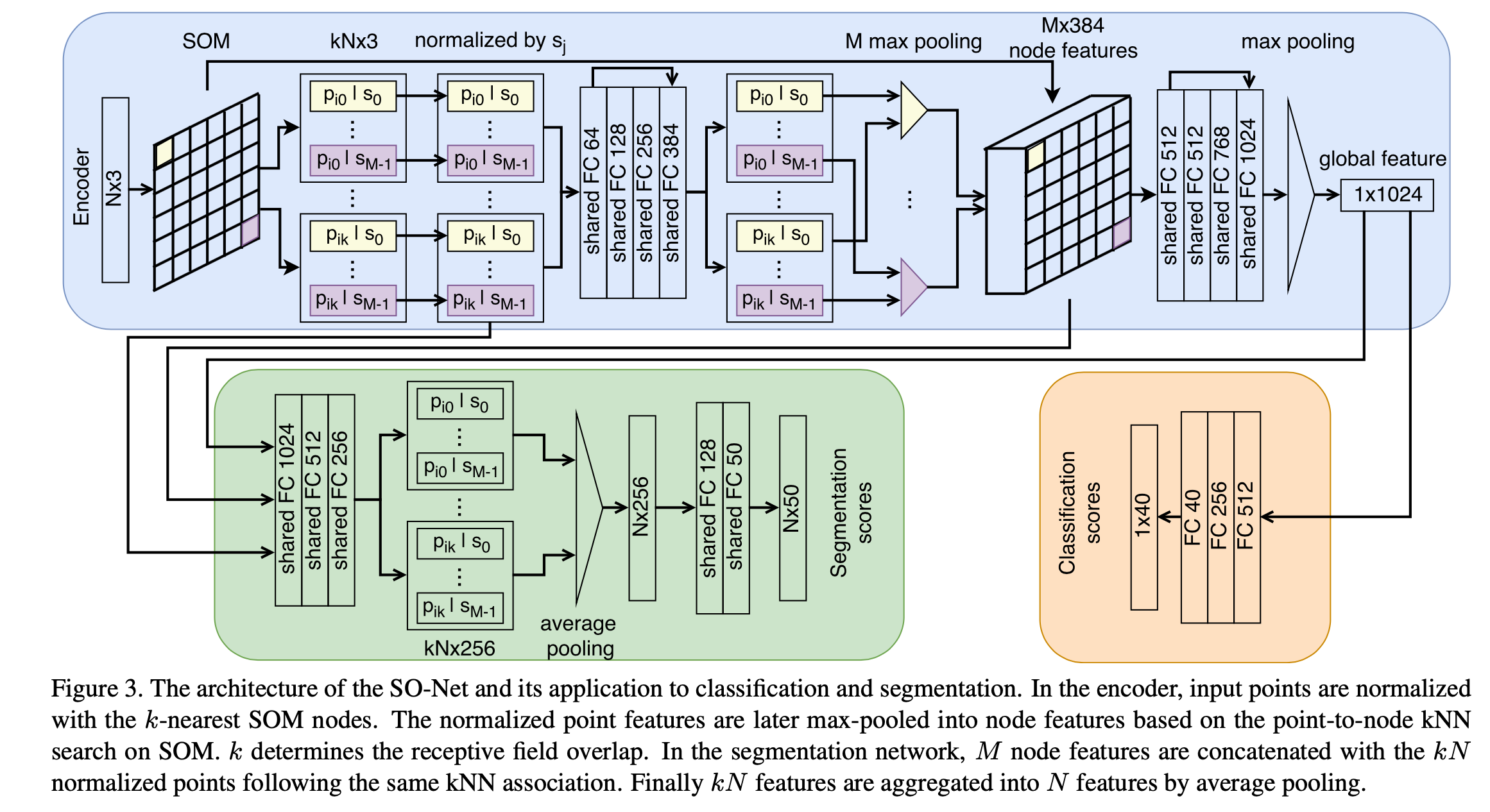
概括 针对一些网络在处理point cloud时的缺点,如:不能对点的空间分布进行建模(例如PointNet++,只是能获取局部信息不能得到局部区域之间的空间关系),提出了SONet。SO的含义是利用Selforganizing map的Net。 结果:它具有能够对点的空间分布进行建模、层次化特征提取、可调节的感受野范围的优点,并能够用于多种任务如重建、分类、分割等等。取得了相似或超过SOTA的性能,因为可并行化和架构简单使得训练速度很快。 贡献: TODO IDEA:作者发现将CNN直接用于SOM图上性能不升反降,为什么(推测:可能是SOM的2D map并不是保持了原本的空间对应关系,可能nodes之间是乱序的,导致用conv2d时精度反而降低)? 难点 如何对local regions之...
3D Model
2026-01-11
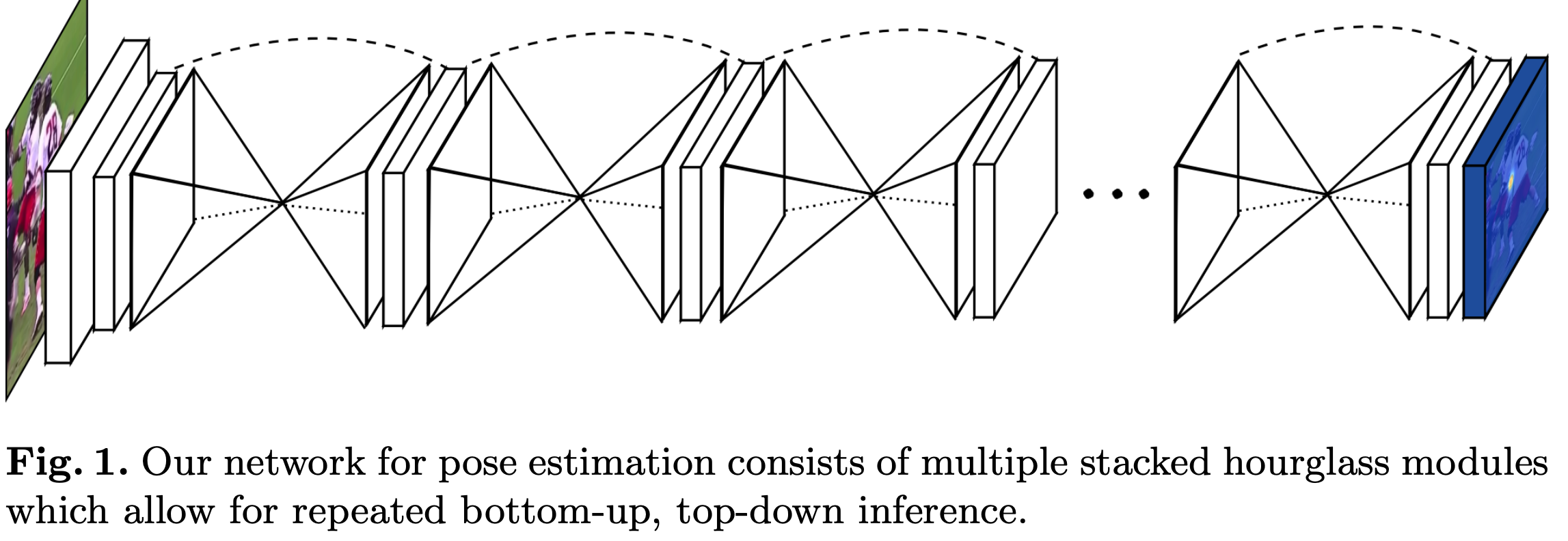
论文介绍了一种新的网络结构用于人体姿态检测,作者在论文中展现了不断重复bottomup、topdown过程以及运用intermediate supervison(中间监督)对于网络性能的提升,下面来介绍Stacked Hourglass Networks. 简介 理解人类的姿态对于一些高级的任务比如行为识别来说特别重要,而且也是一些人机交互任务的基础。