计算几何(Computational Geometry),是一系列使用计算机解决几何问题的算法。与解析几何相比,计算几何更适合计算机运算,精度较高,运算速度较快,并且易于编写。 浮点误差 程序设计中,考虑到浮点数 double 有精度误差,在比较时,通常允许一定的误差,即对于两个数 a 、 b ,如果 [Math] ,则认为 a=b 。一般根据题目要求, d (代码中命名为 EPS)取一个较小值,如 10^{8} 。 [代码] 向量 向量(vector)是一个有大小和方向的量,在几何中,它被表示为带箭头的线段。向量可以用起点和终点的坐标来表示 —— 从点 A到点B 的向量表示为 [Math] 。 向量的书写,两个大写字母上加一个箭头(表示方向) [Math] 向量没有位置,即向量可以在平面内...
Generative Model
2026-01-11

ControlNet应该算是2023年文生图领域最重要的工作,它让文生图模型Stable Diffusion实现了文本之外的可控生成,让AI绘画实现了质的飞跃。这篇文章我们将简单总结一下ControlNet技术细节。 模型设计 ControlNet的模型结构如下所示,这里是直接复制一份SD的上半部分:Encoder和中间的Middle Block。 ControlNet的输入和原始的SD一样,包括noisy latents、time embedding以及text embedding。除此之外,ControlNet还需要引入额外的condition,这个condition是和原图一样大小的图像,比如canny边界图或者人体骨架图。这里并没有像SD那样采用VAE对condition进行编码,而...
Large Model
2026-01-11

UITARS 简介 UITARS(User Interface Task Automation and Reasoning System)是由字节跳动(ByteDance)研发的原生 GUI 智能体模型: 输入方式:仅使用屏幕截图作为视觉输入 交互方式:执行类人操作(键盘输入、鼠标点击、拖拽等) 模型特性:端到端的原生智能体模型,无需复杂的中间件或框架 传统 GUI 智能体的开发往往依赖于文本信息,例如 HTML 结构和可访问性树。虽然这些方法取得了一些进展,但它们也存在一些局限性: 平台不一致性:不同平台的 GUI 结构差异很大,导致智能体难以跨平台通用。 信息冗余:文本信息往往过于冗长,增加了模型的处理负担。 访问限制:获取系统底层的文本信息通常需要较高的权限,限制了应用的范围。 模块化...
Generative Model
2026-01-11

💡 随机微分 在DDPM中,扩散过程被划分为了固定的T步,还是用DDPM中的类比来说,就是“拆楼”和“建楼”都被事先划分为了T步,这个划分有着相当大的人为性。事实上,真实的“拆”、“建”过程应该是没有刻意划分的步骤的,我们可以将它们理解为一个在时间上连续的变换过程,可以用随机微分方程(Stochastic Differential Equation,SDE)来描述。 为此,我们用下述SDE描述前向过程(“拆楼”): [公式] 相信很多读者都对SDE很陌生,笔者也只是在硕士阶段刚好接触过一段时间,略懂皮毛。不过不懂不要紧,我们只需要将它看成是下述离散形式在 [Math] 时的极限: [公式] 再直白一点,如果假设拆楼需要1天,那么拆楼就是 [Math] 从 t=0 到 t=1 的变化过程,每一...
Generative Model
2026-01-11

🔖 https://stability.ai/news/stablediffusion3researchpaper 概述 SD3 模型与训练策略改进细节 SD3除了将去噪网络从 UNet 改成 DiT 外,SD3 还在模型结构与训练策略上做了很多小改进: 改变训练时噪声采样方法 将一维位置编码改成二维位置编码 提升 VAE 隐空间通道数 对注意力 QK 做归一化以确保高分辨率下训练稳定 本文会简单介绍这些改进。 论文阅读 核心贡献 介绍 Stable Diffusion 3 (SD3) 的文章标题为 Scaling Rectified Flow Transformers for HighResolution Image Synthesis。与其说它是一篇技术报告,更不如说它是一篇论文,因为它...
Large Model
2026-01-11

