二叉树结构 [代码] 递归 时间复杂度:O(n),n为节点数,访问每个节点恰好一次。 空间复杂度:空间复杂度:O(h),h为树的高度。最坏情况下需要空间O(n),平均情况为O(logn) 递归1: 二叉树遍历最易理解和实现版本 [代码] 递归2: 通用模板 可以适应不同的题目,添加参数、增加返回条件、修改进入递归条件、自定义返回值 [代码] 迭代 时间复杂度:O(n),n为节点数,访问每个节点恰好一次。 空间复杂度:O(h),h为树的高度。取决于树的结构,最坏情况存储整棵树,即O(n) 迭代1: 前序遍历最常用模板(后序同样可以用) [代码] 迭代2: 前、中、后序遍历通用模板(只需一个栈的空间) [代码] 迭代3:标记法迭代(需要双倍的空间来存储访问状态) 前、中、后、层序通用模板,只需改...
背包问题
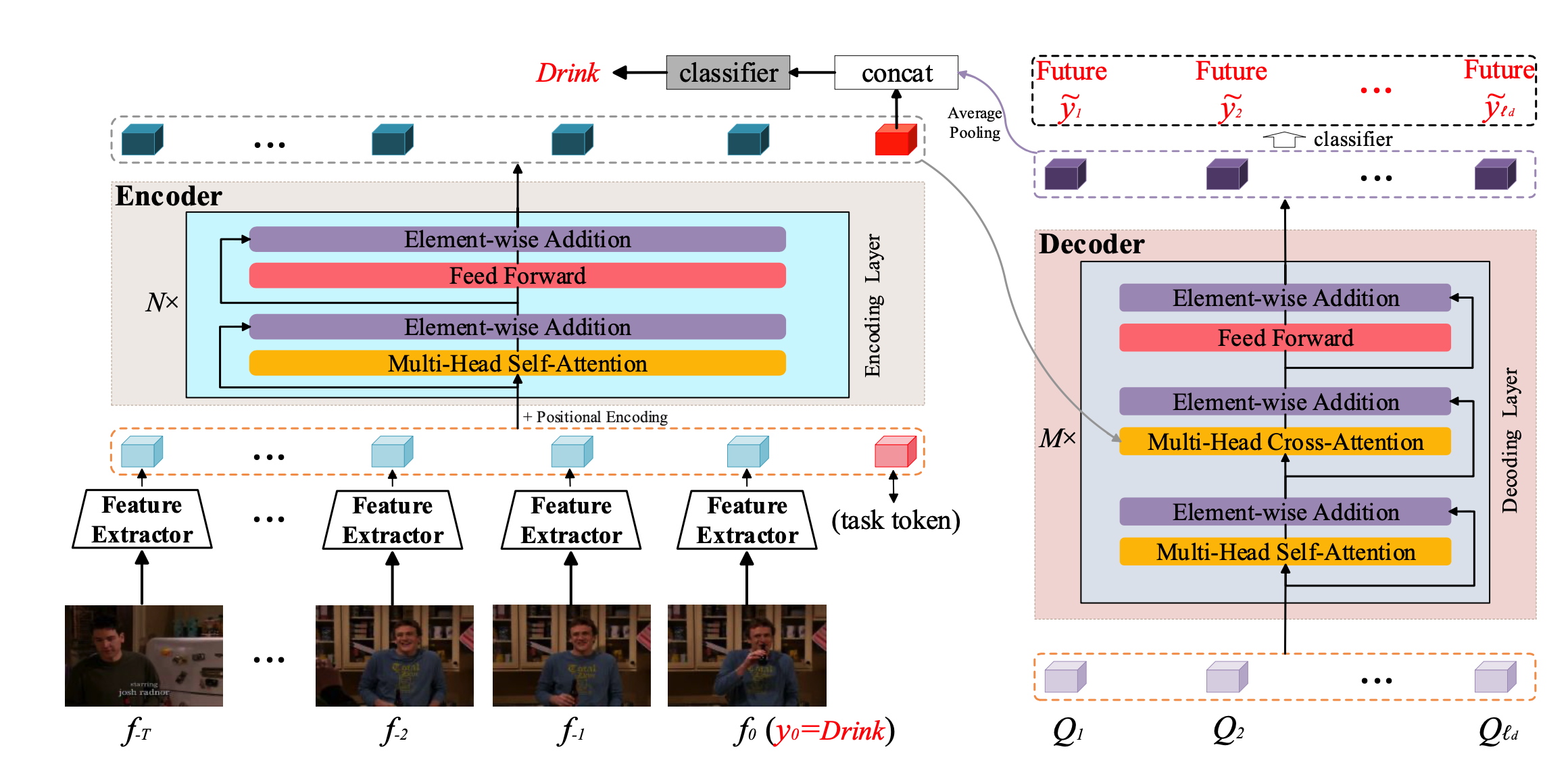
简介 之前的很多方法都是用RNN的结构去构建时序上的依赖关系,但是RNN的结构的缺点是不能并行操作,且存在梯度消失的现象。所以本文就是将之前的RNN的结构改为Transfomer的形式。延续了之前TRN的整个网络的框架,也是结合了对未来帧的预测与历史帧的表示相结合来对当前的动作进行预测。 方法 整个网络框架如上图所示, Encoder就是利用transfomer对longrange的历史和目前帧进行特征表示,其中要说明的一个点就是,这里的特征空间包含T个历史特征,当前窗口的特征以及一个task token,这个task token的作用可以从下图看出来 这幅图对比的是输入进classifier的特征与网络输入的特征的相似性,可以看出w/o task token 对应的是当前t=0时刻的特征,...
Algorithm
2026-01-11

