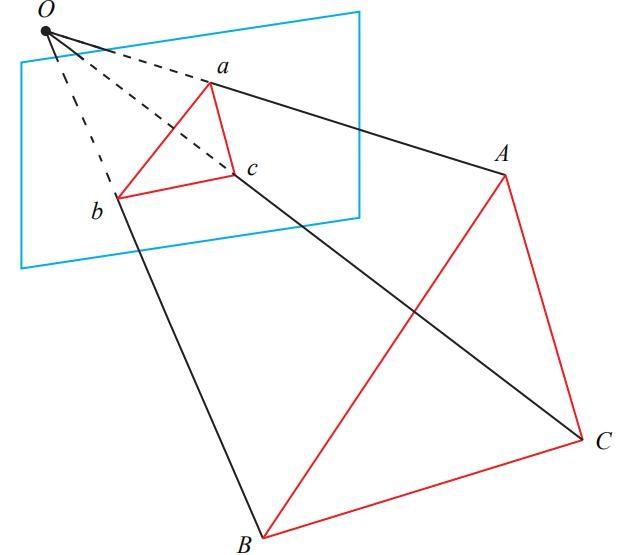
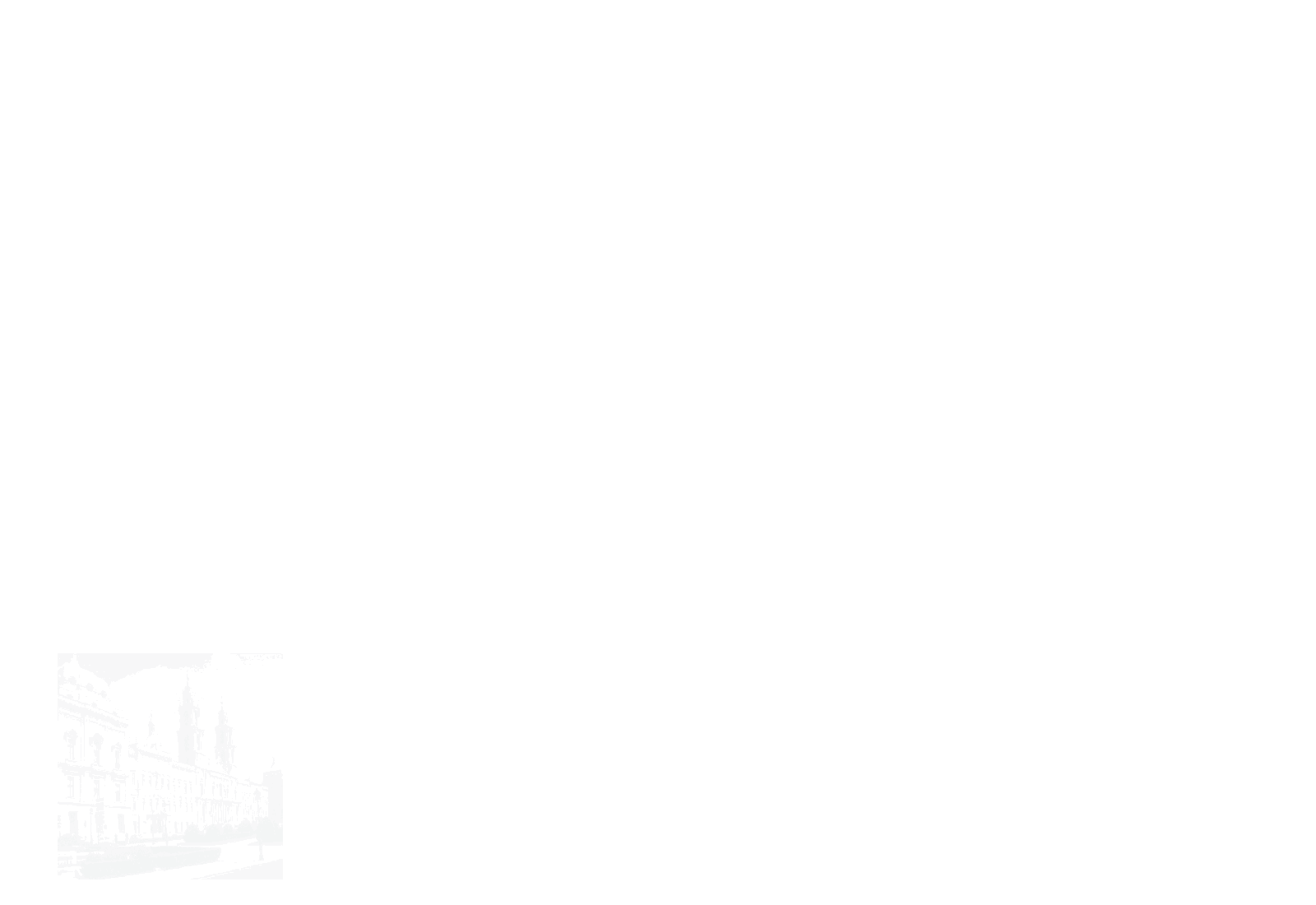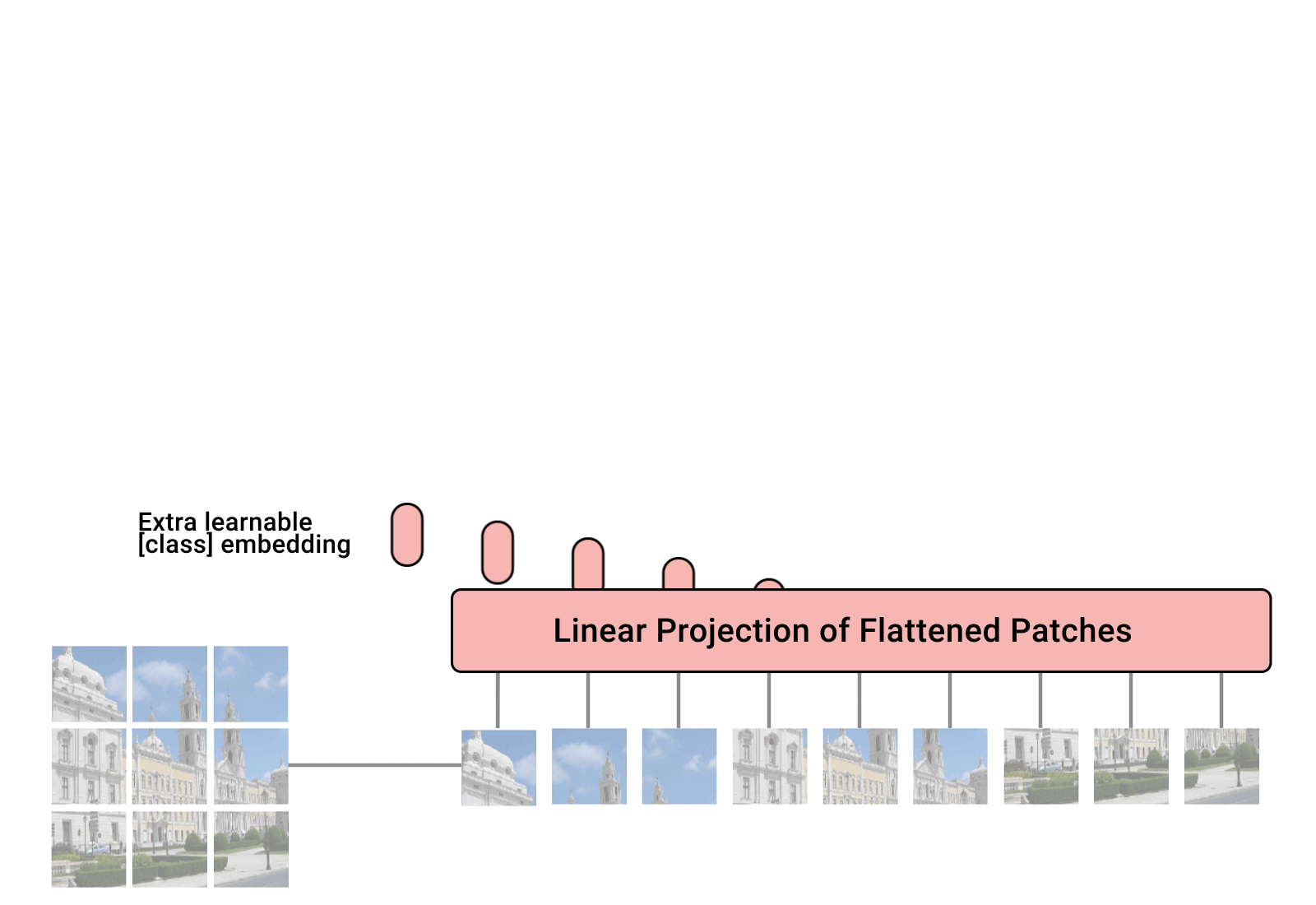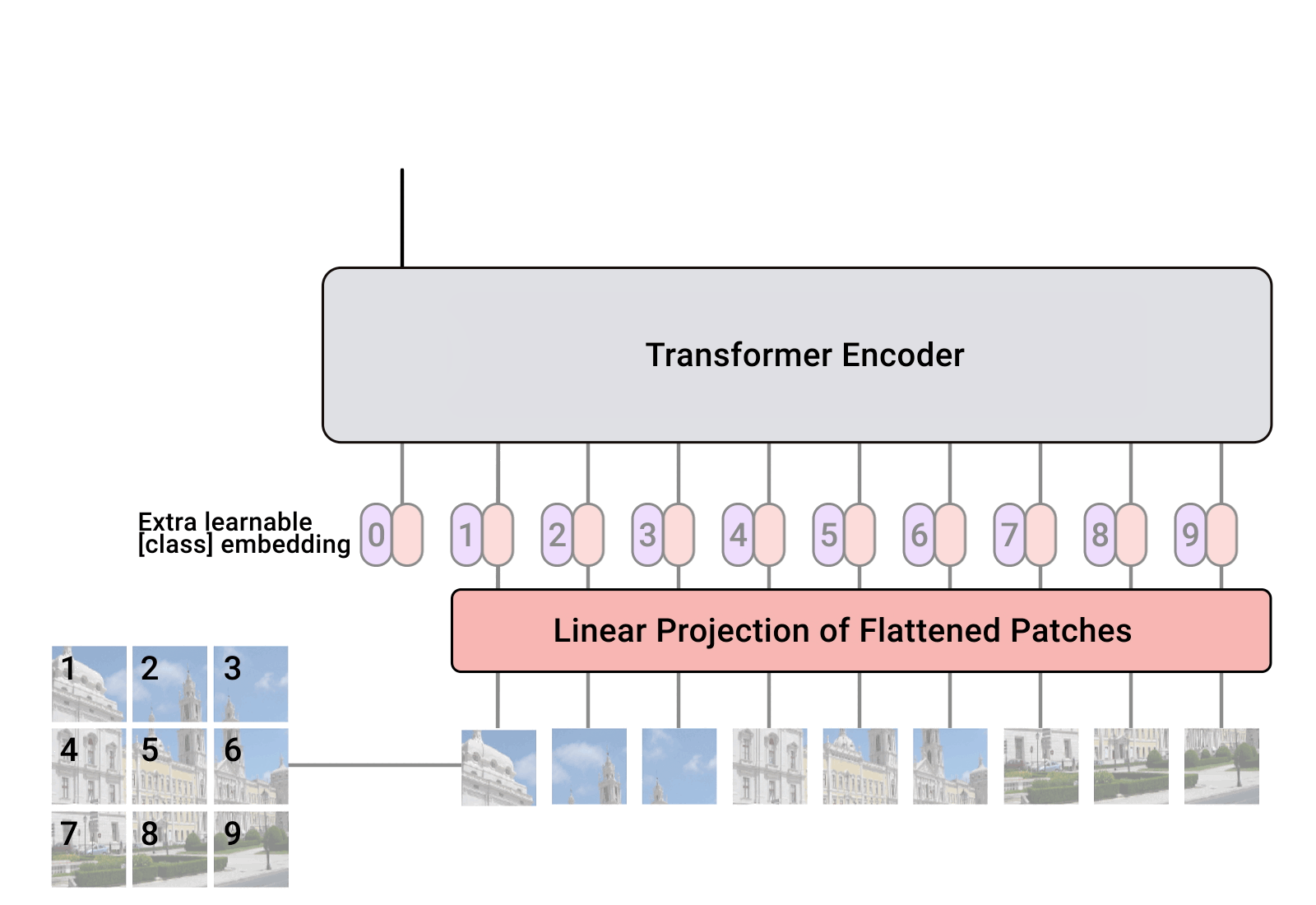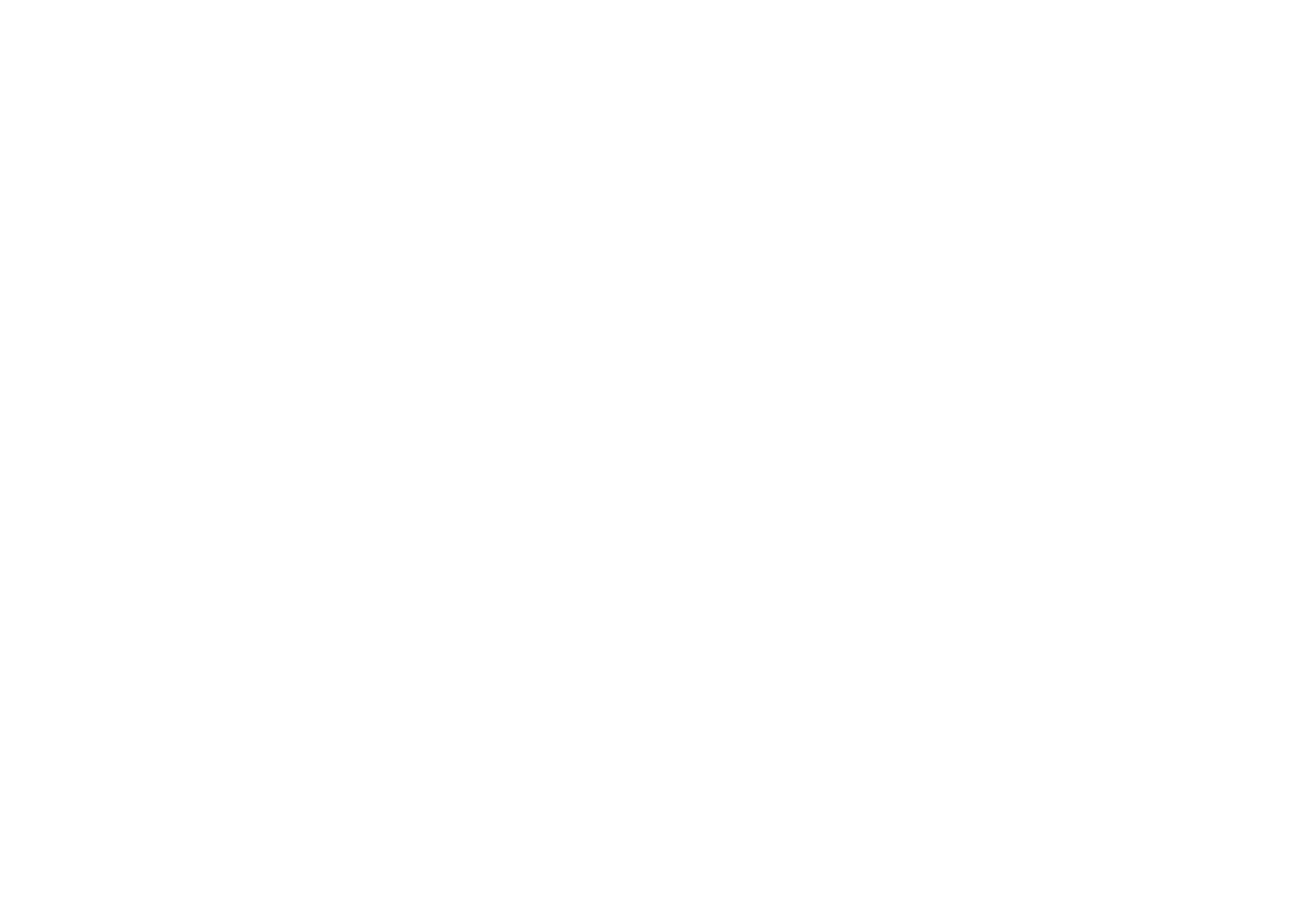3D Model
2026-01-30

本文主要介绍球谐(Spherical Harmonic,简称SH)函数在光照中的一些计算实现,其内容来自于GDC2003的演讲: Spherical Harmonic Lighting: The Gritty Details 学习总结 球谐函数是一组正交基函数,两两相乘的积分结果是0,而自身相乘的积分结果为1,任意信号都可以通过与球谐函数相乘积分算出其在对应球谐函数上的系数,这个过程可以看成是信号在球谐函数上的投影, 通过多个球谐函数按照对应系数累加可以得到原始信号的模拟,参与模拟的球谐函数阶数越高,模拟精度也就越高。 球面坐标系( \(\theta, \phi\) )下面的球谐函数可以表示任意点到球心的距离,而这个距离也可以解读成强度,从而可以用于实现某点处各个方向上的输入光强。 同时,每个点处的输入光强与输出光强的转换关系(BRDF之类)也可以使用球谐函数来表示,实际光照就是上述两个球谐函数相乘的积分输出 ,而在实际计算中,如果在离线的时候完成两个球谐函数的系数的求取,在运行时只需要一个系数向量点乘即可完成,大大简化了计算量,提升了计算速度。 背景简介 球谐光照(SH...