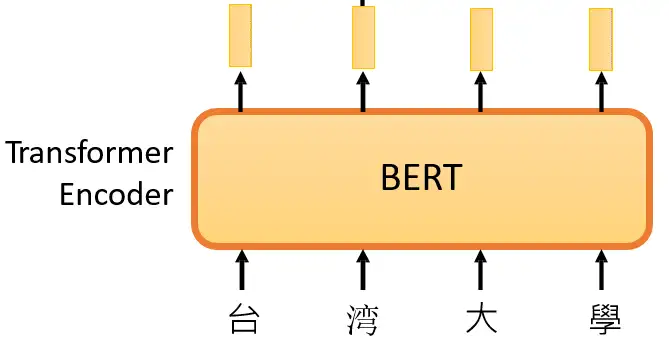
Computer Vision
2026-02-26
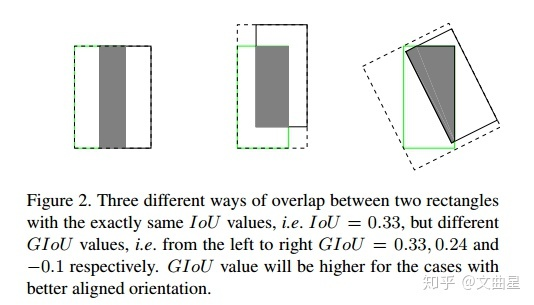
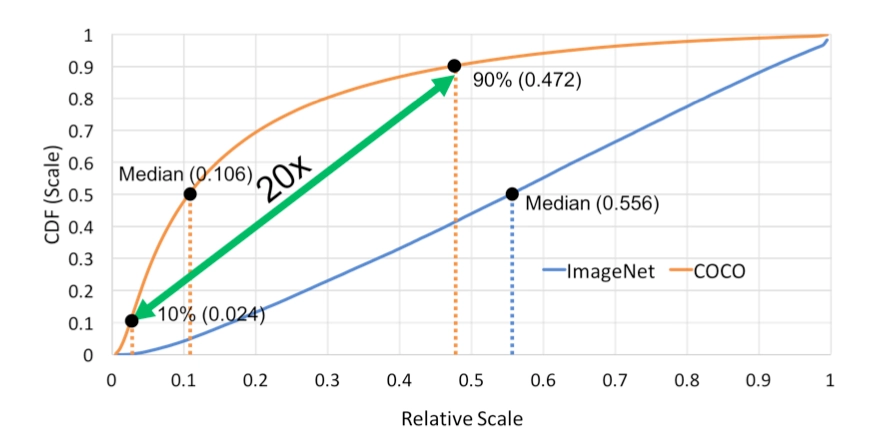
IOU(Intersection over Union) 特性(优点) IoU就是我们所说的 交并比 ,是目标检测中最常用的指标,在anchor-based的方法中,他的作用不仅用来确定正样本和负样本,还可以用来评价输出框(predict box)和ground-truth的距离。 \[IoU = \frac{|A \cap B|}{|A \cup B|}
\] 可以说 它可以反映预测检测框与真实检测框的检测效果。 还有一个很好的特性就是 尺度不变性 ,也就是对尺度不敏感(scale invariant), 在regression任务中,判断predict box和gt的距离最直接的指标就是IoU。 (满足非负性;同一性;对称性;三角不等性) import numpy as np
def Iou(box1, box2, wh=False):
if wh == False:
xmin1, ymin1, xmax1, ymax1 = box1
xmin2, ymin2, xmax2, ymax2 = box2
else:
xmin1, ymin1 =...