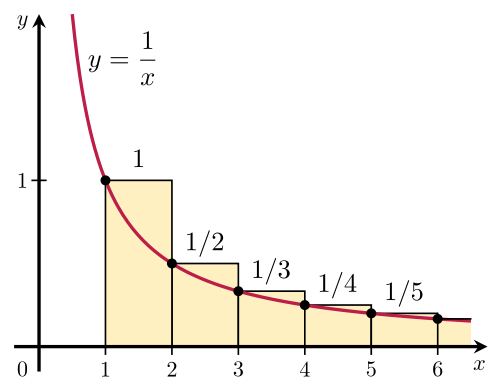
调和级数记住下面的公式就够了: [Formula] 证明方法就是下面这张图

一、泊松分布 日常生活中,大量事件是有固定频率的。 某医院平均每小时出生3个婴儿 某公司平均每10分钟接到1个电话 某超市平均每天销售4包xx牌奶粉 某网站平均每分钟有2次访问 它们的特点就是,我们可以预估这些事件的总数,但是没法知道具体的发生时间。已知平均每小时出生3个婴儿,请问下一个小时,会出生几个? 有可能一下子出生6个,也有可能一个都不出生。这是我们没法知道的。 泊松分布就是描述某段时间内,事件具体的发生概率。 [Formula] 上面就是泊松分布的公式。等号的左边, P 表示概率, N 表示某种函数关系, t 表示时间, n 表示数量,1小时内出生3个婴儿的概率,就表示为 P(N(1...
Computer Vision
2026-01-11
mAP定义及相关概念 mAP: mean Average Precision, 即各类别AP的平均值 AP: PR曲线下面积,后文会详细讲解 PR曲线: PrecisionRecall曲线 Precision: TP / (TP + FP) Recall: TP / (TP + FN) TP: IoU0.5的检测框数量(同一Ground Truth只计算一次) FP: IoU= 0, 0.1, 0.2, ..., 1共11个点时的Precision最大值,然后AP就是这11个Precision的平均值。 在VOC2010及以后,需要针对每一个不同的Recall值(包括0和1),选取其大于等于这些Recall值时的Precision最大值,然后计算PR曲线下面积作为AP值。 mAP计算示例 假...
Large Model
2026-01-11

概述 MTP(Multitoken Prediction)的总体思路是:让模型使用n个独立的输出头来预测接下来的n个token,这n个独立的输出头共享同一个模型主干。这样通过解码阶段的优化,将1token的生成,转变成multitoken的生成,从而提升训练和推理的性能。 在DeepSeek之前也有几个MTP方案,其侧重点各自不同。 侧重推理时解码加速。比如论文“MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads”、论文“EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty”等。这些方案通过一次生成多个...
Computer Vision
2026-01-11

NMS 过程: 1. 根据分类概率从小到大排序ABCDEF 1. 从最大概率F开始,F与A~E的IOU是否大于阈值 1. 大于的扔掉,从剩下的当中继续重复2~3 [代码] SoftNMS NMS算法保留score最高的预测框,并将与当前预测框重叠较多的proposals视作冗余,显然,在实际的检测任务中,这种思路有明显的缺点,比如对于稠密物体检测,当同类的两个目标距离较近时,如果使用原生的nms,就会导致其中一个目标不能被召回,为了提高这种情况下目标检测的召回率,SoftNMS应运而生。对于FasterRCNN在MSCOCO数据集上的结果,将NMS改成SoftNMS,mAP提升了1.1%。 它认为重叠较多的proposals也有可能包含有效目标,只不过重叠区域越大可能性越小。参见下图,NMS...
NLP
2026-01-11
概述 HiPPO(Highorder Polynomial Projection Operators)是目前大热的structured state space model (S4)及其后续工作的backbone. State space mode主要是控制学科里的内容,最近被引入深度学习领域来解决长距离依赖问题。长距离依赖建模的核心问题是如何通过有限的memory来尽可能记住之前所有的历史信息。当前的主流序列建模模型(即Transformer和RNN) 存在着普遍的遗忘问题 fixedsize context windows: Transformer的window size通常是有限的,一般来说quadratic的attention最多建模到大约10k的token就到计算极限了 vanish...
Computer Vision
2026-01-11

