PyTorch中,所有神经网络的核心是 autograd 包。 autograd 包为张量上的所有操作提供了自动求导机制。它是一个在运行时定义(definebyrun)的框架,这意味着反向传播是根据代码如何运行来决定的,并且每次迭代可以是不同的. 让我们用一些简单的例子来看看吧。 张量 torch.Tensor 是这个包的核心类。如果设置它的属性 .requires_grad 为 True,那么它将会追踪对于该张量的所有操作。当完成计算后可以通过调用 .backward(),来自动计算所有的梯度。这个张量的所有梯度将会自动累加到.grad属性. 要阻止一个张量被跟踪历史,可以调用 .detach() 方法将其与计算历史分离,并阻止它未来的计算记录被跟踪。 为了防止跟踪历史记录(和使用内存),...
Python
2026-01-11

相同点 nn.Xxx和nn.functional.xxx的实际功能是相同的,即nn.Conv2d和nn.functional.conv2d 都是进行卷积,nn.Dropout 和nn.functional.dropout都是进行dropout,。。。。。; 运行效率也是近乎相同。 nn.functional.xxx是函数接口,而nn.Xxx是nn.functional.xxx的类封装,并且nn.Xxx都继承于一个共同祖先nn.Module。这一点导致nn.Xxx除了具有nn.functional.xxx功能之外,内部附带了nn.Module相关的属性和方法,例如train(), eval(),load_state_dict, state_dict 等。 不同点 两者的调用方式不同。 nn.X...

论文地址: 🔖 https://arxiv.org/pdf/2107.11291 代码地址: 前言 一般来说,我们可以把姿态估计任务分成两个流派:Heatmapbased和Regressionbased。 其主要区别在于监督信息的不同,Heatmapbased方法监督模型学习的是高斯概率分布图,即把GroundTruth中每个点渲染成一张高斯热图,最后网络输出为K张特征图对应K个关键点,然后通过argmax或softargmax来获取最大值点作为估计结果。这种方法由于需要渲染高斯热图,且由于热图中的最值点直接对应了结果,不可避免地需要维持一个相对高分辨率的热图(常见的是64x64,再小的话误差下界过大会造成严重的精度损失),因此也就自然而然导致了很大的计算量和内存开销。 Regression...
Generative Model
2026-01-11

🔖 https://stability.ai/news/stablediffusion3researchpaper 概述 SD3 模型与训练策略改进细节 SD3除了将去噪网络从 UNet 改成 DiT 外,SD3 还在模型结构与训练策略上做了很多小改进: 改变训练时噪声采样方法 将一维位置编码改成二维位置编码 提升 VAE 隐空间通道数 对注意力 QK 做归一化以确保高分辨率下训练稳定 本文会简单介绍这些改进。 论文阅读 核心贡献 介绍 Stable Diffusion 3 (SD3) 的文章标题为 Scaling Rectified Flow Transformers for HighResolution Image Synthesis。与其说它是一篇技术报告,更不如说它是一篇论文,因为它...
3D Model
2026-01-11
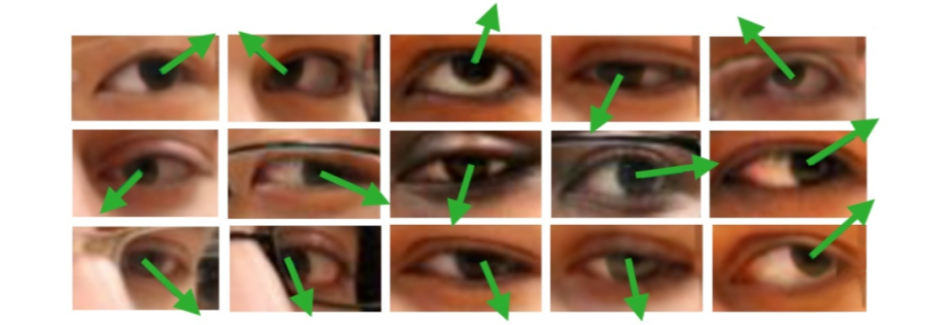
概述 问题定义 广义的 Gaze Estimation 泛指与眼球、眼动、视线等相关的研究,因此有不少做 saliency 和 egocentric 的论文也以 gaze 为关键词。而本文介绍的 Gaze Estimation 主要以眼睛图像或人脸图像为处理对象,估算人的视线方向或注视点位置, 如下图所示。 gaze角度的表示一般使用一个3d向量作为表示,也可以转换为pitch 和yaw角度,具体可参考 Model Gaze模型一般使用回归模型,所以这里基本只介绍一些在gaze model中使用的小技巧 Rle Loss 实际问题
Python
2026-01-11

unsupported operation: more than one element of the writtento tensor refers to a single memory location. Please clone() the tensor before performing the operation. 出现这种情况可能是在.backward()之前使用了 .expand()或者.expand_as()函数。具体原因可以看看这个老哥的提问:link 解决办法:在 .expand()或者.expand_as()函数后面添加.clone()就可以解决。