
Quick Start 一个最简单的DDP Pytorch例子! 环境准备 PyTorch(gpu)=1.5,python=3.6 推荐使用官方打好的PyTorch docker,避免乱七八糟的环境问题影响心情。 [代码] 代码 单GPU代码 [代码] 加入DDP的代码 [代码] DDP的基本原理 大白话原理 假如我们有N张显卡, 1. (缓解GIL限制)在DDP模式下,会有N个进程被启动,每个进程在一张卡上加载一个模型,这些模型的参数在数值上是相同的。 1. (RingReduce加速)在模型训练时,各个进程通过一种叫RingReduce的方法与其他进程通讯,交换各自的梯度,从而获得所有进程的梯度; 1. (实际上就是Data Parallelism)各个进程用平均后的梯度更新自己的参数,...
Python
2026-01-11
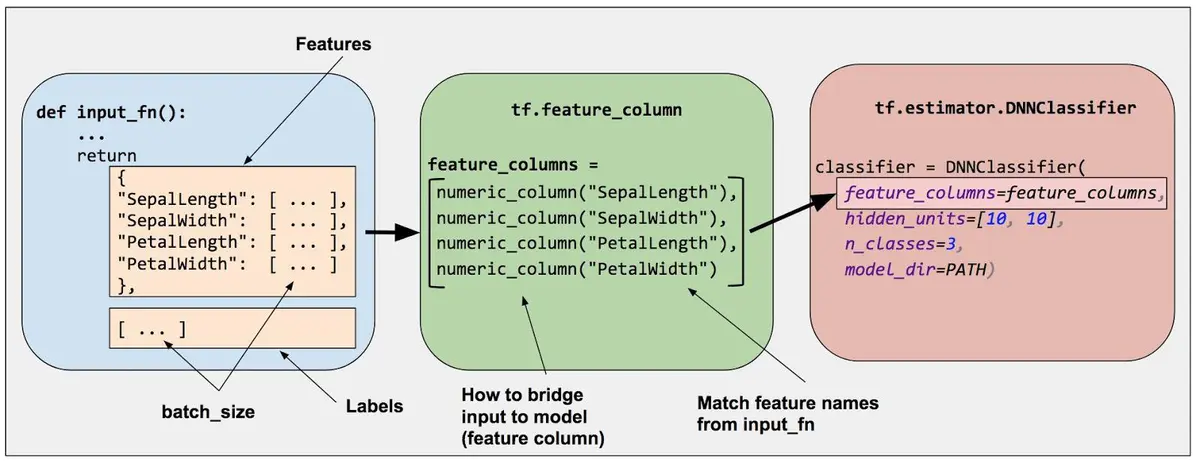
Overview 特征工程是机器学习流程中重要的一个环节,即使是通常用来做端到端学习的深度学习模型在训练之前也免不了要做一些特征工程相关的工作。Tensorflow平台提供的FeatureColumn API为特征工程提供了强大的支持。 Feature cloumns是原始数据和Estimator模型之间的桥梁,它们被用来把各种形式的原始数据转换为模型能够使用的格式。深度神经网络只能处理数值数据,网络中的每个神经元节点执行一些针对输入数据和网络权重的乘法和加法运算。然而,现实中的有很多非数值的类别数据,比如产品的品牌、类目等,这些数据如果不加转换,神经网络是无法处理的。另一方面,即使是数值数据,在仍给网络进行训练之前有时也需要做一些处理,比如标准化、离散化等。 在Tensorflow中,通过...
Python
2026-01-11
@tf_export为函数取了个名字! Tensorflow经常看到定义的函数前面加了@tf_export。例如,tensorflow/python/platform/app.py中有: [代码] 首先,@tf_export是一个修饰符。修饰符的本质是一个函数 tf_export的实现在tensorflow/python/util/tf_export.py中: [代码] 等号的右边的理解分两步: 1. functools.partial 1. api_export functools.partial是偏函数,它的本质简而言之是为函数固定某些参数。如:functools.partial(FuncA, p1)的作用是把函数FuncA的第一个参数固定为p1;又如functools.partial(...
