Computer Vision
2026-01-11
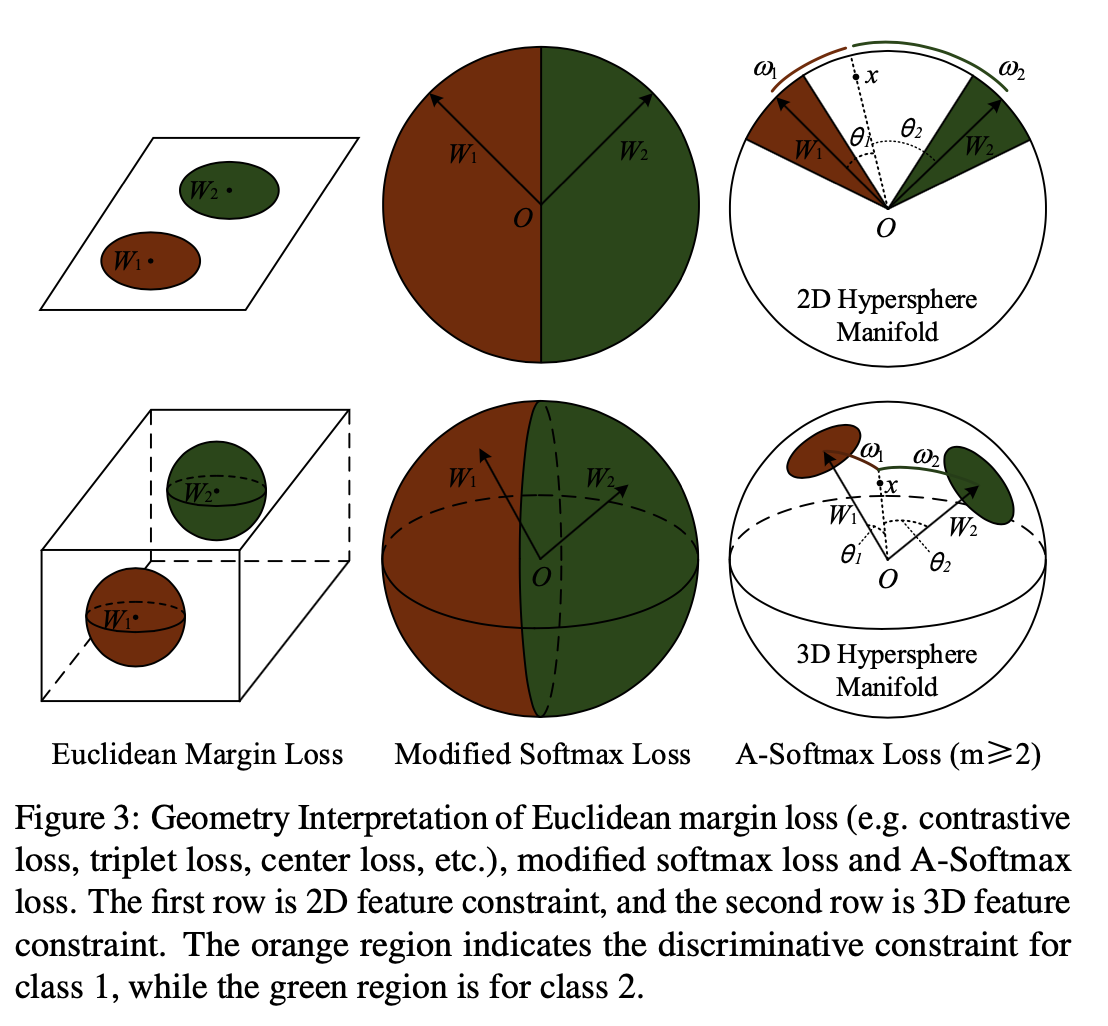
推导 回顾一下二分类下的Softmax后验概率,即: [公式] 显然决策的分界在当 𝑝_1=𝑝_2 时,所以决策界面是 (𝑊_1−𝑊_2)𝑥+𝑏_1−𝑏_2=0 。我们可以将 𝑊^𝑇_𝑖𝑥+𝑏_𝑖 写成 ‖W_i^T‖⋅‖x‖cos(θ_i)+b_i ,其中 θ_i 是 W_i 与 x 的夹角,如对 W_i 归一化且设偏置 b_i 为零( ‖W_i‖=1 , b_i=0 ),那么当 p_1=p_2 时,我们有 cos(θ_1)−cos(θ_2)=0 。从这里可以看到,如里一个输入的数据特征 x_i 属于 𝑦_𝑖 类,那么 θ_{y_i} 应该比其它所有类的角度都要小,也就是说在向量空间中 W_{y_i} 要更靠近 x_i 。 我们用的是Softmax Loss,对于输入 x_i ,So...