作者提出了一种新的网络结构Stacked Hourglass Networks来对人体的姿态进行识别,这个网络结构能够捕获并整合图像所有尺度的信息。之所以称这种网络为Stacked Hourglass Networks,主要是它长得很像堆叠起来的沙漏,如下图所示: 这种堆叠在一起的Hourglass模块结构是对称的,bottomup过程将图片从...
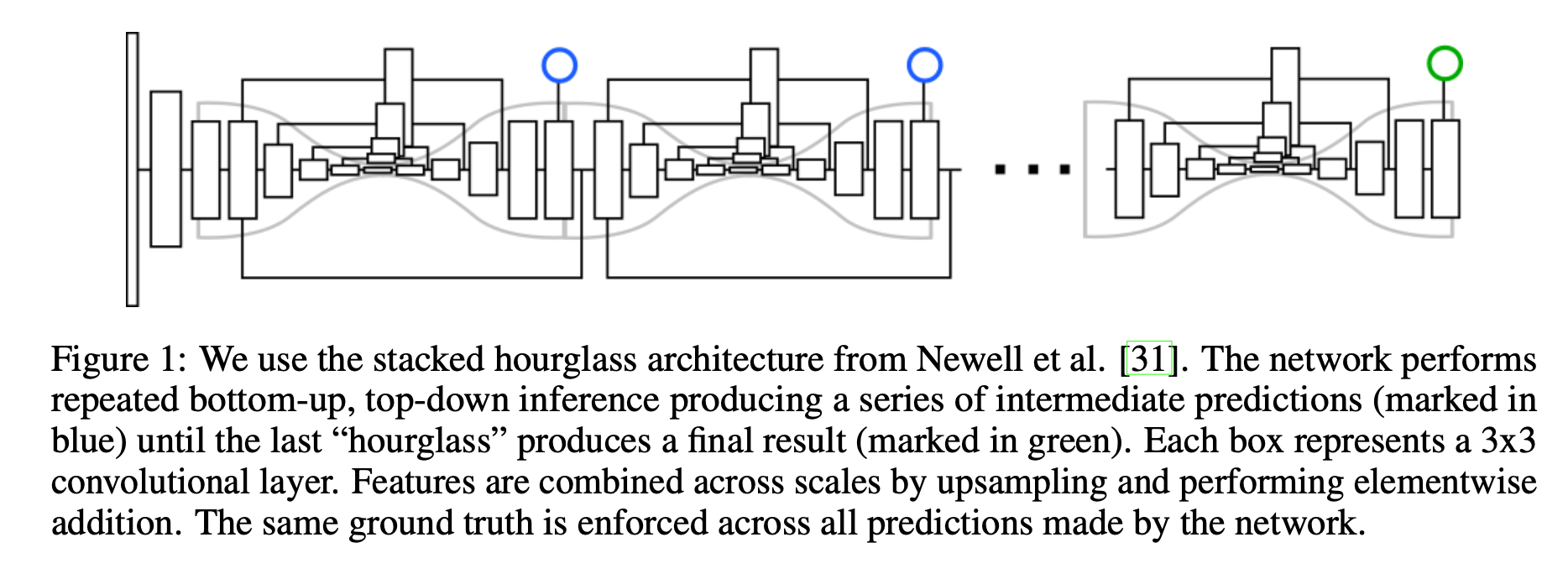
简介 作者认为许多计算机视觉的任务可以看作是检测和分组问题检测一些小的单元,然后将它们组合成更大的单元,例如,多人目标检测可以通过检测人的关节点然后再将它们进行分组(属于同一个人的关节点为一组)解决;实例分割问题可以看作是检测一些相关的像素然后将它们组合成一个目标实例。 Associative Embedding是一种表示关节检测和分组任务的输出的新方法,其基本思想是为每次检测引入一个实数,用作识别对象所属组的“tag”,换句话说,标签将每个检测与同一组中的其他检测相关联。作者使用一个损失函数使得如果相应的检测属于ground truth中的相同组则促使这一对标签具有相似的值。需要注意的是,这里标签具体的值并不重要,重要的是不同标签之间的差异。 这篇其实是源自Stacked Hourglas...
3D Model
2026-01-11