Python
2026-01-11
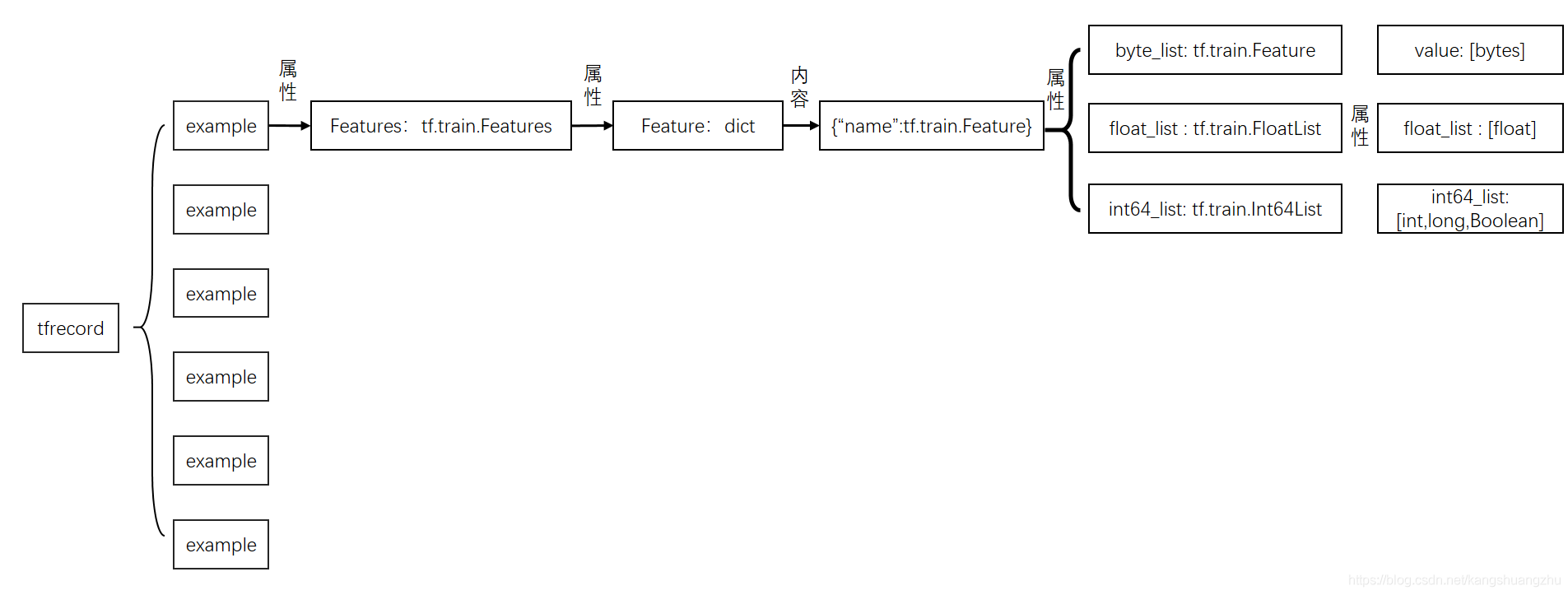
TFRecord TFRecord 是谷歌推荐的一种二进制文件格式,理论上它可以保存任何格式的信息。 tf.Example是一个Protobuffer定义的message,表达了一组string到bytes value的映射。TFRecord文件里面其实就是存储的序列化的tf.Example。关于Protobuffer参考Protobuf 终极教程。 example 我们可以具体到相关代码去详细地看下tf.Example的构成。作为一个Protobuffer message,它被定义在文件core/example/example.proto中: [代码] 只是包了一层Features的message。我们还需要进一步去查找Features的message定义: [代码] 到这里,我们可以看出...
PyTorch中,所有神经网络的核心是 autograd 包。 autograd 包为张量上的所有操作提供了自动求导机制。它是一个在运行时定义(definebyrun)的框架,这意味着反向传播是根据代码如何运行来决定的,并且每次迭代可以是不同的. 让我们用一些简单的例子来看看吧。 张量 torch.Tensor 是这个包的核心类。如果设置它的属性 .requires_grad 为 True,那么它将会追踪对于该张量的所有操作。当完成计算后可以通过调用 .backward(),来自动计算所有的梯度。这个张量的所有梯度将会自动累加到.grad属性. 要阻止一个张量被跟踪历史,可以调用 .detach() 方法将其与计算历史分离,并阻止它未来的计算记录被跟踪。 为了防止跟踪历史记录(和使用内存),...