Segment Anything Segment Anything(SA)项目:一个用于图像分割的新任务、新模型和新数据集 通过FM(基础模型)+prompt解决了CV中难度较大的分割任务,给计算机视觉实现基础模型+提示学习+指令学习提供了一种思路 关键:加大模型容量(构造海量的训练数据,或者构造合适的自监督任务来预训练) Segment Anything Task SAM的一部分灵感是来源于NLP中的基座模型(Foundation Model),Foundation Model是OpenAI提出的一个概念,它指的是在超大量数据集上预训练过的大模型(如GPT系列、BERT),这些模型具有非常强大的 zeroshot 和 fewshot能力,结合prompt engineering和fine ...
Large Model
2026-01-11

概述 投机解码(Speculative Decoding)也叫预测解码/投机采样,它会利用小模型来预测大型模型的行为,从而提升模型在解码(decoding)阶段的解码效率问题,加速大型模型的执行。其核心思路如下图所示,首先以低成本的方式(以小模型为主,也有多头,检索,Early Exit 等方式)快速生成多个候选 Token(串行序列、树、多头树等),然后通过一次并行验证阶段快速验证多个 Token的正确性,只要平均每个 Step 验证的 Token 数 1,就可以一次性生成多个token,进而减少总的 Decoding 步数,实现加速的目的。 下图左侧是自回归解码模型,右侧是投机解码机制。 从本质上来说,投机解码希望在推理阶段在不大幅度改变模型的情况下,通过更好利用冗余算力来并行"投机"地...
Computer Vision
2026-01-11