整体流程: [代码] 0. 数据预处理 这个步骤主要是crop四路数据,及生成后续步骤所需要的yaml文件。 1. 四路相机与双路相机标定 内参标定 [代码] 这里主要的函数就是: pts = cv2.findChessboardCorners(img, (board_width, board_height))[1] cv2.cornerSubPix(gray, pts, (12, 12), (1, 1), (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_COUNT, 30, 0.1)) det, intr, dist, _, _ = cv2.calibrateCamera(obj_pts, img_pts, self.imgSize, None, No...
Large Model
2026-01-11

梯度检查点(Gradient Checkpointing) 大模型的参数量巨大,即使将batch_size设置为1并使用梯度累积的方式更新,也仍然会OOM。原因是通常在计算梯度时,我们需要将所有前向传播时的激活值保存下来,这消耗大量显存。 还有另外一种延迟计算的思路,丢掉前向传播时的激活值,在计算梯度时需要哪部分的激活值就重新计算哪部分的激活值,这样做倒是解决了显存不足的问题,但加大了计算量同时也拖慢了训练。 梯度检查点(Gradient Checkpointing)在上述两种方式之间取了一个平衡,这种方法采用了一种策略选择了计算图上的一部分激活值保存下来,其余部分丢弃,这样被丢弃的那一部分激活值需要在计算梯度时重新计算。 下面这个动图展示了一种简单策略:前向传播过程中计算节点的激活值并保存...
Deep Learning
2026-01-11