Computer Vision
2026-01-11

原理分析 网络架构: 本文的任务是Object detection,用到的工具是Transformers,特点是Endtoend。 目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他...
Computer Vision
2026-01-11
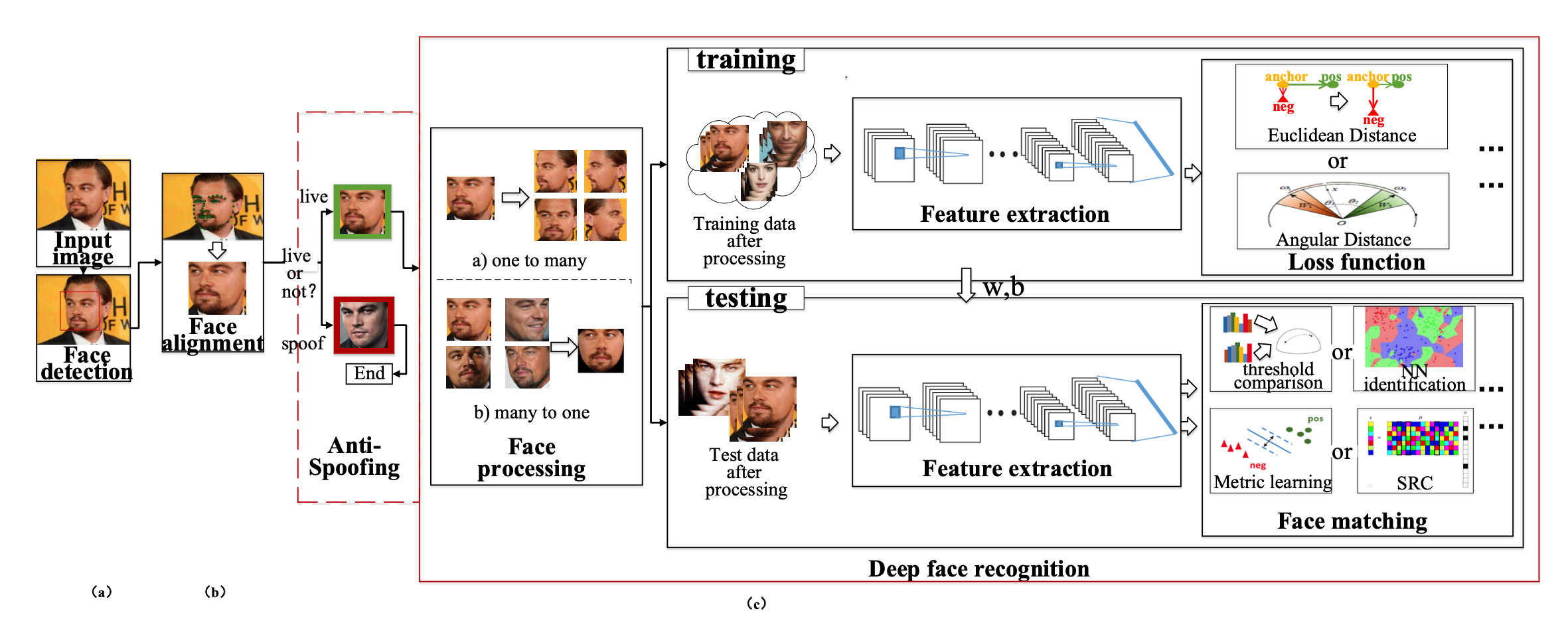
简介 一个完整的人脸识别系统包含以下几个模块 Face Detection: 人脸检测 Face Alignment:基于人脸关键点坐标对齐到正则坐标系下坐标 Face Recognition:基于对齐人脸进行识别 人脸识别的算法流程 人脸的识别流程:面部姿态处理(处理姿态,亮度,表情,遮挡),特征提取,人脸比对。 面部处理 face processing 这部分主要对姿态(主要)、亮度、表情、遮挡进行处理,可提升FR模型性能 主要包含两种处理方式: 1. "Onetomany Augmentation": 从单个图像生成不同姿态的图像,使模型学习到姿态不变性的表示 1. "Manytoone Normalization": 从多个不同姿态的图像中恢复人脸图像的标准视图 特征提取 Backb...