上图是Yolo v4中,对各种detector部件的总结:包含Input、backbone、neck、head、... Backbone Neck 例如:SPP 、 ASPP 、 RFB、 SAM 用来增加感受野 特征融合,主要是指不同输出层直接的特征融合,主要包括FPN、PAN、SFAM、ASFF和BiFPN。 结构 One stage TwoStage Anchor Free Transformer Problems
Computer Vision
2026-01-11
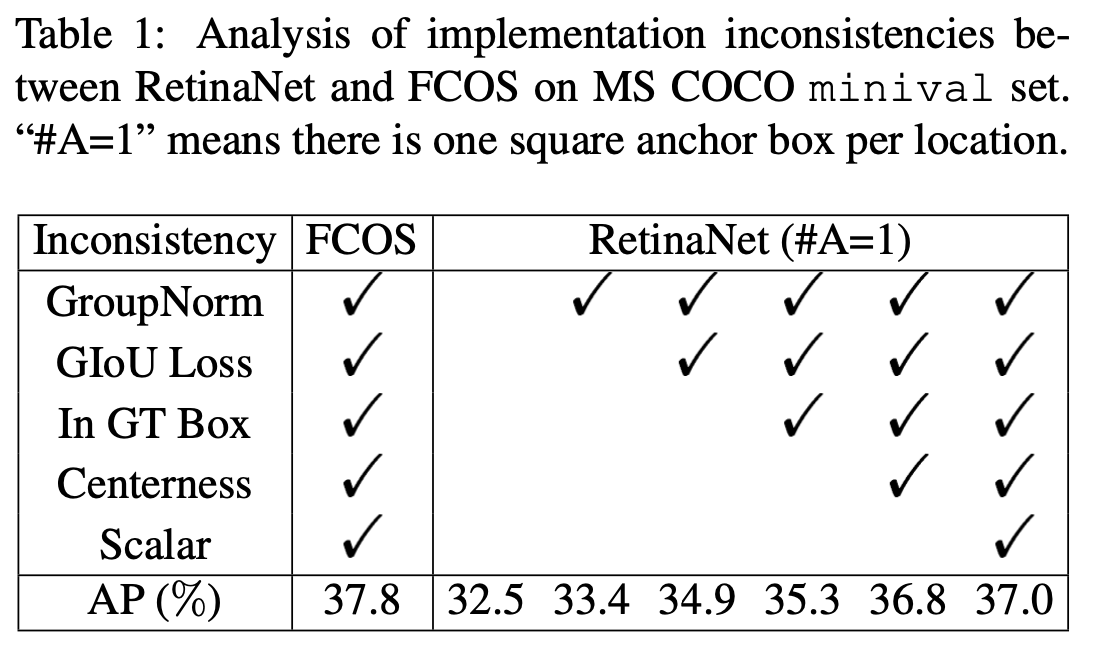
Introduction 由于FPN和Focal loss 的加入,anchorfree模型变得越来越多。在仔细比对了anchorbased和anchorfree目标检测方法后,结合实验结果,论文认为两者的性能差异主要来源于正负样本的定义,假如训练过程中使用相同的正负样本,两者的最终性能将会相差无几。 作者将目前的Anchorfree分为两个大类: 1. keypointbased methods:以CornerNet和ExtremeNet为代表,首先定位几个预定义或自学习的关键点,然后限制物体的空间范围; 1. centerbased methods:以FCOS和Foveabox为代表,使用物体的中心点或区域定义基准点,然后预测从该点到物体边界的四个距离。 为此,论文提出ATSS( Ada...
Computer Vision
2026-01-11
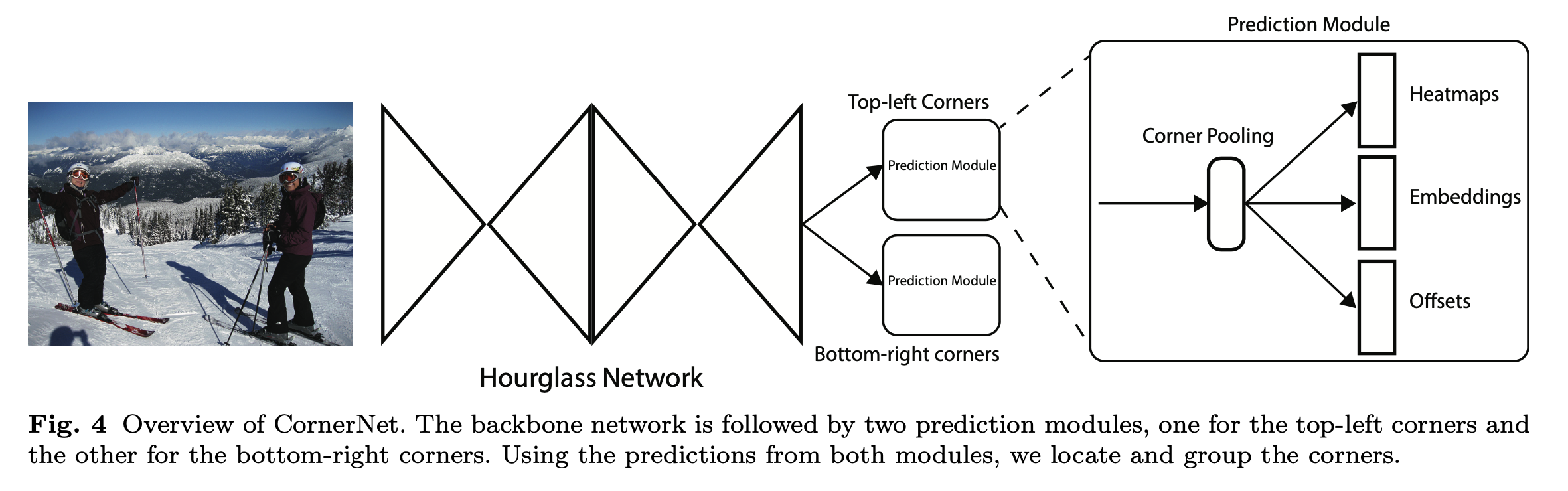
简介 CornerNet是密歇根大学Hei Law等人在发表ECCV2018的一篇论文,作者总结目前anchorbased方法存在两个缺点: 1. 提取的anchor boxes数量较多,比如DSSD使用40k, RetinaNet使用100k,anchor boxes众多造成anchor boxes正负样本的不均衡; 1. anchor boxes需要调整很多超参数,比如anchor boxes数量、尺寸、比率,影响模型的训练和推断速率。 作者的思路其实来源于一篇多人姿态估计的论文"Endtoend learning for joint detection and grouping"。基于CNN的2D多人姿态估计方法,通常有2个思路(BottomUp Approaches和TopDown ...
Computer Vision
2026-01-11

Motivation 我们知道object detection的算法主要可以分为两大类:twostage detector和onestage detector。前者是指类似Faster RCNN,RFCN这样需要region proposal的检测算法,这类算法可以达到很高的准确率,但是速度较慢。虽然可以通过减少proposal的数量或降低输入图像的分辨率等方式达到提速,但是速度并没有质的提升。后者是指类似YOLO,SSD这样不需要region proposal,直接回归的检测算法,这类算法速度很快,但是准确率不如前者。作者提出focal loss的出发点也是希望onestage detector可以达到twostage detector的准确率,同时不影响原有的速度。 既然有了出发点,那么...