Search&Rec
2026-01-11
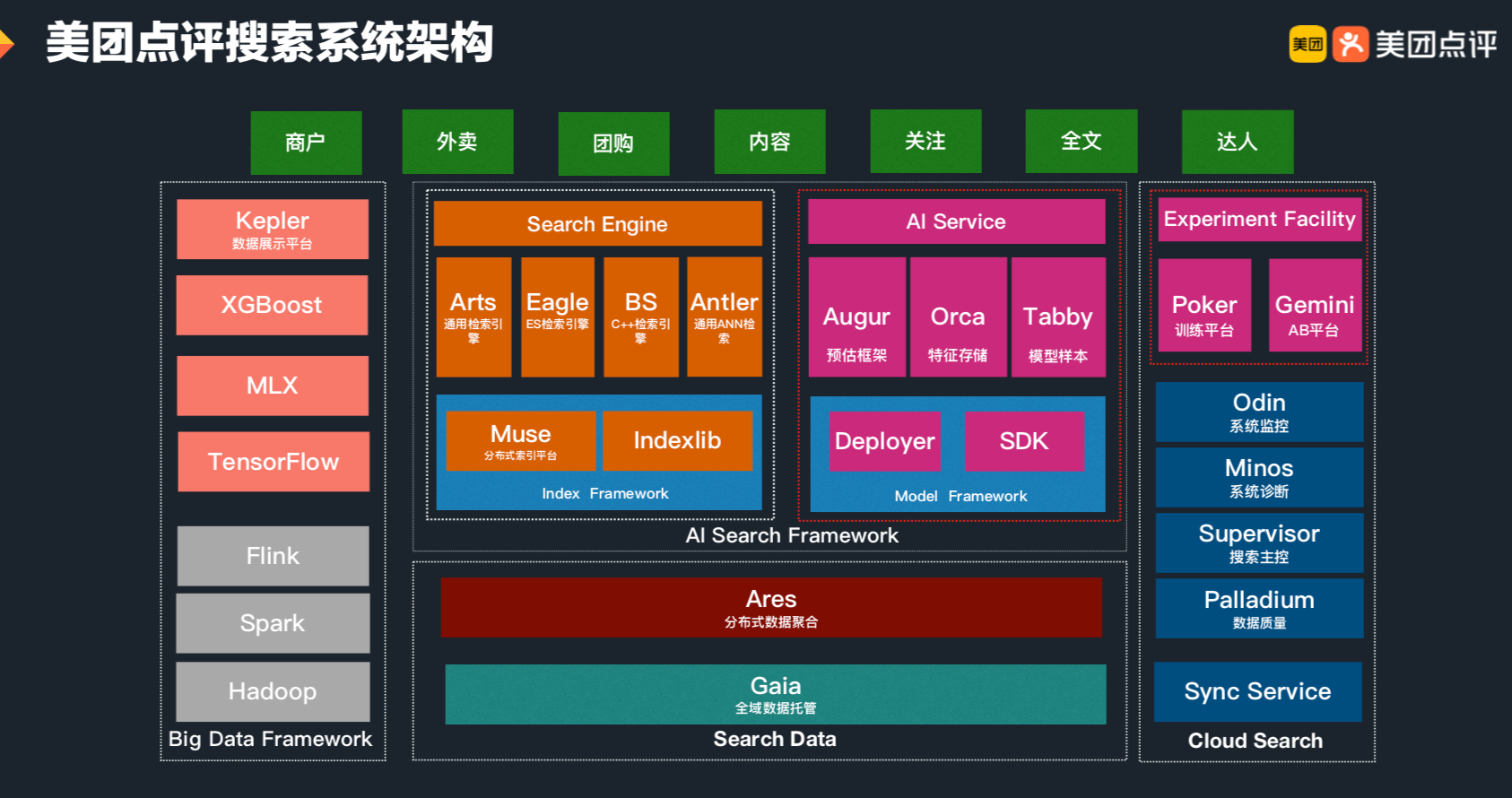
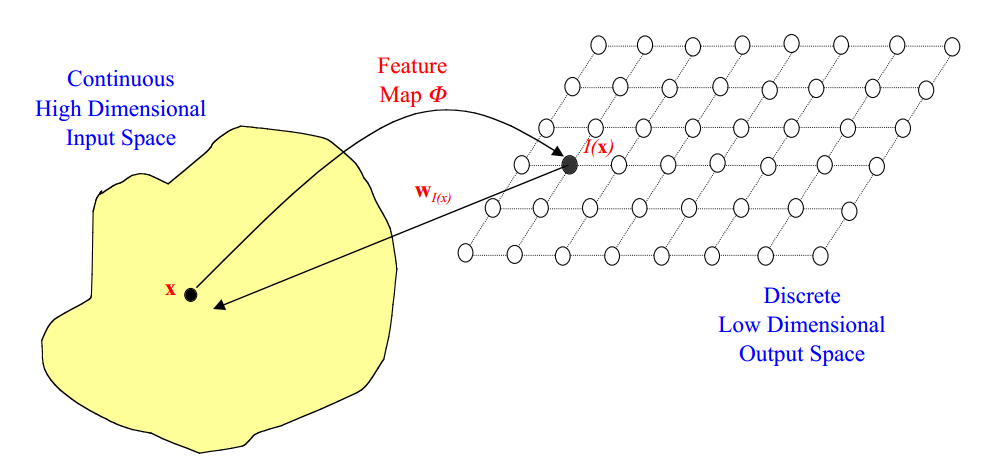
当前,美团搜索整体架构主要由搜索数据平台、在线检索框架及云搜平台、在线AI服务及实验平台三大体系构成。在AI服务及实验平台中,模型训练平台Poker和在线预估框架Augur是搜索AI化的核心组件,解决了模型从离线训练到在线服务的一系列系统问题,极大地提升了整个搜索策略迭代效率、在线模型预估的性能以及排序稳定性,并助力商户、外卖、内容等核心搜索场景业务指标的飞速提升。 首先,美团App内的一次完整的搜索行为主要涉的技术模块。如下图所示,从点击输入框到最终的结果展示,从热门推荐,到动态补全、最终的商户列表展示、推荐理由的展示等,每一个模块都要经过若干层的模型处理或者规则干预,才会将最适合用户(指标)的结果展示在大家的眼前。 为了保证良好的用户体验,技术团队对模型预估能力的要求变得越来越高,同时模...