最近,似乎现在每个大型语言模型(LLM)和新闻中提到的复杂神经网络架构都使用略有不同的激活函数,而就在几年前,最常见的做法只是在神经网络的内部层中使用 ReLU。 曾经优秀的 ReLUs 怎么了,以及是什么促使最新的大型语言模型(LLMs)的创造者们开始使用不同的(更高级的)激活函数? Threshold activation (Perceptron) 1957 年,罗森布拉特建造了“感知机” 最古老的激活函数是基本感知器。它由芝加哥大学精神病学系的爱德华·麦克洛奇和沃尔特·皮茨构思,后来由弗兰克·罗森布拉特在 1957 年于康奈尔航空实验室为美国海军在硬件上更著名地实现了。该算法非常简单,其基本规则是:如果某个值超过某个阈值,则返回 1,否则返回 0。有些变体会返回 1 或1。 由于其二元...
Large Model
2026-01-11
简介 基于lmmsengine中的训练时对数据packing操作以及use_rmpad消除了所有padding计算的逻辑 Packing 总体逻辑基于packing_length 将不同的数据填充到一个sequence中,具体来说 在Datsset中, 如下代码所示,将不同的数据append到buffer列表中 [代码] 在 Collator 组合成batch的形式传入到模型的输入, 这里还是将数据padding [代码] rmpad 项目中,是以 monkey patch的形式(也就是打热补丁) 替换rmpad操作的,如下代码所示,主要就是替换模型中的forward操作 [代码] Qwen3VLModel.forward 显式调用了 _unpad_input。它计算了非 padding 元...
Deep Learning
2026-01-11

引言与背景 随机逼近(Stochastic Approximation)是一类用于求解寻根或优化问题的随机迭代算法,其特点是不需要知道目标函数或其导数的表达式。 随机逼近的核心优势在于: 能够处理带有随机噪声的观测数据 不需要目标函数的解析表达式 可以在线学习,每获得一个新样本就更新估计值 均值估计问题 考虑一个随机变量 X ,其取值来自有限集合 [Math] 。我们的目标是估计 E[X] 。假设我们有一个独立同分布的样本序列 \{x_i\}_{i=1}^n ,那么 X 的期望值可以近似为: [公式] 非增量方法与增量方法 非增量方法:先收集所有样本,然后计算平均值。缺点是如果样本数量很大,可能需要等待很长时间。 增量方法:定义 [公式] 可以推导出递归公式: [公式] 这个算法可以增量式地...
Large Model
2026-01-11

引言与背景 FlashAttention的关键创新在于使用类似于在线Softmax的思想来对自注意力计算进行分块(tiling),从而能够融合整个多头注意力层的计算,而无需访问GPU全局内存来存储中间的logits和注意力分数 在深度学习中,Transformer模型的自注意力机制是计算密集型操作。传统实现需要在GPU全局内存中存储大量中间结果,这导致: 内存瓶颈:中间矩阵占用大量显存 I/O开销:频繁的全局内存访问降低效率 扩展性限制:难以处理超长序列 FlashAttention通过算法创新解决了这些问题。 SelfAtention 自注意力机制的计算可以总结为(为简化说明,忽略头数和批次维度,也省略注意力掩码和缩放因子 [Math] ): [公式] 其中: Q, K, V, O 都是形...
Deep Learning
2026-01-11

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 1、Upsampling(上采样)[没有学习过程] 在FCN、Unet等网络结构中,涉及到了上采样。上采样概念:上采样指的是任何可以让图像变成更高分辨率的技术。最简单的方式是重采样和插值:将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在torch.nn中的Vision Layers里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d 0)PixelShuffl...
Large Model
2026-01-11

模型概述 KimiVL 是一个高效的开源混合专家视觉语言模型(VLM),它提供先进的多模态推理、长上下文理解和强大的代理能力,同时在语言解码器中仅激活 2.8B 参数(KimiVLA3B)。该模型在多种挑战性任务中表现出色,包括一般用途的视觉语言理解、多轮代理任务、大学水平的图像和视频理解、OCR、数学推理和多图像理解等. 模型架构 KimiVL 的架构由三个主要部分组成: MoE语言模型 Moonlight MoE language model with only 2.8B activated (16B total) parameters 视觉模型 400M nativeresolution MoonViT vision encoder. MLP Projector MoonViT: 原生...
Large Model
2026-01-11

背景:大模型 vs. GPU Memory 大模型最大的特点是模型参数多,训练时需要很大的GPU显存。举个例子,帮助大家的理解:对于一个常见的7B规模参数的大模型(如LLaMA-2 7B),基于16-bit混合精度训练时,在仅考虑模型参数、梯度、优化器情况下,显存占用就有112GB,显然目前A100、H100这样主流的显卡单张是放不下的,更别提国内中小厂喜欢用的A6000/5000、甚至消费级显卡。 上面的例子中,参数占GPU 显存近 14GB(每个参数2字节)。再考虑到训练时 梯度的存储占14GB(每个参数对应一个梯度,也是2字节)、优化器Optimizer假设是用目前主流的AdamW则是8...