通常我们训练神经网络模型的时候默认使用的数据类型为单精度FP32。近年来,为了加快训练时间、减少网络训练时候所占用的内存,并且保存训练出来的模型精度持平的条件下,业界提出越来越多的混合精度训练的方法。这里的混合精度训练是指在训练的过程中,同时使用单精度(FP32)和半精度(FP16)。 浮点数据类型 浮点数据类型主要分为双精度(FP64)、单精度(FP32)、半精度(FP16)。在神经网络模型的训练过程中,一般默认采用单精度(FP32)浮点数据类型,来表示网络模型权重和其他参数。在了解混合精度训练之前,这里简单了解浮点数据类型。 根据IEEE二进制浮点数算术标准(IEEE 754)的定义,浮点数据类型分为双精度(FP64)、单精度(FP32)、半精度(FP16)三种,其中每一种都有三个不同的...
Algorithm
2026-01-11
题目 给定一个无序的数组,找出数组在排序之后,相邻元素之间最大的差值。 如果数组元素个数小于 2,则返回 0。 Example 1: [代码] 解题思路:如果进行排序,这里会超时。采用桶排序 排序算法 的思想,可以在线性时间解决。 1. 首先建立桶,每个桶中只需要存放这个桶中元素的最大值和最小值。 1. 我们期望将数组中的各个数等距离分配,也就是每个桶的长度相同,也就是对于所有桶来说,桶内最大值减去桶内最小值都是一样的。可以当成公式来记。 1. 确定桶的数量,最后的加一保证了数组的最大值也能分到一个桶。为什么需要这样规定桶的尺寸呢?因为这样可以让最大的间距的两个元素在两个不同的桶中。可以证明一下,因为我们用元素范围之差除以元素个数,所以桶的尺寸就是平均的元素间距,显然最大间距的两个元素不可能...
Algorithm
2026-01-11

1. 可以重复选取 给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。 candidates 中的数字可以无限制重复被选取。 画出树状搜索图如下, 为了去除重复的情况, 我们需要按照某种顺序搜索,具体做法是:每一次搜索的时候,设置下一轮搜索的起点 [代码] 2. 不能被重复选取 与上面的区别在于 1. index每次不要重复搜索,而是去寻找下一个 1. 排除重复的元素 [代码]
Large Model
2026-01-11

概述 Medusa 是自投机领域较早的一篇工作,对后续工作启发很大,其主要思想是 multidecoding head + tree attention + typical acceptance(threshold)。Medusa 没有使用独立的草稿模型,而是在原始模型的基础上增加多个解码头(MEDUSA heads),并行预测多个后续 token。 正常的LLM只有一个用于预测 t 时刻token的head。Medusa 在 LLM 的最后一个 Transformer层之后保留原始的 LM Head,然后额外增加多个(假设是 k 个) 可训练的Medusa Head(解码头),分别负责预测 ...
Large Model
2026-01-11

概述 MTP(Multitoken Prediction)的总体思路是:让模型使用n个独立的输出头来预测接下来的n个token,这n个独立的输出头共享同一个模型主干。这样通过解码阶段的优化,将1token的生成,转变成multitoken的生成,从而提升训练和推理的性能。 在DeepSeek之前也有几个MTP方案,其侧重点各自不同。 侧重推理时解码加速。比如论文“MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads”、论文“EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty”等。这些方案通过一次生成多个...
01背包 描述 有N件物品和一个容量为V的背包。 第i件物品的体积是vi,价值是wi。 求解将哪些物品装入背包,可使这些物品的总体积不超过背包流量,且总价值最大。 二维动态规划 f[i][j] 表示只看前i个物品,总体积是j的情况下,总价值最大是多少。 result = max(f[n][0V]) f[i][j]: 不选第i个物品:f[i][j] = f[i1][j]; 选第i个物品:f[i][j] = f[i1][jv[i]] + w[i](v[i]是第i个物品的体积) 两者之间取最大。 初始化:f[0][0] = 0 代码如下: [代码] 一维动态优化 从上面二维的情况来看,f[i] 只与f[i1]相关,因此只用使用一个一维数组[0v]来存储前一个状态。那么如何来实现呢? 第一个问题:状...
Algorithm
2026-01-11
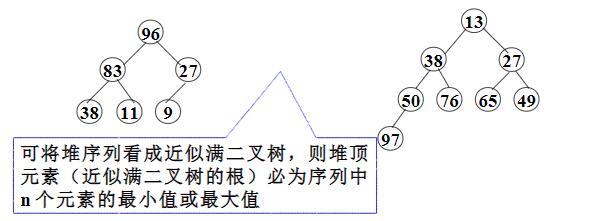
起步 heapq 模块实现了适用于Python列表的最小堆排序算法。 堆是一个树状的数据结构,其中的子节点都与父母排序顺序关系。因为堆排序中的树是满二叉树,因此可以用列表来表示树的结构,使得元素 N 的子元素位于 2N + 1 和 2N + 2 的位置(对于从零开始的索引)。 本文内容将分为三个部分,第一个部分简单介绍 heapq 模块的使用;第二部分回顾堆排序算法;第三部分分析heapq中的实现。 heapq 的使用 创建堆有两个基本的方法:heappush() 和 heapify(),取出堆顶元素用 heappop()。 heappush() 是用来向已有的堆中添加元素,一般从空列表开始构建: [代码] 如果数据已经在列表中,则使用 heapify() 进行重排: [代码] 回顾堆排序算...