
1. 什么是NGram模型 NGram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。 每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。 该模型基于这样一种假设,第N个词的出现只与前面N1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的BiGram和三元的TriGram。 说完了ngram模型的概念之后,下面讲解ngram的一般应用。 2. NGram模型用于评估语句是否合理 如果...
NLP
2026-01-11
词向量,英文名叫Word Embedding,按照字面意思,应该是词嵌入。说到词向量,不少读者应该会立马想到Google出品的Word2Vec,大牌效应就是不一样。另外,用Keras之类的框架还有一个Embedding层,也说是将词ID映射为向量。由于先入为主的意识,大家可能就会将词向量跟Word2Vec等同起来,而反过来问“Embedding是哪种词向量?”这类问题,尤其是对于初学者来说,应该是很混淆的。事实上,哪怕对于老手,也不一定能够很好地说清楚。 这一切,还得从one hot说起... 五十步笑百步 one hot,中文可以翻译为“独热”,是最原始的用来表示字、词的方式。为了简单,本文以字为例,词也是类似的。假如词表中有“科、学、空、间、不、错”六个字,one hot就是给这六个字分...
Search&Rec
2026-01-11
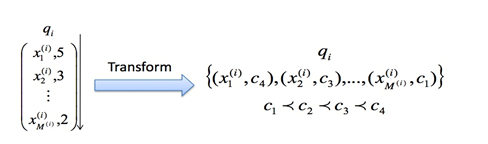
Learning to rank 排序学习是推荐、搜索、广告的核心方法。排序结果的好坏很大程度影响用户体验、广告收入等。排序学习可以理解为机器学习中用户排序的方法,这里首先推荐一本微软亚洲研究院刘铁岩老师关于LTR的著作,Learning to Rank for Information Retrieval,书中对排序学习的各种方法做了很好的阐述和总结。我这里是一个超级精简版。 排序学习是一个有监督的机器学习过程,对每一个给定的查询-文档对,抽取特征,通过日志挖掘或者人工标注的方法获得真实数据标注。然后通过排序模型,使得输入能够和实际的数据相似。常用的排序学习分为三种类型:PointWise,PairWise和ListWise。 PointWise 单文档方法的处理对象是单独的一篇文档,将文档...