题目 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。” 示例 1: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 输出:3 解释:节点 5 和节点 1 的最近公共祖先是节点 3 。 示例 2: 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 输出:5 解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。 示例 3: 输入:root...
Algorithm
2026-01-11
题目 Given two sorted integer arrays nums1 and nums2, merge nums2 into nums1 as one sorted array. Note: The number of elements initialized in nums1 and nums2 are m and n respectively. You may assume that nums1 has enough space (size that is equal to m + n) to hold additional elements from nums2. Example: [代码] Constraints: 10^9 <= nums1[i], nums2[i] <...
Large Model
2026-01-11

梯度检查点(Gradient Checkpointing) 大模型的参数量巨大,即使将batch_size设置为1并使用梯度累积的方式更新,也仍然会OOM。原因是通常在计算梯度时,我们需要将所有前向传播时的激活值保存下来,这消耗大量显存。 还有另外一种延迟计算的思路,丢掉前向传播时的激活值,在计算梯度时需要哪部分的激活值就重新计算哪部分的激活值,这样做倒是解决了显存不足的问题,但加大了计算量同时也拖慢了训练。 梯度检查点(Gradient Checkpointing)在上述两种方式之间取了一个平衡,这种方法采用了一种策略选择了计算图上的一部分激活值保存下来,其余部分丢弃,这样被丢弃的那一部分激活值需要在计算梯度时重新计算。 下面这个动图展示了一种简单策略:前向传播过程中计算节点的激活值并保存...
Large Model
2026-01-11
简介 基于lmmsengine中的训练时对数据packing操作以及use_rmpad消除了所有padding计算的逻辑 Packing 总体逻辑基于packing_length 将不同的数据填充到一个sequence中,具体来说 在Datsset中, 如下代码所示,将不同的数据append到buffer列表中 [代码] 在 Collator 组合成batch的形式传入到模型的输入, 这里还是将数据padding [代码] rmpad 项目中,是以 monkey patch的形式(也就是打热补丁) 替换rmpad操作的,如下代码所示,主要就是替换模型中的forward操作 [代码] Qwen3VLModel.forward 显式调用了 _unpad_input。它计算了非 padding 元...
DFS
NLP
2026-01-11

取代RNN——Transformer 在介绍Transformer前我们来回顾一下RNN的结构 对RNN有一定了解的话,一定会知道,RNN有两个很明显的问题 效率问题:需要逐个词进行处理,后一个词要等到前一个词的隐状态输出以后才能开始处理 如果传递距离过长还会有梯度消失、梯度爆炸和遗忘问题 为了缓解传递间的梯度和遗忘问题,设计了各种各样的RNN cell,最著名的两个就是LSTM和GRU了 LSTM (Long Short Term Memory) GRU (Gated Recurrent Unit) 但是,引用网上一个博主的比喻,这么做就像是在给马车换车轮,为什么不直接换成汽车呢? 于是就有了Transformer。Transformer 是Google Brain 2017的提出的一篇工...
Generative Model
2026-01-11

SD模型原理 SD是CompVis、Stability AI和LAION等公司研发的一个文生图模型,它的模型和代码是开源的,而且训练数据LAION5B也是开源的。SD在开源90天github仓库就收获了33K的stars,可见这个模型是多受欢迎。 SD是一个基于latent的扩散模型,它在UNet中引入text condition来实现基于文本生成图像。SD的核心来源于Latent Diffusion这个工作,常规的扩散模型是基于pixel的生成模型,而Latent Diffusion是基于latent的生成模型,它先采用一个autoencoder将图像压缩到latent空间,然后用扩散模型来生成图像的latents,最后送入autoencoder的decoder模块就可以得到生成的图像。 ...
Large Model
2026-01-11

引言与背景 FlashAttention的关键创新在于使用类似于在线Softmax的思想来对自注意力计算进行分块(tiling),从而能够融合整个多头注意力层的计算,而无需访问GPU全局内存来存储中间的logits和注意力分数 在深度学习中,Transformer模型的自注意力机制是计算密集型操作。传统实现需要在GPU全局内存中存储大量中间结果,这导致: 内存瓶颈:中间矩阵占用大量显存 I/O开销:频繁的全局内存访问降低效率 扩展性限制:难以处理超长序列 FlashAttention通过算法创新解决了这些问题。 SelfAtention 自注意力机制的计算可以总结为(为简化说明,忽略头数和批次维度,也省略注意力掩码和缩放因子 [Math] ): [公式] 其中: Q, K, V, O 都是形...