Python
2026-01-11

相同点 nn.Xxx和nn.functional.xxx的实际功能是相同的,即nn.Conv2d和nn.functional.conv2d 都是进行卷积,nn.Dropout 和nn.functional.dropout都是进行dropout,。。。。。; 运行效率也是近乎相同。 nn.functional.xxx是函数接口,而nn.Xxx是nn.functional.xxx的类封装,并且nn.Xxx都继承于一个共同祖先nn.Module。这一点导致nn.Xxx除了具有nn.functional.xxx功能之外,内部附带了nn.Module相关的属性和方法,例如train(), eval(),load_state_dict, state_dict 等。 不同点 两者的调用方式不同。 nn.X...

论文地址: 🔖 https://arxiv.org/pdf/2107.11291 代码地址: 前言 一般来说,我们可以把姿态估计任务分成两个流派:Heatmapbased和Regressionbased。 其主要区别在于监督信息的不同,Heatmapbased方法监督模型学习的是高斯概率分布图,即把GroundTruth中每个点渲染成一张高斯热图,最后网络输出为K张特征图对应K个关键点,然后通过argmax或softargmax来获取最大值点作为估计结果。这种方法由于需要渲染高斯热图,且由于热图中的最值点直接对应了结果,不可避免地需要维持一个相对高分辨率的热图(常见的是64x64,再小的话误差下界过大会造成严重的精度损失),因此也就自然而然导致了很大的计算量和内存开销。 Regression...
Computer Vision
2026-01-11

一、IOU(Intersection over Union) 1. 特性(优点) IoU就是我们所说的交并比,是目标检测中最常用的指标,在anchorbased的方法中,他的作用不仅用来确定正样本和负样本,还可以用来评价输出框(predict box)和groundtruth的距离。 1. 可以说它可以反映预测检测框与真实检测框的检测效果。 1. 还有一个很好的特性就是尺度不变性,也就是对尺度不敏感(scale invariant), 在regression任务中,判断predict box和gt的距离最直接的指标就是IoU。(满足非负性;同一性;对称性;三角不等性) [代码] 2. 作为损失函数会出现的问题(缺点) 1. 如果两个框没有相交,根据定义,IoU=0,不能反映两者的距离大小(重...
Computer Vision
2026-01-11

Introduction 目标检测中NMS需要依据候选检测目标的排序来进行筛选框,如果分类得分较低,但是定位框准确会导致在NMS中将该bbox框被排除掉,因此这个排序的可靠性就非常重要。之前的工作主要采用IOU分支(IOUNet)与Centerness得分(FCOS)来作为大量候选检测的排序依据。 然而,本文认为这些方法可以有效缓解分类得分和物体定位精度之间的不对齐问题。 但是,它们是次优解的,因为将两个不完善的预测相乘可能会导致排名依旧变差,作者经过试验表明,通过这种方法实现的性能上限非常有限。 此外,增加一个额外的网络分支来预测定位分数并不是一个很好的解决方案,并且会带来额外的计算负担。 基于上述分析,作者提出:不采用预测一个额外的定位精确度得分(IOUaware Centerness)...
Computer Vision
2026-01-11

💡 轻量级网络系列 Introduction Inception 在最初的版本 Inception/GoogleNet,其核心思想是利用多尺寸卷积核去观察输入数据。举个栗子,我们看某个景象由于远近不同,同一个物体的大小也会有所不同,那么不同尺度的卷积核观察的特征就会有这样的效果。于是就有了如下的网络结构图: 于是我们的网络就变胖了,通过增加网络的宽度,提高了对于不同尺度的适应程度。但这样的话,计算量有点大了。 Pointwise Conv 为了减少在上面结构的参数量并降低计算量,于是在 Inception V1 的基础版本上加上了 1x1 卷积核,这就形成了 Inception V1 的最终网络结构,如下图。 这个 1x1 卷积就是 Pointwise Convolution,简称 PW。利...